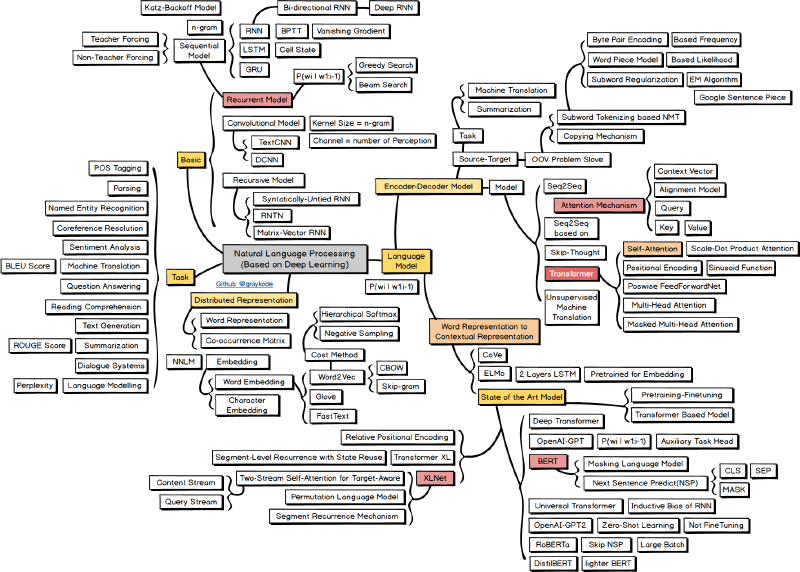
导语
期末全是开放问题,因此弄清楚各种模型的优劣非常有必要。
笔记
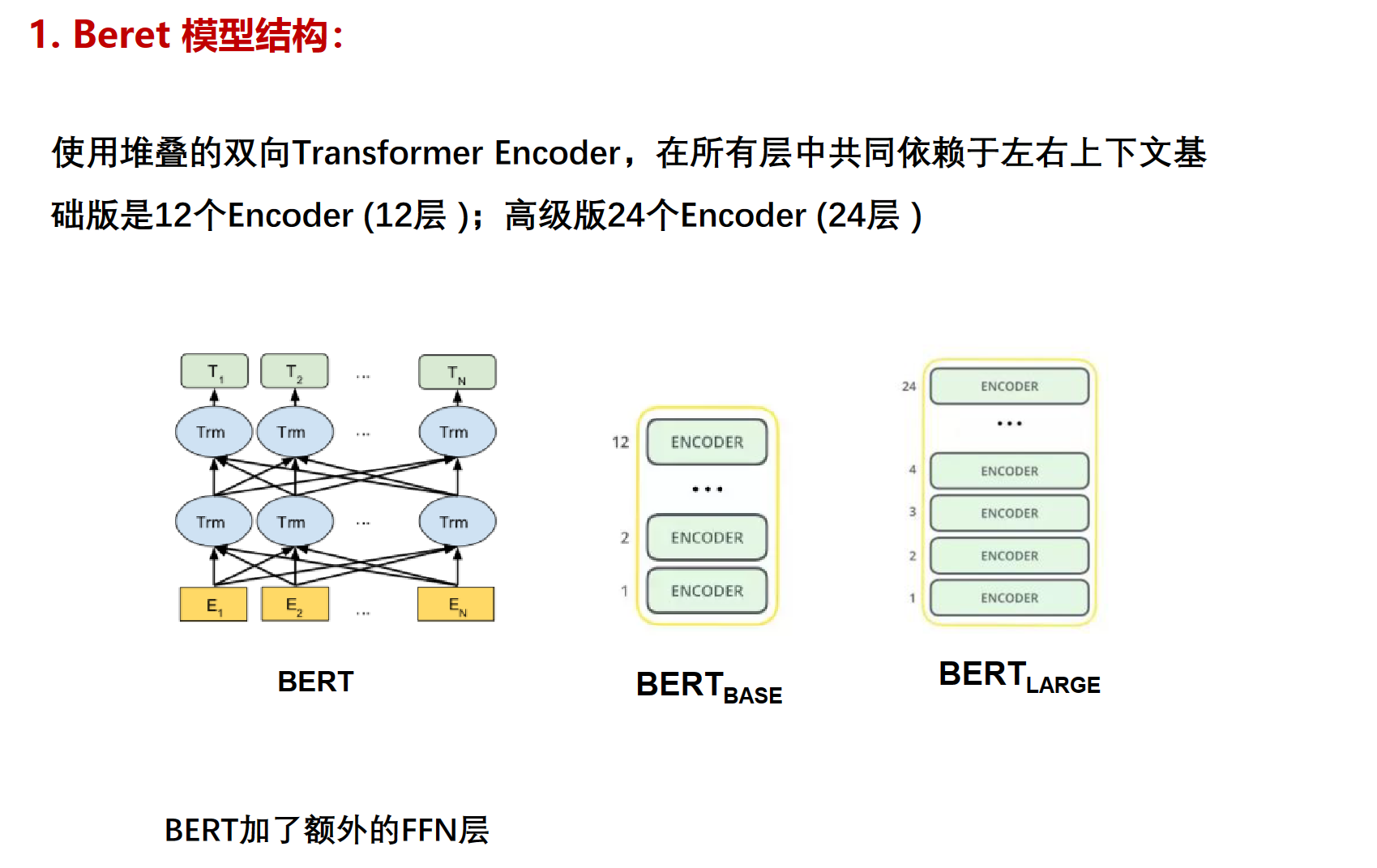
model
常见的模型有DNN、CNN、RNN、GNN、LSTM、
task
NLP的经典问题有
在课程中,我们主要学习了
属性抽取(AE)
opinion target和aspect的区别:opinion target是被评价对象,aspect是对象的属性
eg"这个手机的摄像头很出色,但电池寿命较短。“手机是opinion target,而摄像头和电池寿命是手机的两个aspect。
目标:抽取对象。eg:华为技术遥遥领先!-> 抽取出“华为”
Aspect Term Extraction 论文阅读(一) - 知乎 (zhihu.com)
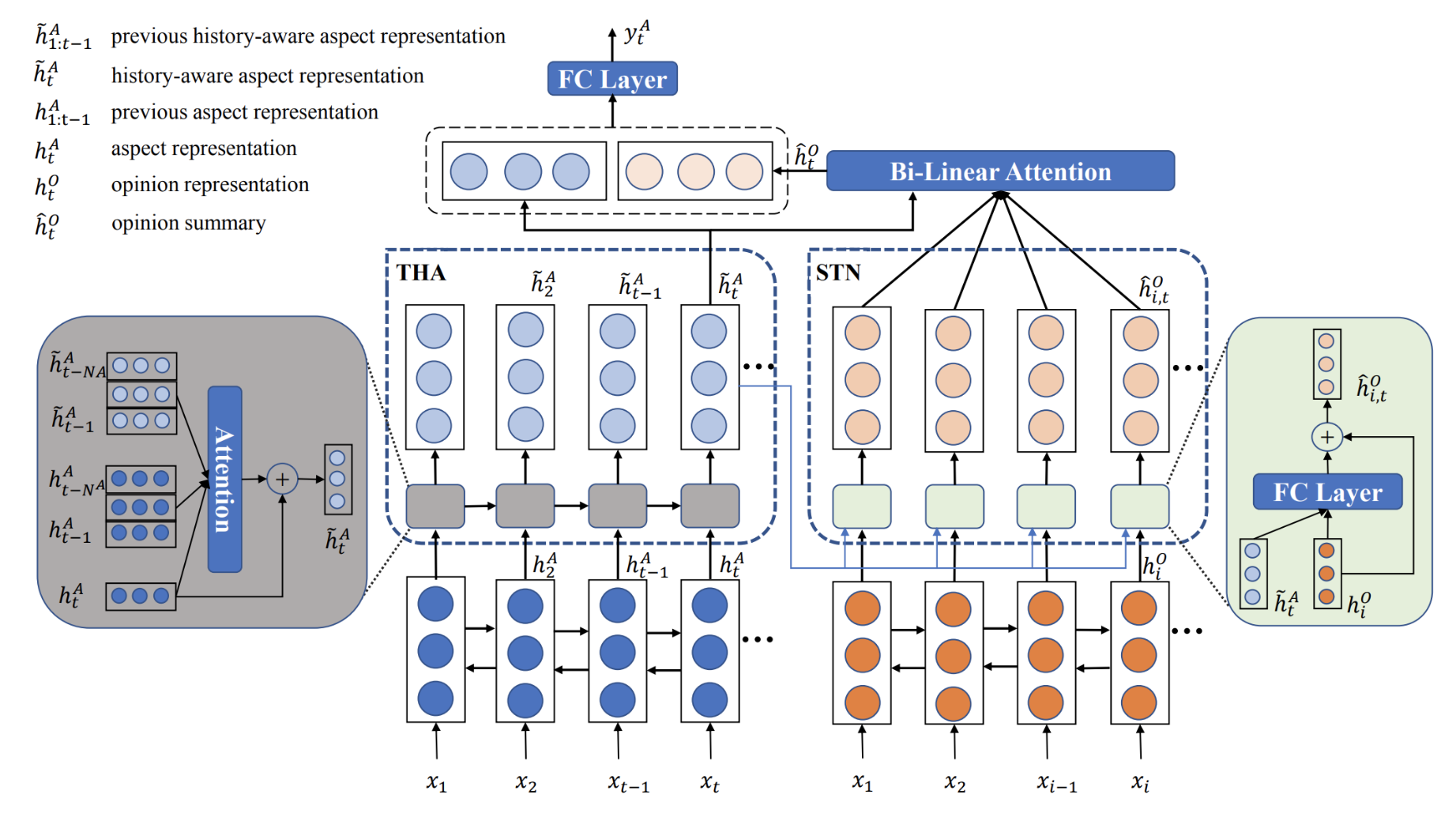
THA是用了attention机制的LSTM,用于获得上文(单向)已经标注过的aspect的信息,来指导当前aspect标注。
STN是LSTM,用于获得opinion的摘要信息。首先,STN单元获得基于给定aspect的opinion的表示,接下来利用attention机制来获得基于全局的opinion的表示。自此就可以获得基于当前aspect的opinion摘要。将aspect的表示和opinion摘要拼接作为特征,用于标注。
(表示就是一个框里三个圆圆)
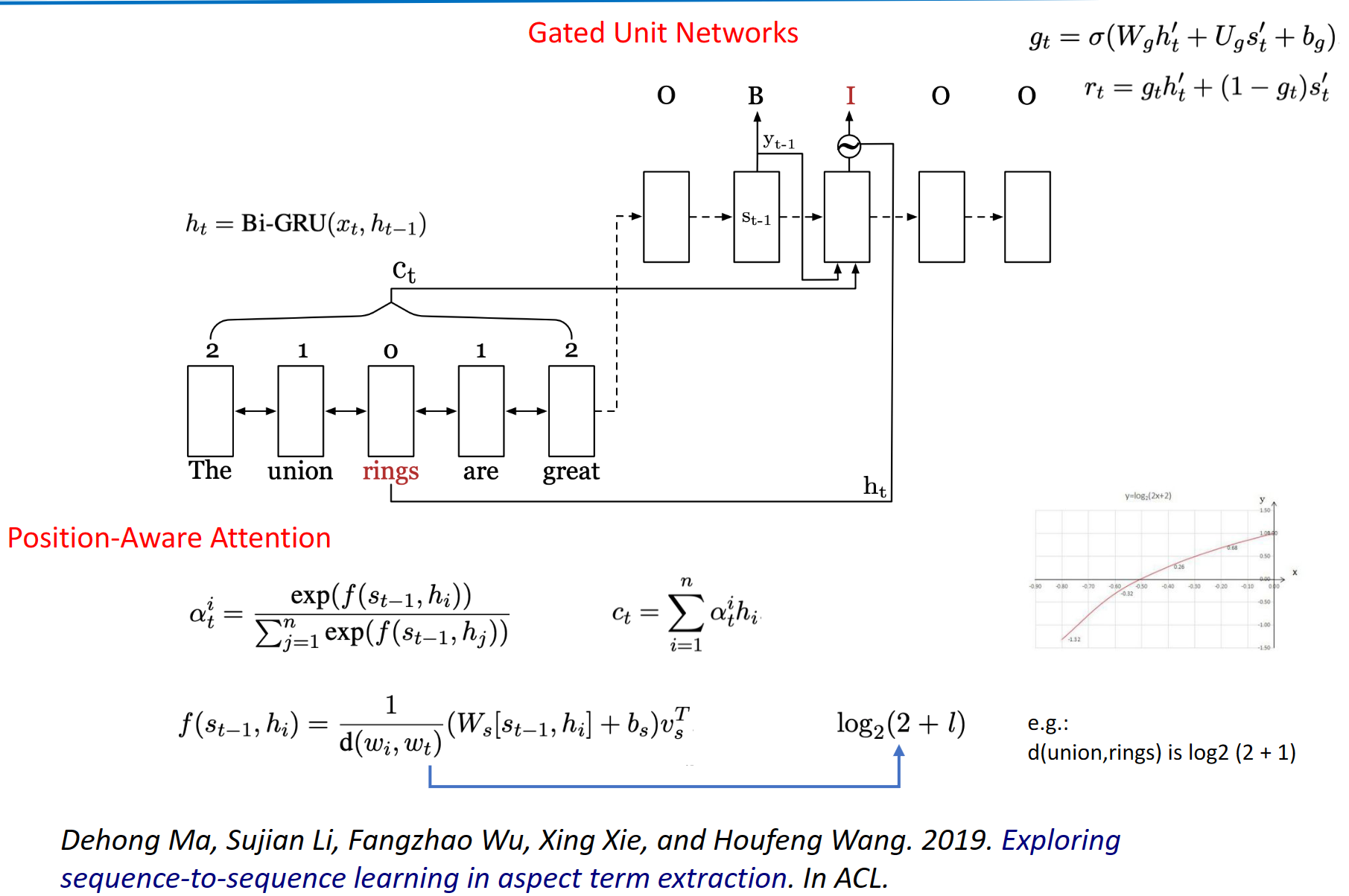
将ATE形式化为一个seq2seq的学习任务。在这个任务中,源序列和目标序列分别由单词和标签组成。为了使Seq2Seq学习更适合ATE,作者设计了门控单元网络和位置感知注意力机制。门控单元网络用于将相应的单词表示融入解码器,而位置感知注意力机制则用于更多地关注目标词的相邻词。
decoder包含一个门控单元,用于控制编码器和解码器产生的隐状态。当解码标签时,这个门控单元可以自动的整合来自编码器和解码器隐状态的信息。
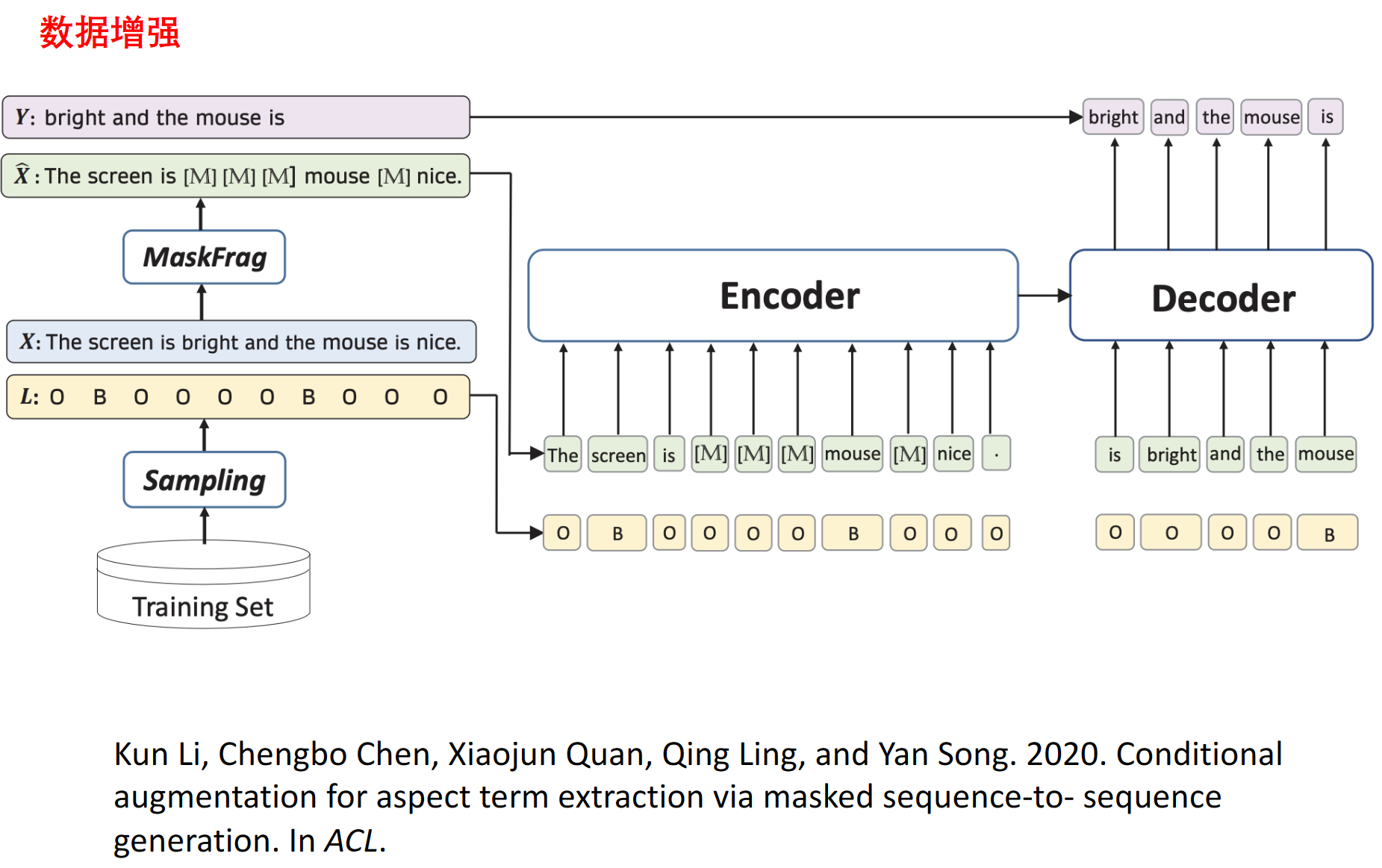
masked seq2seq。首先,对输入句子的连续几个词进行掩码处理。然后,encoder接收部分掩码的句子及其标签序列作为输入,decoder尝试根据编码上下文和标签信息重建句子原文。要求保持opinion target位置不变
观点抽取(OE)
一般都是先抽取aspect,在对aspect进行情感预测的流水线方式
IMN使用非流水线方式。与传统的多任务学习方法依赖于学习不同任务的共同特征不同,IMN引入了一种消息传递体系结构,通过一组共享的潜在变量将信息迭代地传递给不同的任务
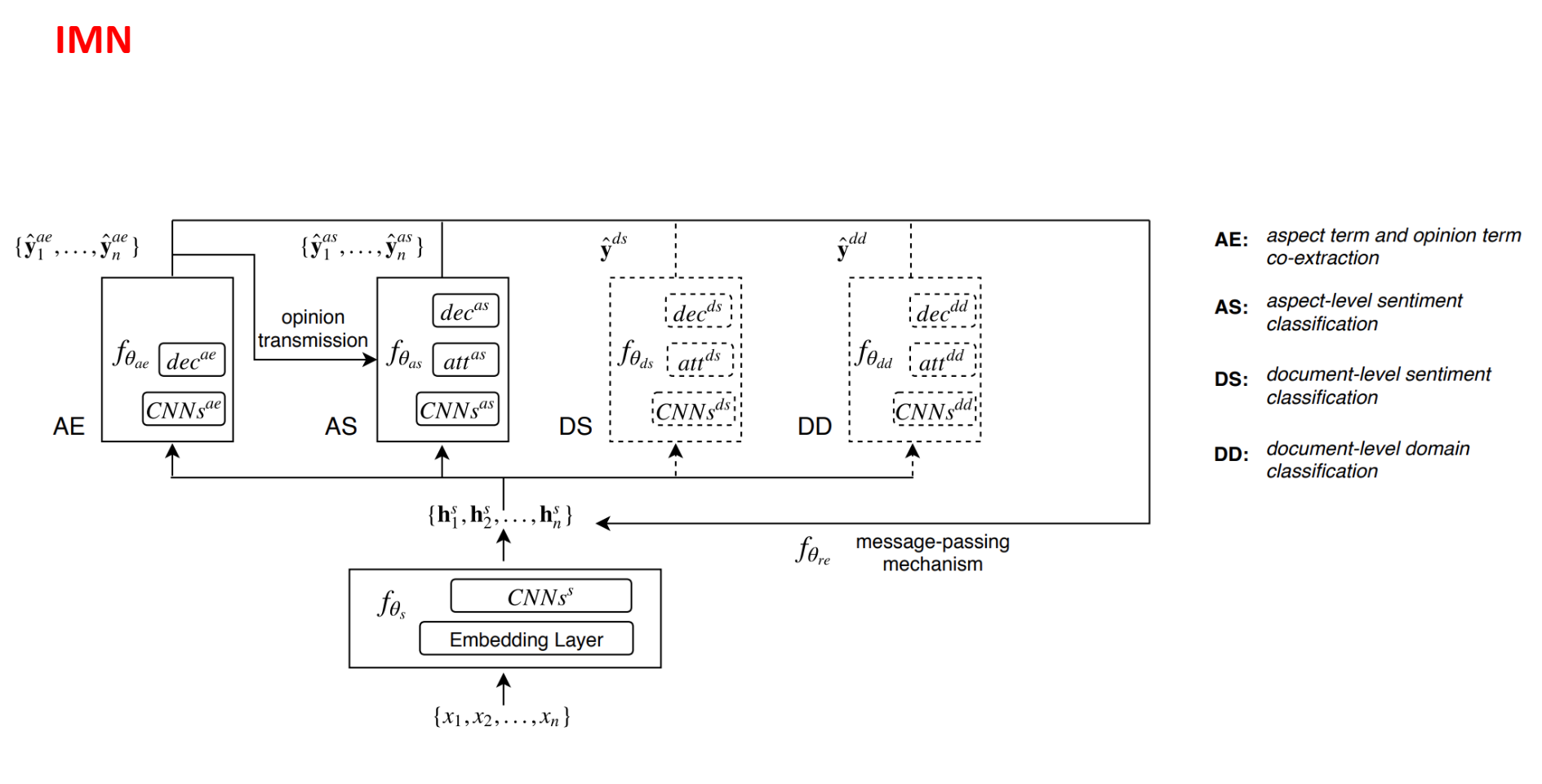
它接受一系列tokens{x1,…,xn}作为特征提取组件fθs的输入,该组件在所有任务之间共享。该组件由单词嵌入层和几个特征提取层(好多个CNN)组成。输出所有任务共享的潜在向量{hs1,hs2,…,hsn}的序列。该潜在向量序列会根据来自不同任务组件传播来的信息来更新。
$hi^{s(T)}$ 表示为t轮消息传递后Xi对应的共享潜在向量的值。
共享潜在向量序列用作不同任务特定组件的输入。每个特定于任务的组件都有自己的潜在变量和输出变量集。输出变量对应于序列标签任务中的标签序列;在AE中,我们为每个令牌分配一个标签,表明它是否属于任何aspect或opinion,而在AS中,我们为每个单词加上它的情感标签。在分类任务中,输出对应于输入实例的标签:情感分类任务(DS)的文档的情感,以及领域分类任务(DD)的文档域。在每次迭代中,适当的信息被传递回共享的潜在向量以进行组合;这可以是输出变量的值,也可以是潜在变量的值,具体取决于任务。 此外,我们还允许在每次迭代中在组件之间传递消息(opinion transmission)。
感觉有点训练词向量的感觉,像是预处理一下得到向量序列来方便其他任务。
【超,好像这些都不是考试重点】
属性级情感分类
For exam
试卷题型:简答题 40 分(5*8)好多个问号(内容为胡老师讲的基础部分)+ 综合题 60 分(内容为曹老师讲的核心应用部分)
简答题重点章节:
什么是语言模型、神经网络语言模型、几种、特点(优点)
概念性的简答题, 不难+
第4章 语言模型+词向量 (要求掌握:语言模型概念,神经网络语言模型 )
第 5章 NLP中的注意力机制 (全部要求掌握)概念、用处
第 7 章 预训练语言模型(全部要求掌握)[主要掌握GPT,BERT 是 怎么训练的,与下游任务是如何对接的]prompt,inconcert learning,思维链【建模的几种范式】
主观题重点章节: 设计东西
第9章 情感分析(要求掌握:方面级情感分析基本方法原理)
第10章 信息抽取 (要求掌握:实体和关系联合抽取基本方法原理)
第 11章 问答系统(要求掌握:检索式问答系统基本方法原理)
语言模型概念



神经网络语言模型
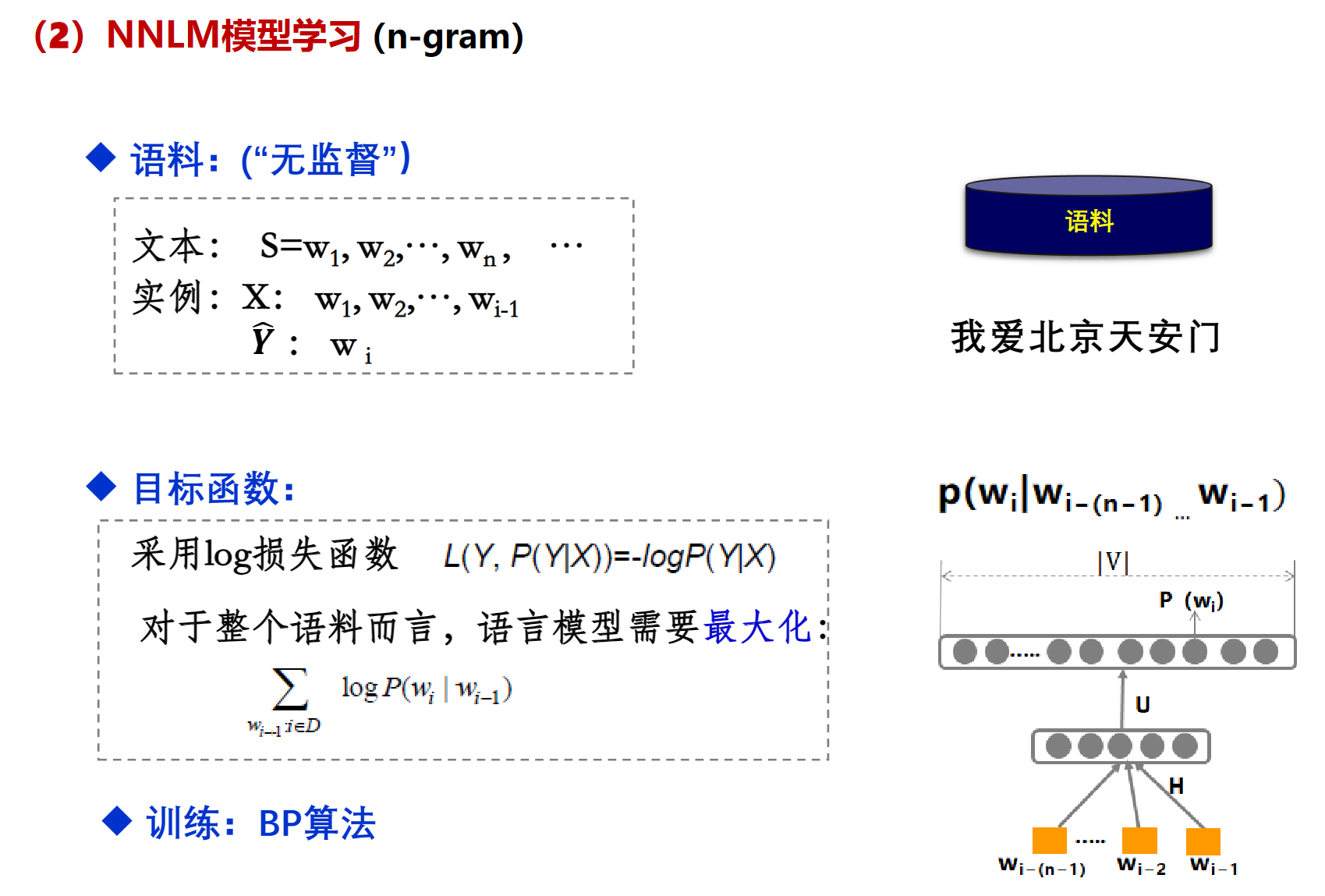
统计的方法使用最大似然估计,需要数据平滑否则会出现0概率问题。
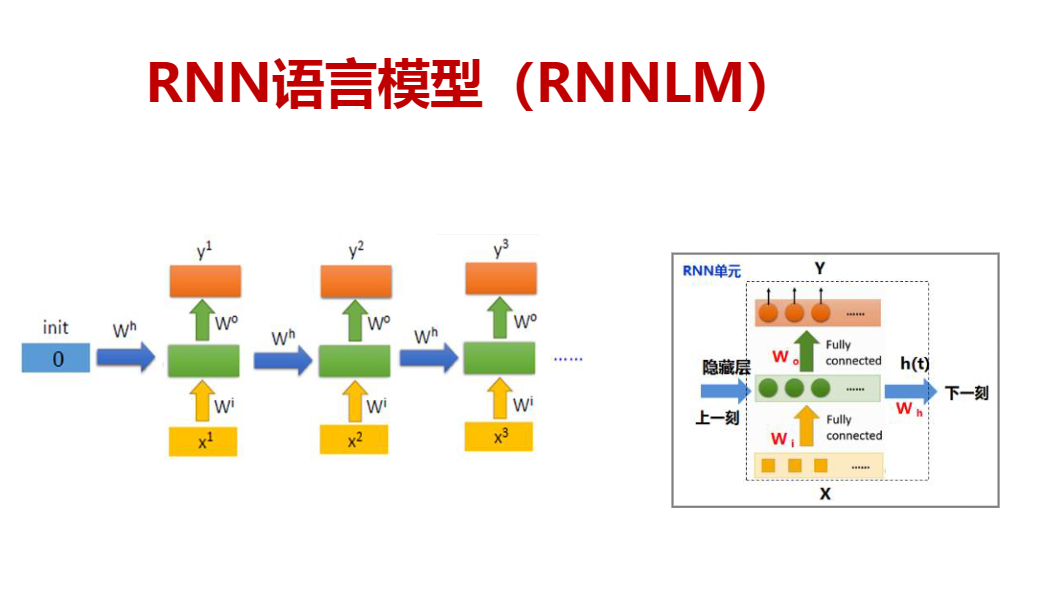
神经网络使用DNN和RNN
利用RNN 语言模型可以解决以上概率语言模型问题,在神经网络一般用RNN语言模型
一些(我不会的)背景知识
梯度下降算法
梯度下降法是一种常用的优化算法,主要用于找到函数的局部最小值。它的基本思想是:在每一步迭代过程中,选择函数在当前点的负梯度(即函数在该点下降最快的方向)作为搜索方向,然后按照一定的步长向该方向更新当前点,不断迭代,直到满足停止准则。
具体来说,假设我们要最小化一个可微函数$f(x)$,我们首先随机选择一个初始点$x_0$,然后按照以下规则更新$x$:
$$ x_{n+1} = x_n - \alpha \nabla f(x_n) $$其中,$\nabla f(x_n)$是函数$f$在点$x_n$处的梯度,$\alpha$是步长(也称为学习率),控制着每一步更新的幅度。
梯度下降法只能保证找到局部最小值
双曲正切函数
它解决了Sigmoid函数的不以0为中心输出问题,然而,梯度消失的问题和幂运算的问题仍然存在
$\tanh(x)=\frac{e^x-e^{-x}}{e^x+e^{-x}}$
BP算法
反向传播算法,当正向传播得到的结果和预期不符,则反向传播,修改权重
BPTT算法
是BP算法的拓展,可以处理具有时间序列结构的数据,用于训练RNN
BPTT的工作原理如下:
- 正向传播 :在每个时间步,网络会读取输入并计算输出。这个过程会持续进行,直到处理完所有的输入序列。
- 反向传播 :一旦完成所有的正向传播步骤,网络就会计算最后一个时间步的误差(即网络的预测与实际值之间的差距),然后将这个误差反向传播到前一个时间步。这个过程会持续进行,直到误差被传播回第一个时间步。
- 参数更新 :在误差反向传播的过程中,网络会计算误差关于每个参数的梯度。然后,这些梯度会被用来更新网络的参数。
one-hot编码
独热编码是一种将离散的分类标签转换为二进制向量的方法
假设我们要做一个分类任务,总共有3个类别,分别是猫、狗、人。那这三个类别就是一种离散的分类:它们之间互相独立,不存在谁比谁大、谁比谁先、谁比谁后的关系。
在神经网络中,需要一种数学的表示方法,来表示猫、狗、人的分类。最容易想到的,便是以 0 代表猫,以 1 代表狗,以 2 代表人这种简单粗暴的方式。但这样会导致分类标签之间出现了不对等的情况。(2比1大……)
而进行如下的编码的话就可以解决这个问题:
- 猫:[1, 0, 0]
- 狗:[0, 1, 0]
- 人:[0, 0, 1]
这就是独热码
pairwise
“Pairwise"是一种常用于排序和推荐系统的方法。它的主要思想是将排序问题转换为二元分类问题。每次取一对样本,预估这一对样本的先后顺序,不断重复预估一对对样本,从而得到某条查询下完整的排序。如果文档A的相关性高于文档B,则赋值+1,反之则赋值-1。这样,我们就得到了二元分类器训练所需的训练样本
Pairwise方法也有其缺点。例如,它只考虑了两篇文档的相对顺序,没有考虑他们出现在搜索结果列表中的位置。
除了Pairwise,还有其他的方法如Pointwise和Listwise。Pointwise方法每次仅仅考虑一个样本,预估的是每一条和查询的相关性,基于此进行排序。而Listwise方法则同时考虑多个样本,找到最优顺序。这些方法各有优缺点,选择哪种方法取决于具体的应用场景和需求。
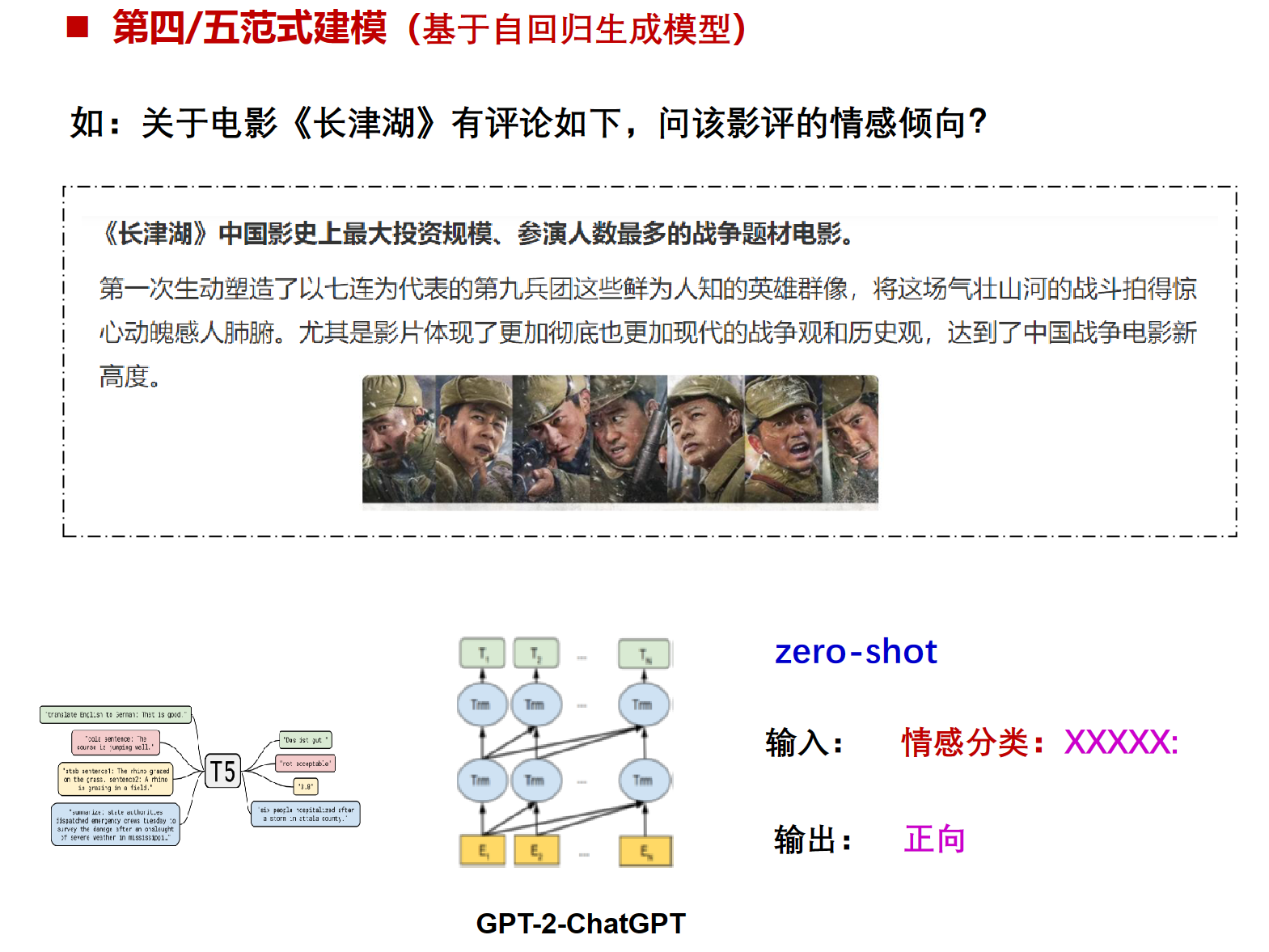
zero-shot
“Zero-shot learning”(零样本学习)是一种机器学习范式,它允许模型在没有先前训练过相关数据集的情况下,对不包含在训练数据中的类别或任务进行准确的预测或推断。这种能力是由先进的深度学习模型和迁移学习方法得以实现的。
举个例子,假设我们的模型已经能够识别马,老虎和熊猫了,现在需要该模型也识别斑马,那么我们需要告诉模型,怎样的对象才是斑马,但是并不能直接让模型看见斑马。所以模型需要知道的信息是马的样本、老虎的样本、熊猫的样本和样本的标签,以及关于前三种动物和斑马的描述。
这种方法的优点是可以极大地节省标注量。不需要增加样本,只需要增加描述即可。
PPO
PPO(Proximal Policy Optimization,近端策略优化)是一种强化学习算法,由OpenAI在2017年提出。PPO算法的目标是解决深度强化学习中策略优化的问题。
PPO算法的核心在于更新策略梯度,主流方法有两种,分别是KL散度做penalty,另一种是Clip剪裁,它们的主要作用都是限制策略梯度更新的幅度,从而推导出不同的神经网络参数更新方式。
PPO算法具备Policy Gradient、TRPO的部分优点,采样数据和使用随机梯度上升方法优化代替目标函数之间交替进行,虽然标准的策略梯度方法对每个数据样本执行一次梯度更新,但PPO提出新目标函数,可以实现小批量更新。
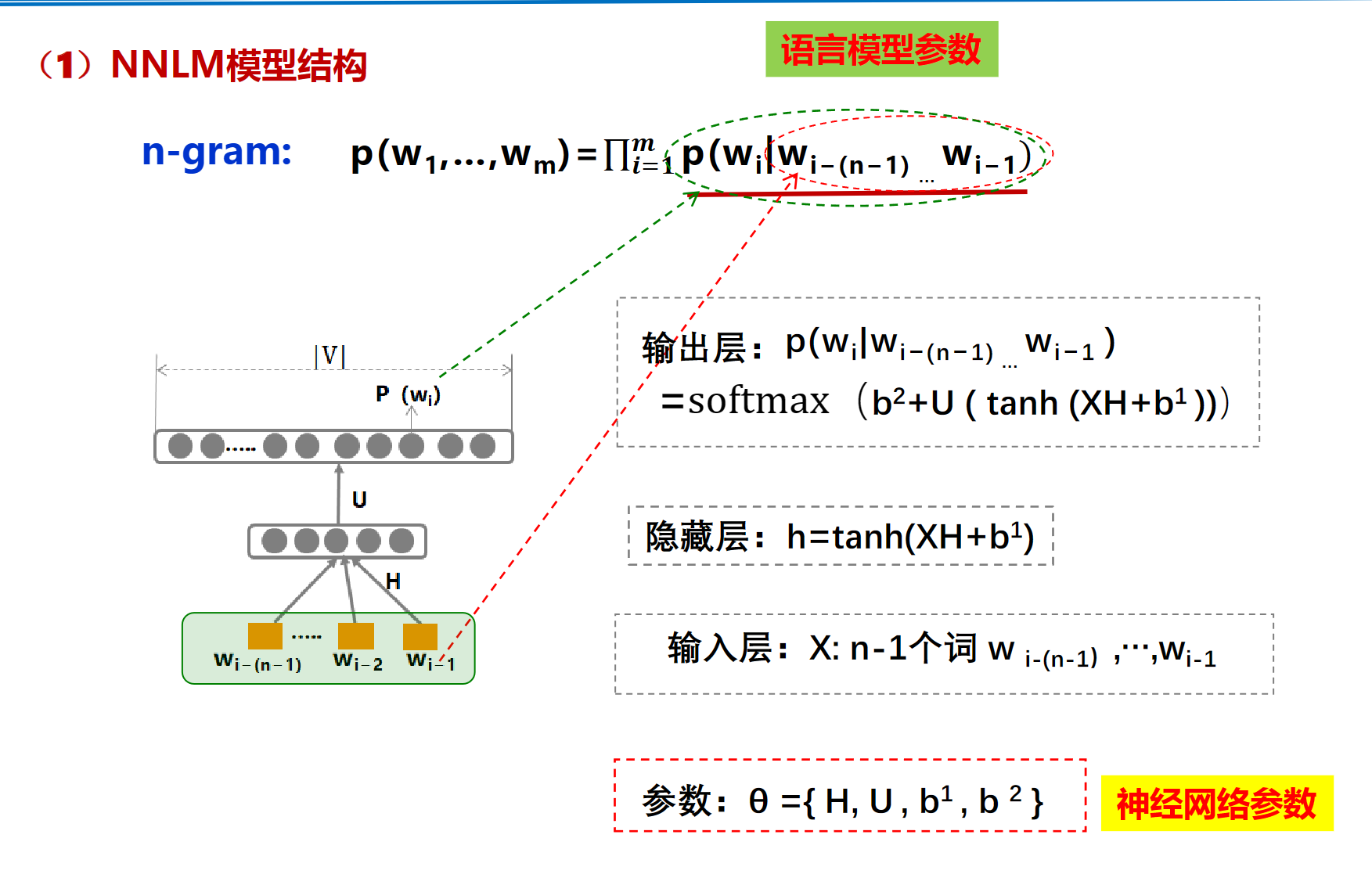
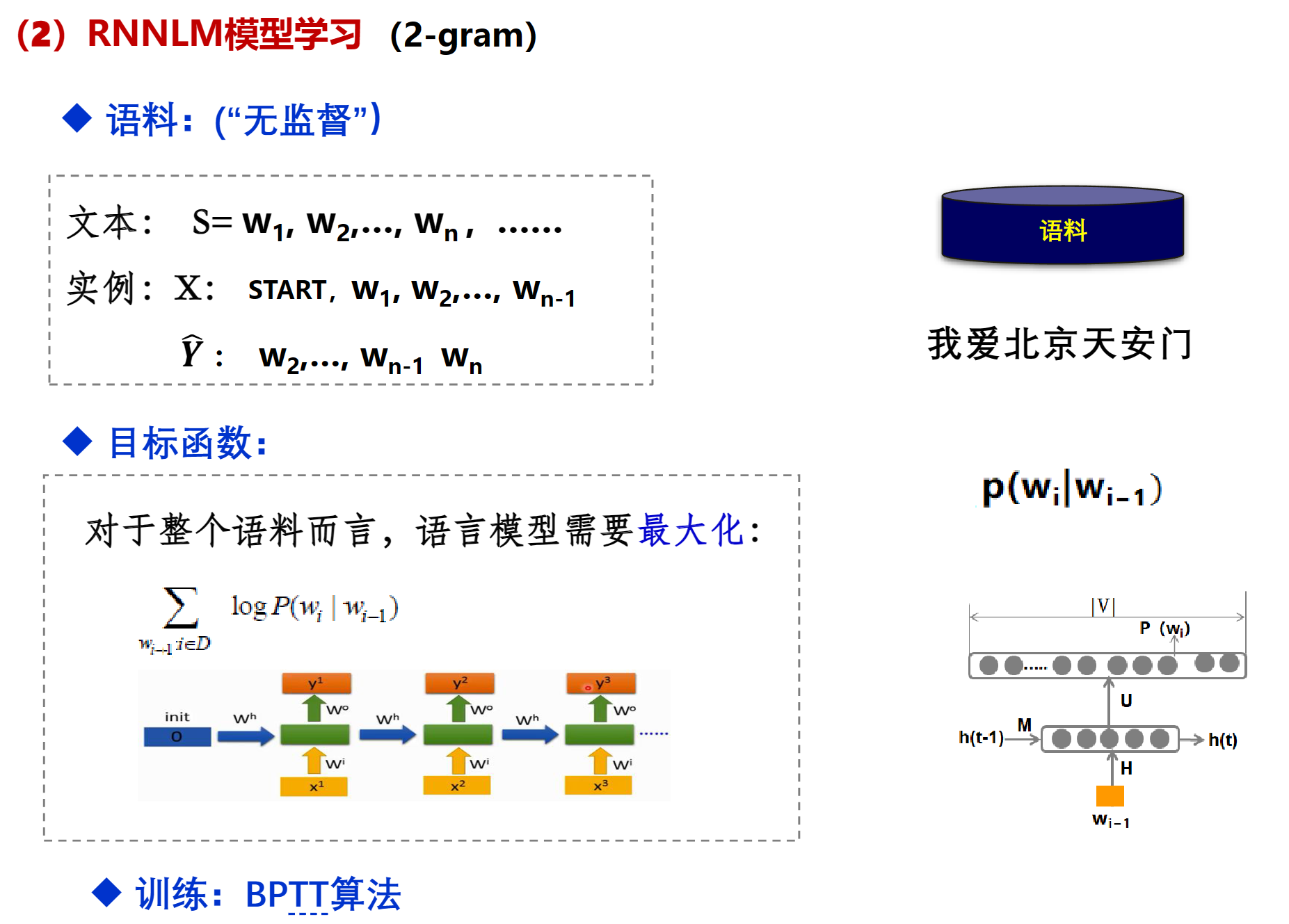
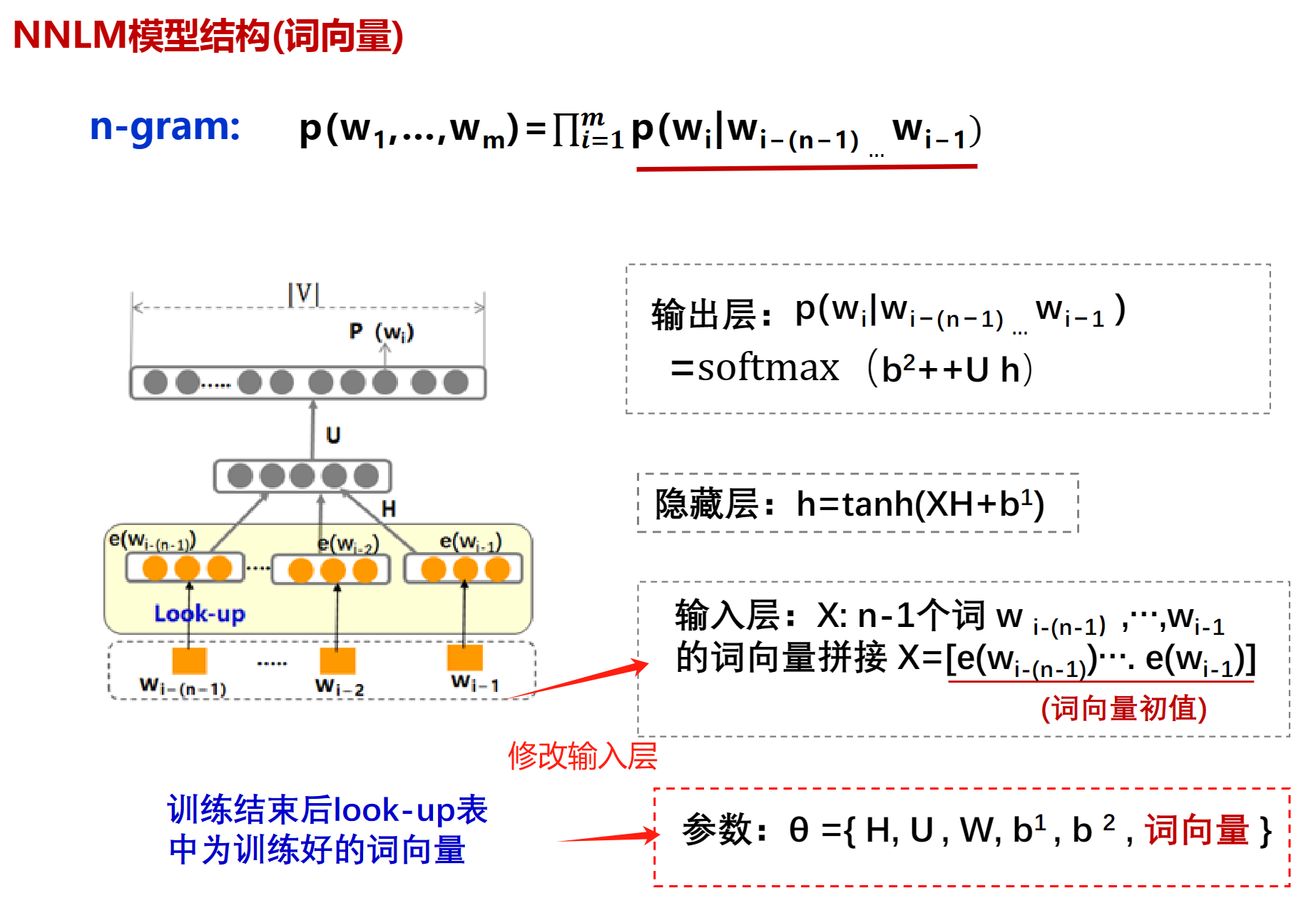
DNN(NNLM)
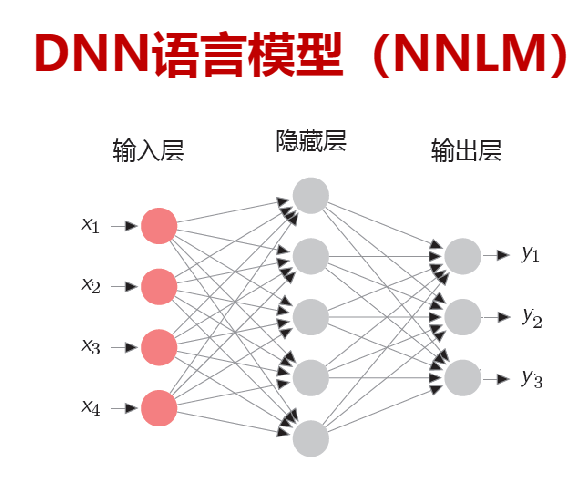
2-gram(bigram)
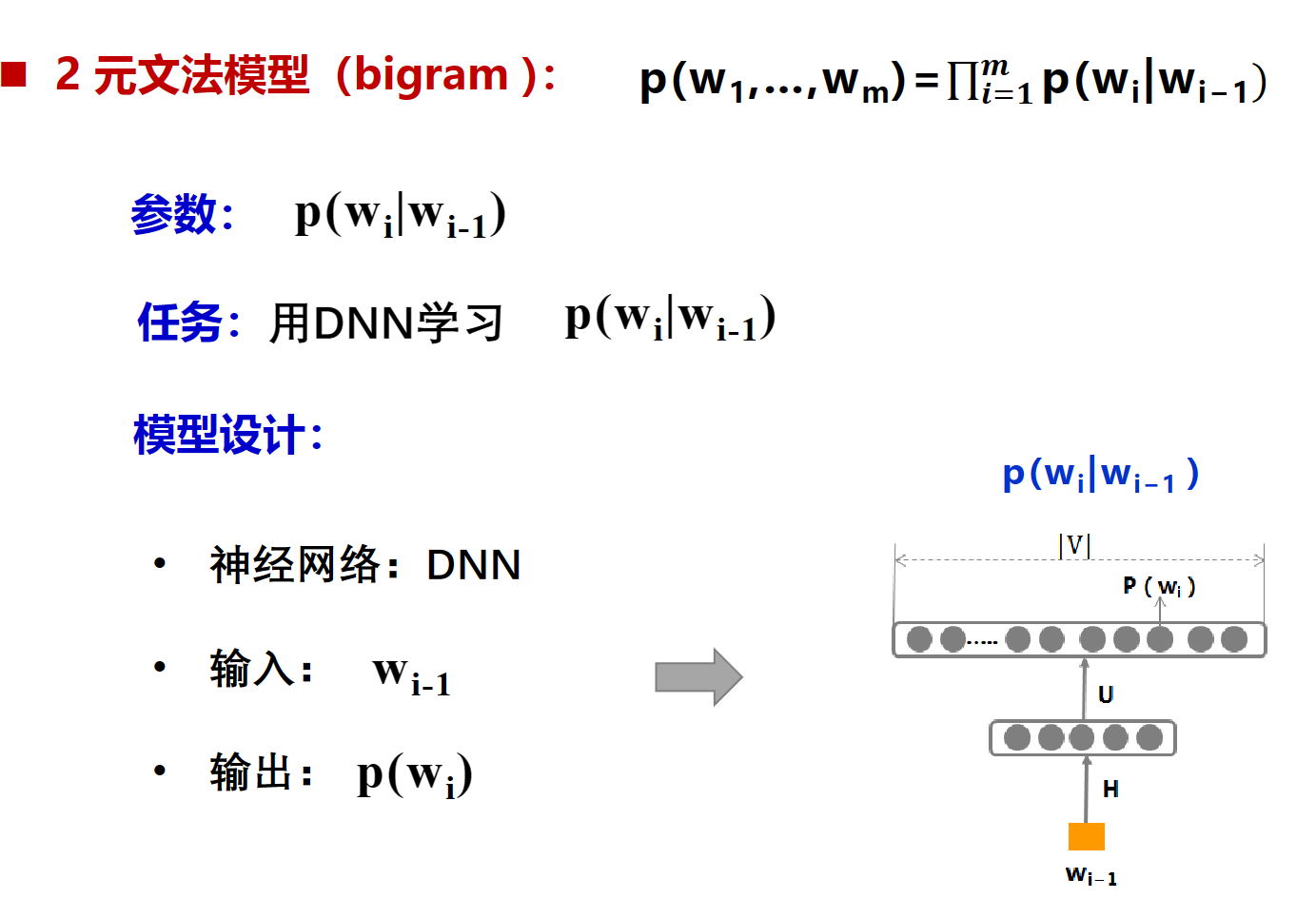
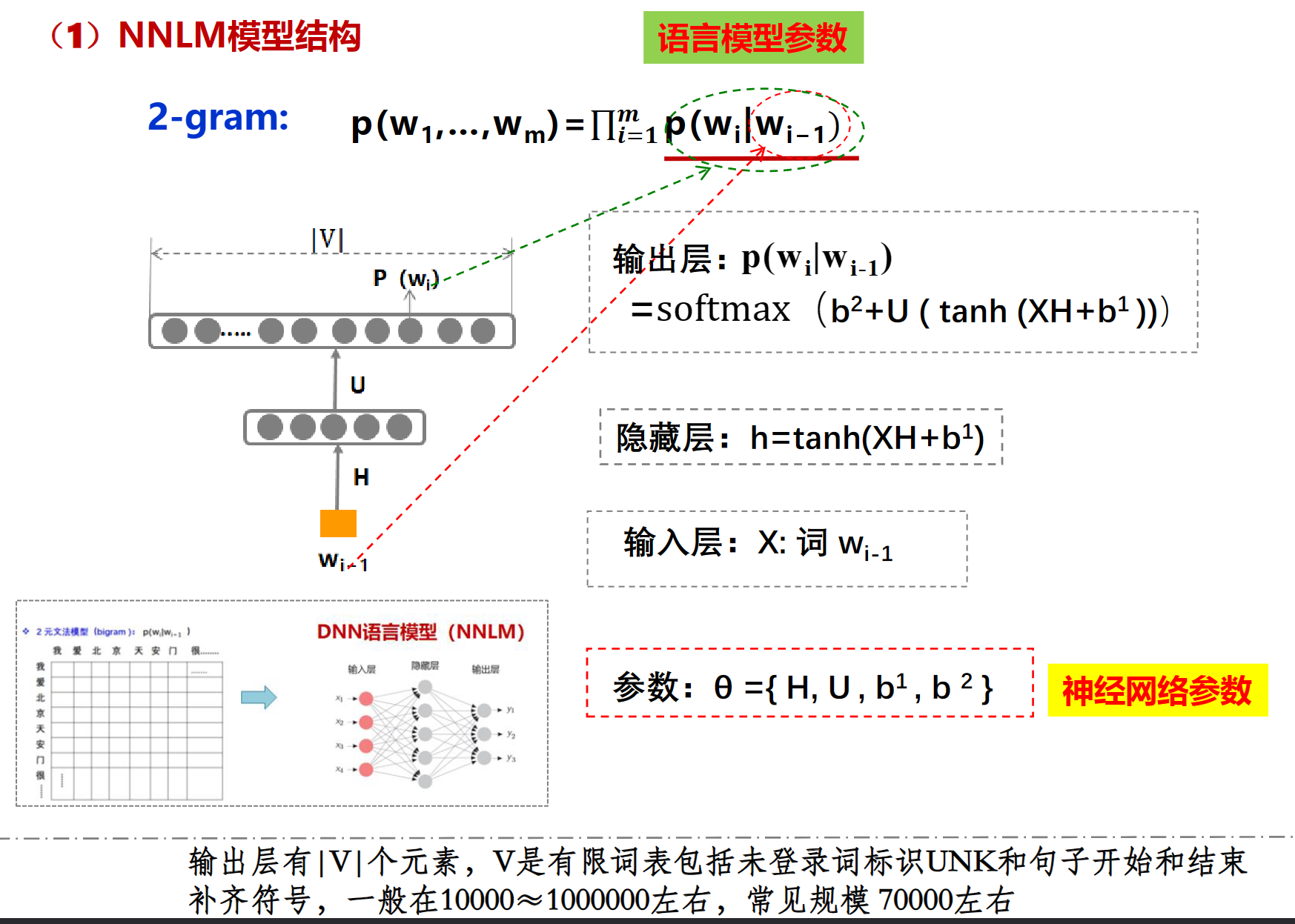
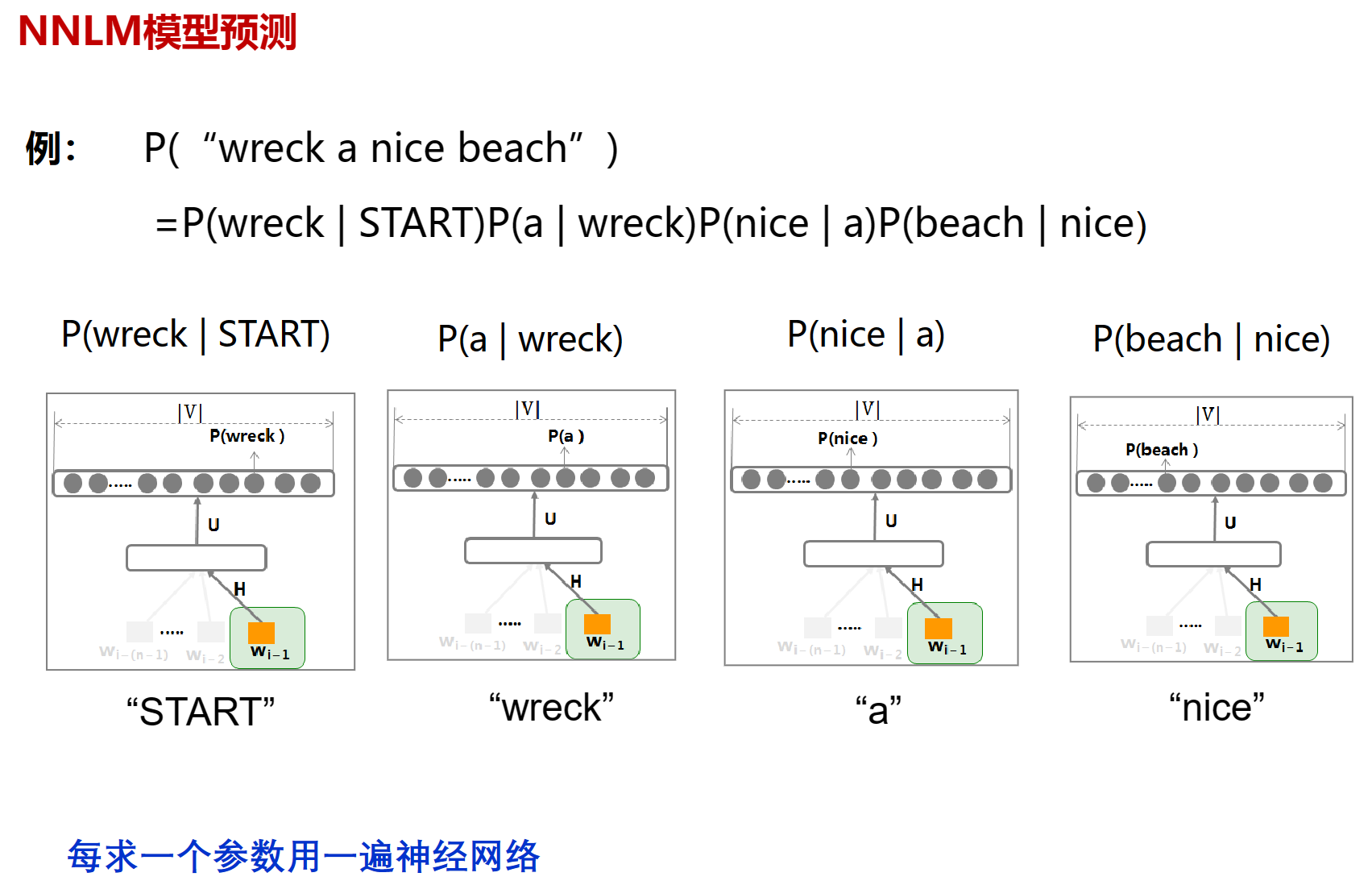
其中$\theta$就是训练过程中要学习的参数,有了这些参数就可以直接的到 $p(w_i|w_{i-1})$, 找到一组足够好的参数,就能让得到的$p(w_i|w_{i-1})$最接近训练语料库

这里的最大化就是损失函数最小(最接近0),因为P永远小于1,所以log永远是负数,他们加起来永远小于0,让log最大,也就是让log最接近0
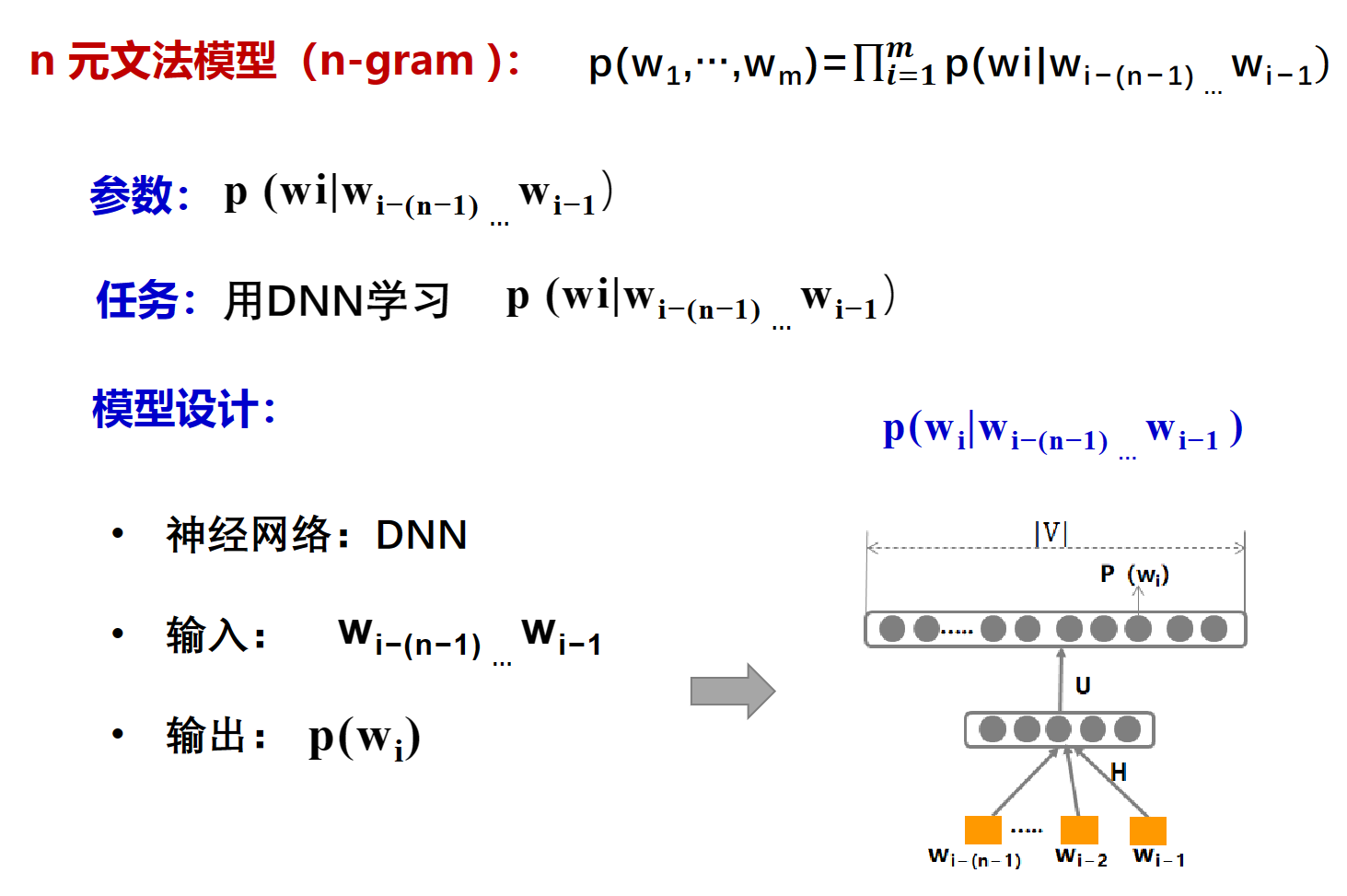
n-gram
拓展一下罢了
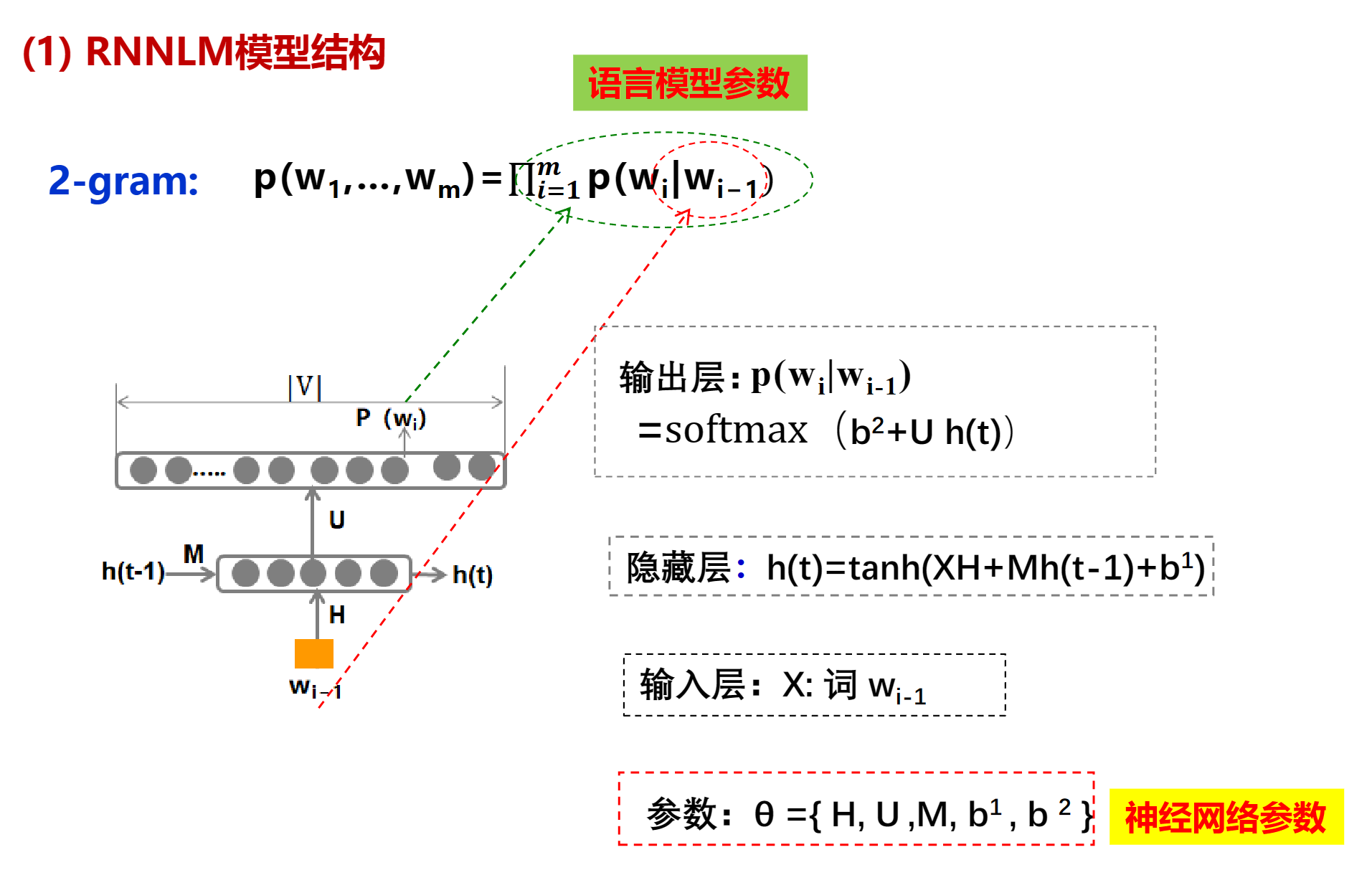
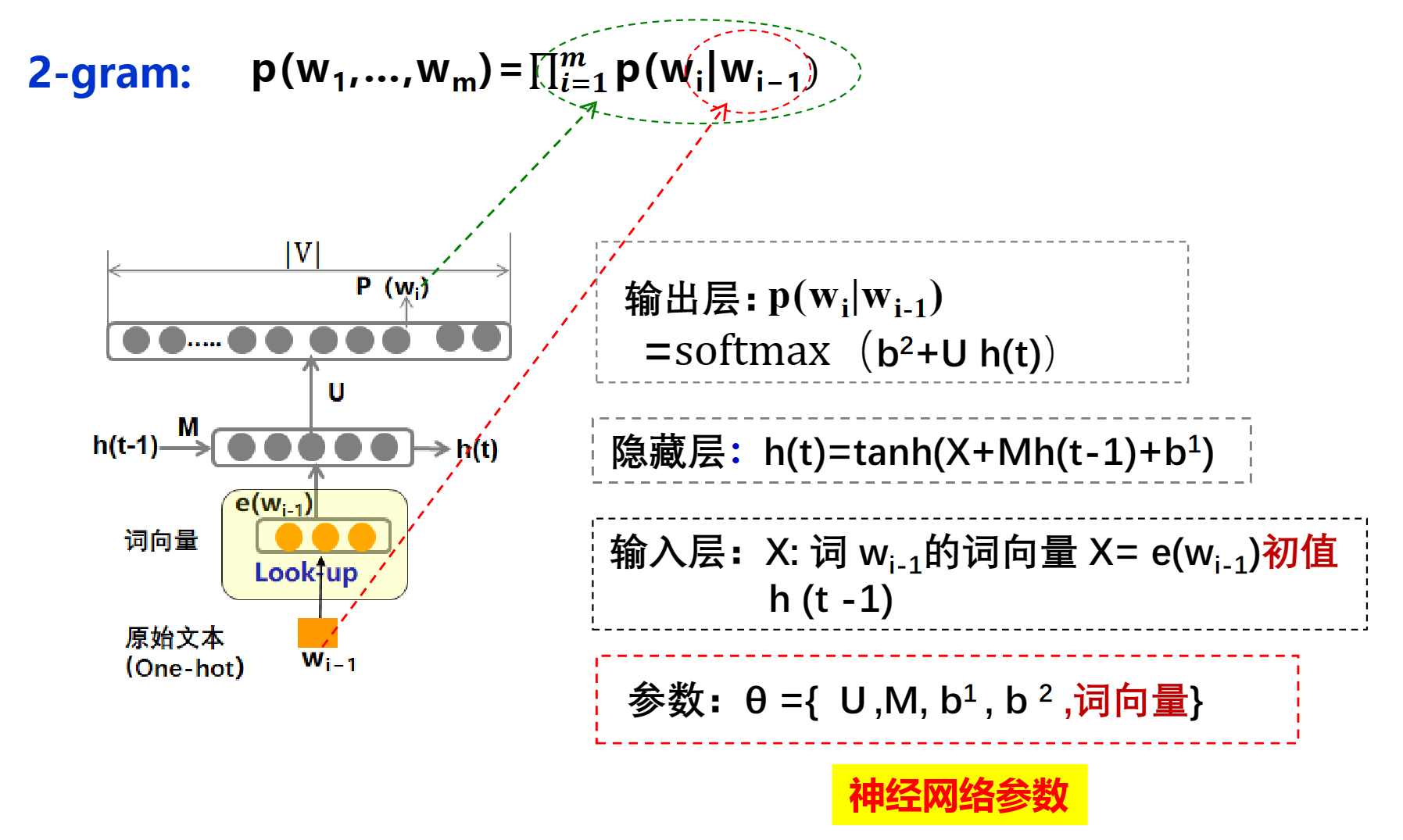
RNN(RNNLM)
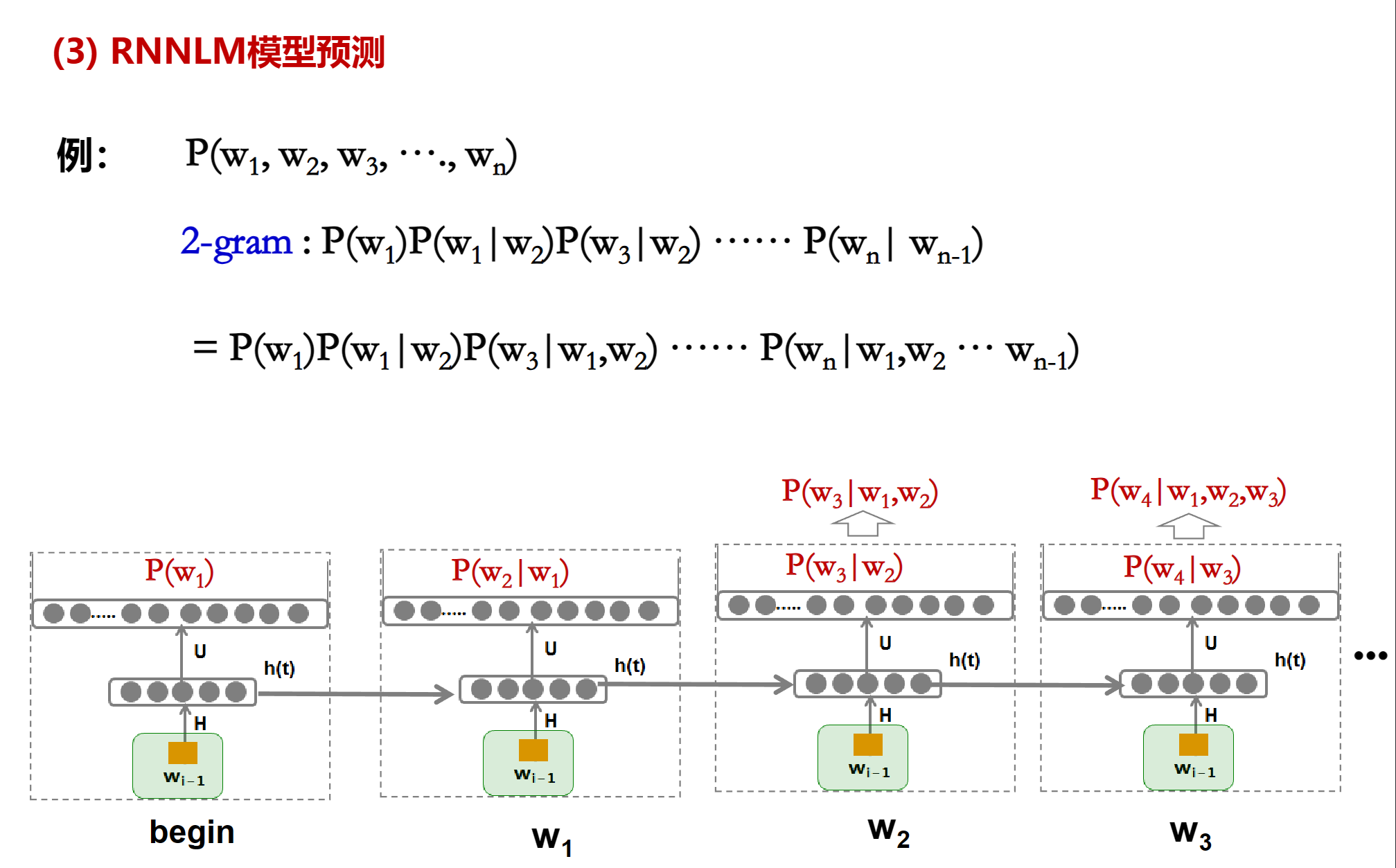
词向量
自然语言问题要用计算机处理时,第一步要找一种方法把这些符号数字化,成为计算机方便处理的形式化表示
- NNLM模型词向量
- RNNLM模型词向量
- C&W 模型词向量
- CBOW 模型词向量
- Skip-gram模型词向量
不同模型的词向量之间的主要区别在于它们捕获和编码词义和上下文信息的方式。以下是一些常见模型的词向量特点:
- 神经网络语言模型(NNLM) :NNLM通过学习预测下一个词的任务来生成词向量。这种方法可以捕获词义和词之间的关系,但是它通常无法捕获长距离的依赖关系,因为它只考虑了固定大小的上下文。
- 循环神经网络语言模型(RNNLM) :RNNLM使用循环神经网络结构,可以处理变长的输入序列,并能捕获长距离的依赖关系。因此,RNNLM生成的词向量可以包含更丰富的上下文信息。
- Word2Vec :Word2Vec是一种预训练词向量的方法,它包括两种模型:Skip-gram和CBOW。Skip-gram模型通过一个词预测其上下文,而CBOW模型则通过上下文预测一个词。Word2Vec生成的词向量可以捕获词义和词之间的各种关系,如同义词、反义词、类比关系等。
- GloVe :GloVe(Global Vectors for Word Representation)是另一种预训练词向量的方法,它通过对词-词共现矩阵进行分解来生成词向量。GloVe生成的词向量可以捕获词义和词之间的线性关系。
- BERT :BERT(Bidirectional Encoder Representations from Transformers)使用Transformer模型结构,并通过预训练任务(如Masked Language Model和Next Sentence Prediction)来生成词向量。BERT生成的词向量是上下文相关的,也就是说,同一个词在不同的上下文中可能有不同的词向量。
总的来说,不同模型的词向量之间的区别主要在于它们捕获和编码词义和上下文信息的方式。选择哪种词向量取决于具体的任务需求和计算资源。
NNLM的词向量
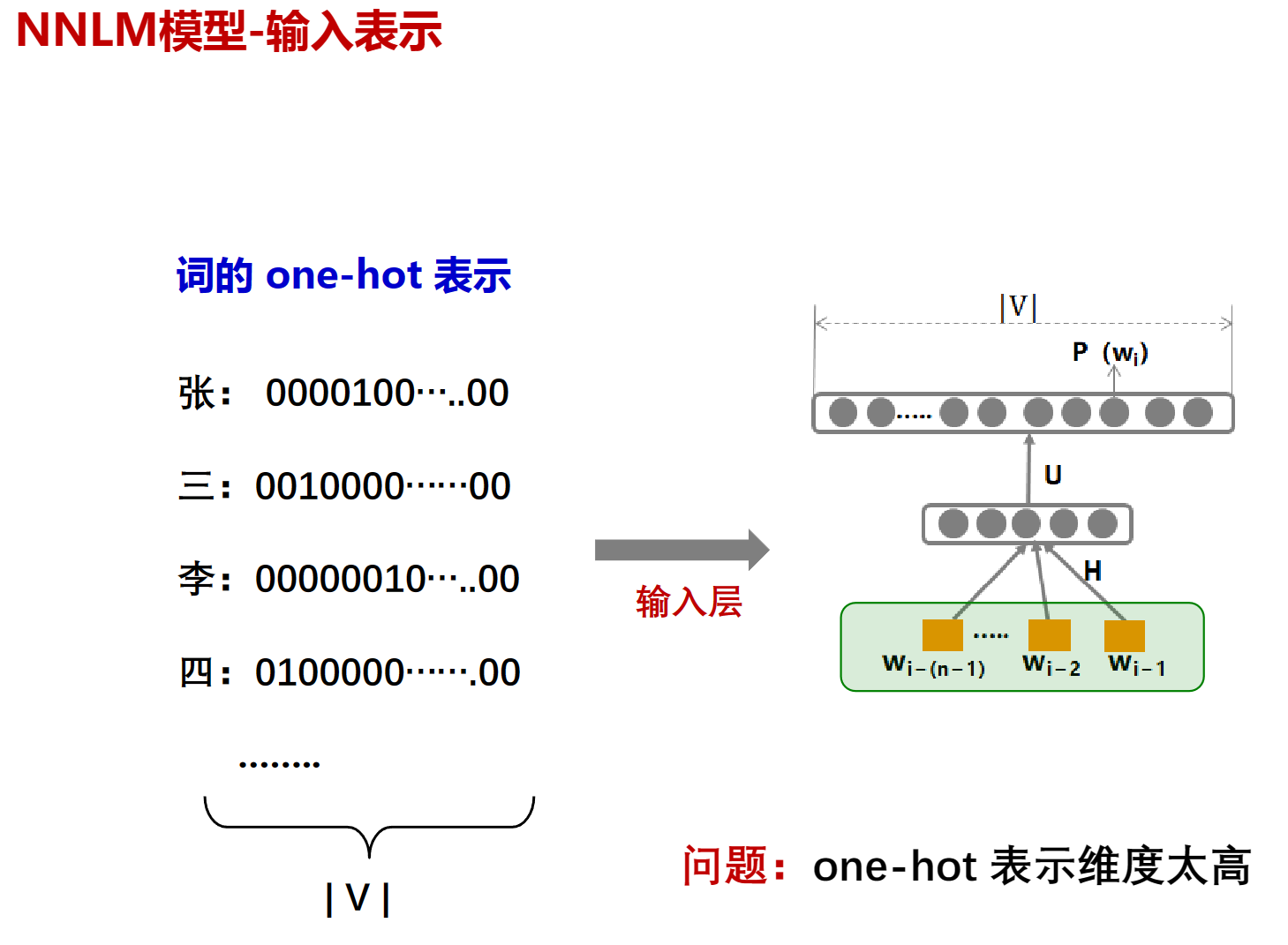
解决办法
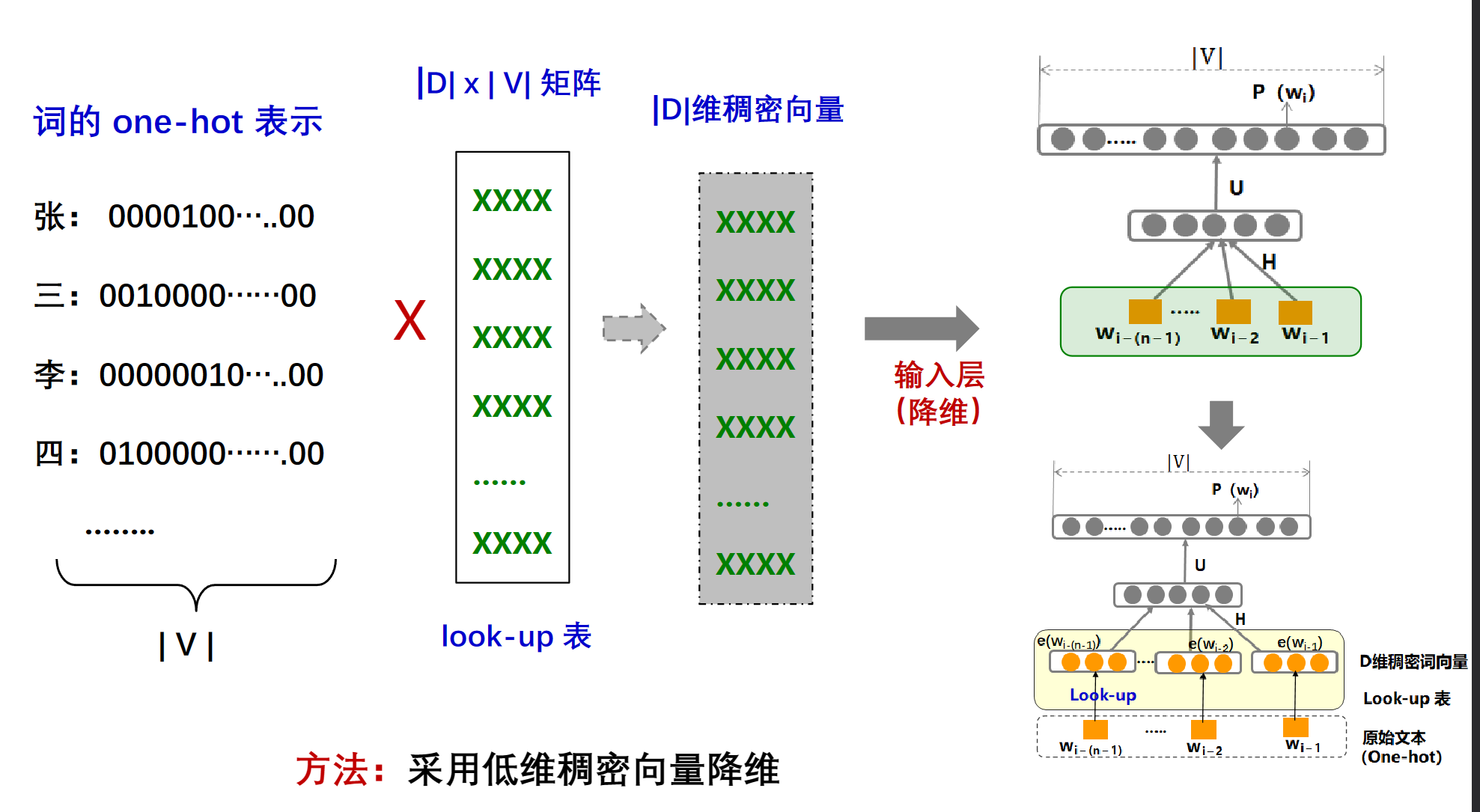
通过一个|D| * |V|的矩阵,额可以将one-shot的编码转为D维的稠密的词向量,所以管他叫lookup表

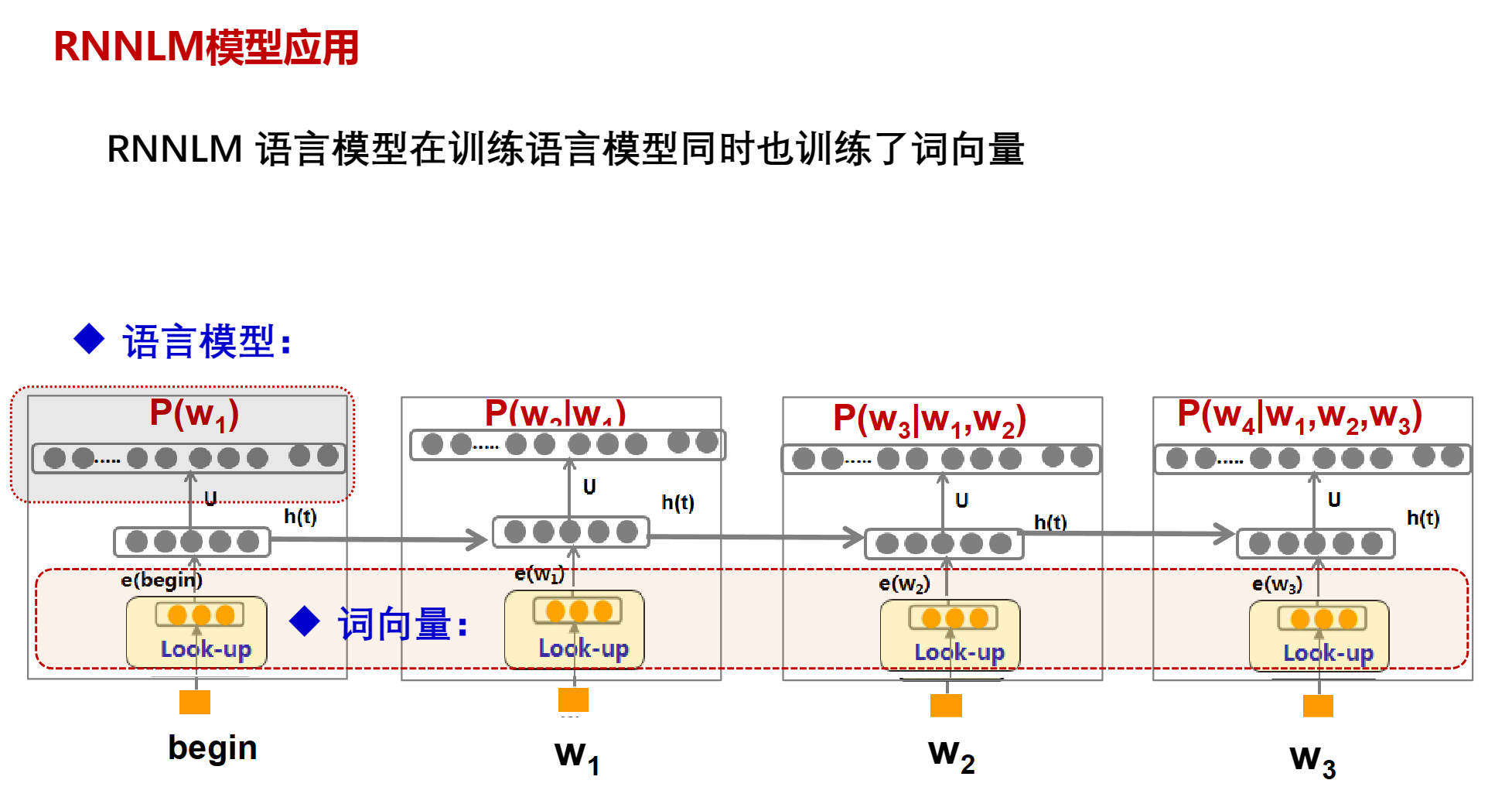
NNLM 语言模型在训练语言模型同时也训练了词向量
RNNLM的词向量
C&W
C&W模型是靠两边猜中间的一种模型,输入层是wi上下文的词向量
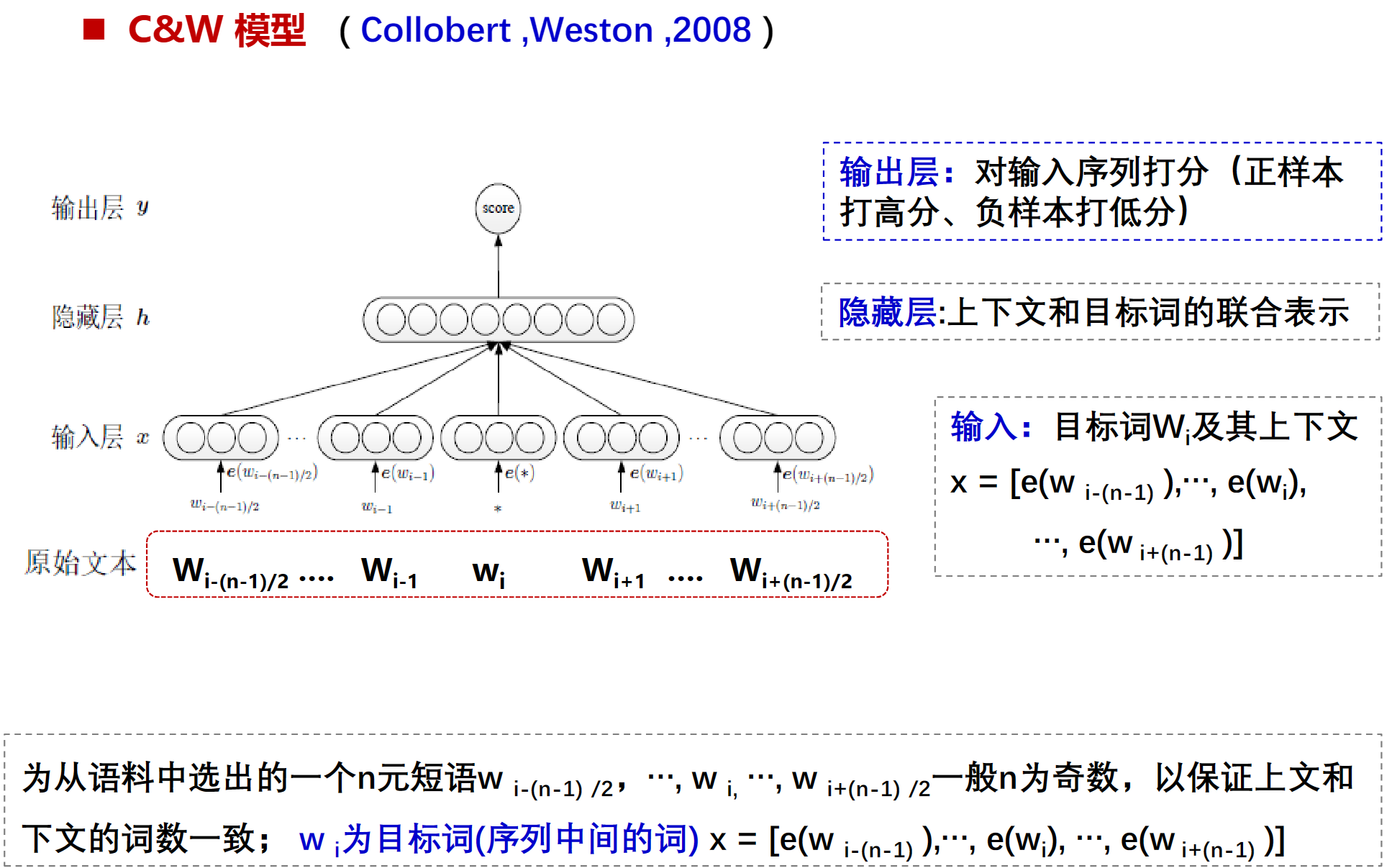
score是wi中间这个word在这个位置有多合理,越高越合理。

正样本通常是指在实际语料库中出现过的词语及其上下文。负样本则是人为构造的,通常是将一个词与一个随机的上下文配对。
Pairwise方法在训练C&W词向量时,主要是通过比较一对词的上下文来进行训练的。具体来说,对于每一对词(一个正样本和一个负样本),我们都会计算它们的词向量,并通过比较这两个词向量的相似度来更新我们的模型。
在训练过程中,我们首先需要选择一个损失函数,这里是修改后的HingeLoss
然后,我们会使用一种优化算法来最小化这个损失函数,这里是梯度下降,在每一次迭代中,我们都会根据当前的损失来更新我们的词向量。
训练的目标是在正样本中的score高,负样本的score低,然后score差的越大效果越好
CBOW
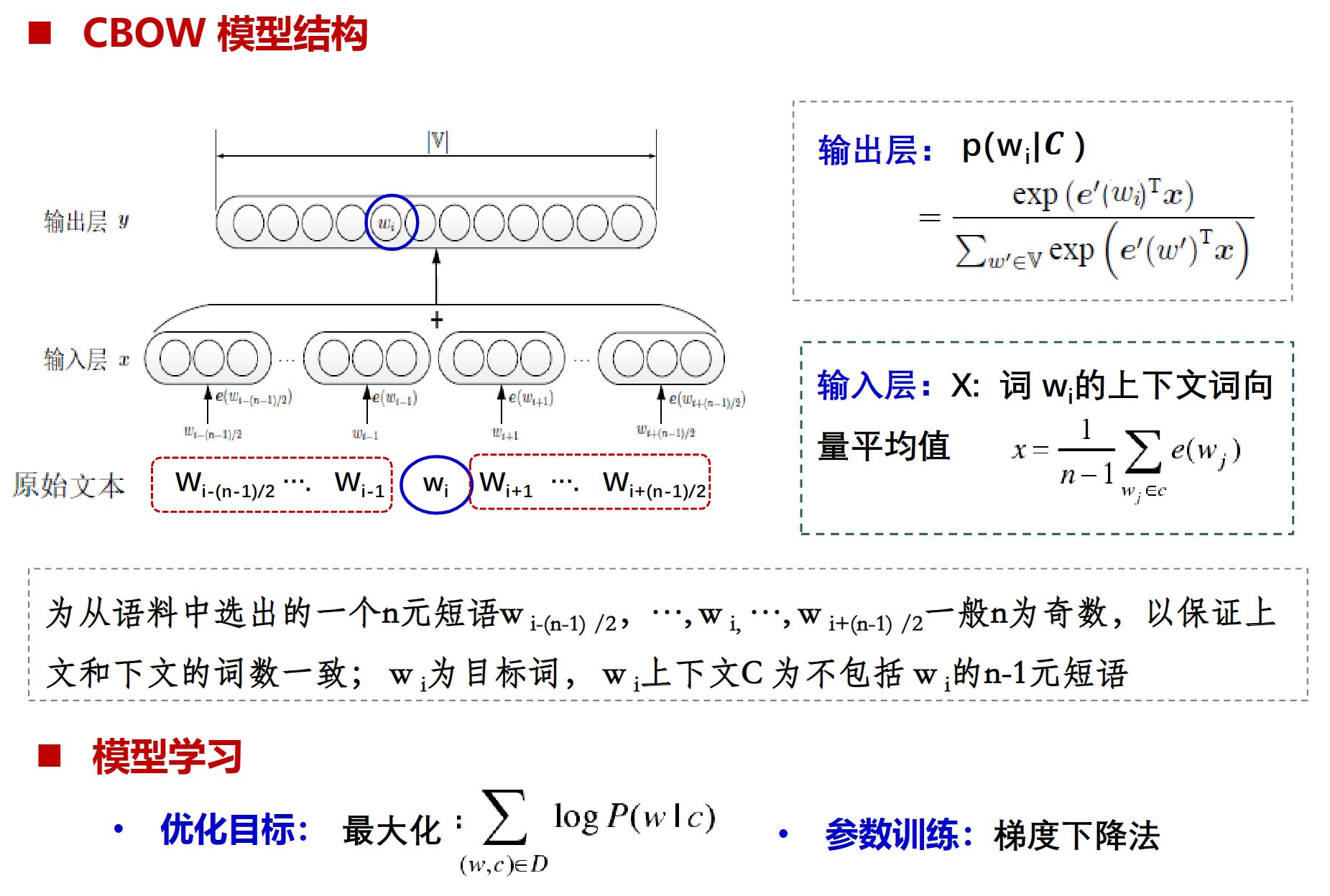
CBOW也是靠两边猜中间,输入层是wi上下文词向量的平均值,目标是最小化(最收敛与0)上下文词的平均与目标词之间的距离。输出是
skip-gram
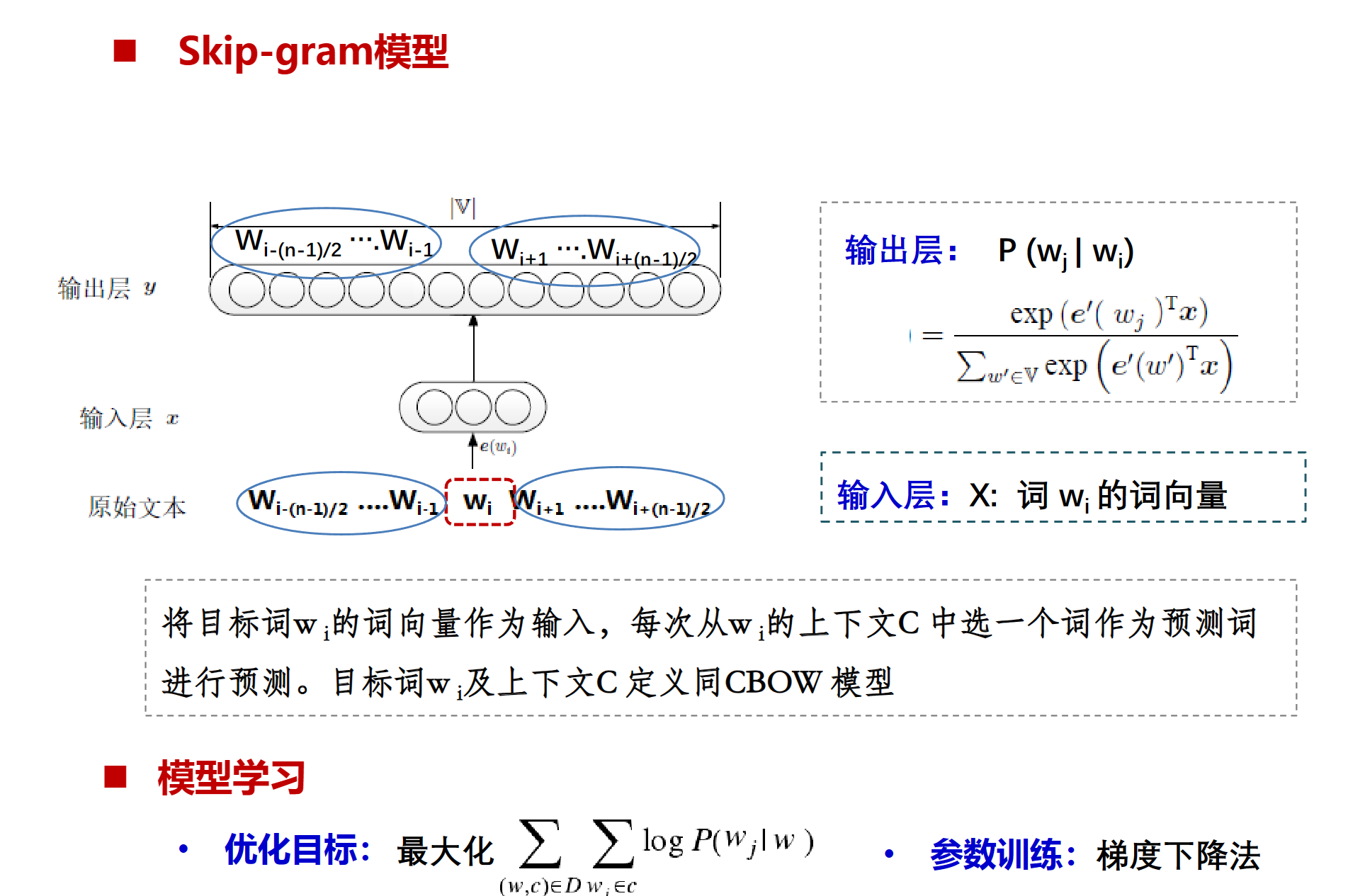
skip-gram是知道中间猜两边,训练最小化(最收敛于0)目标词与上下文词之间的距离。
注意力机制
概述
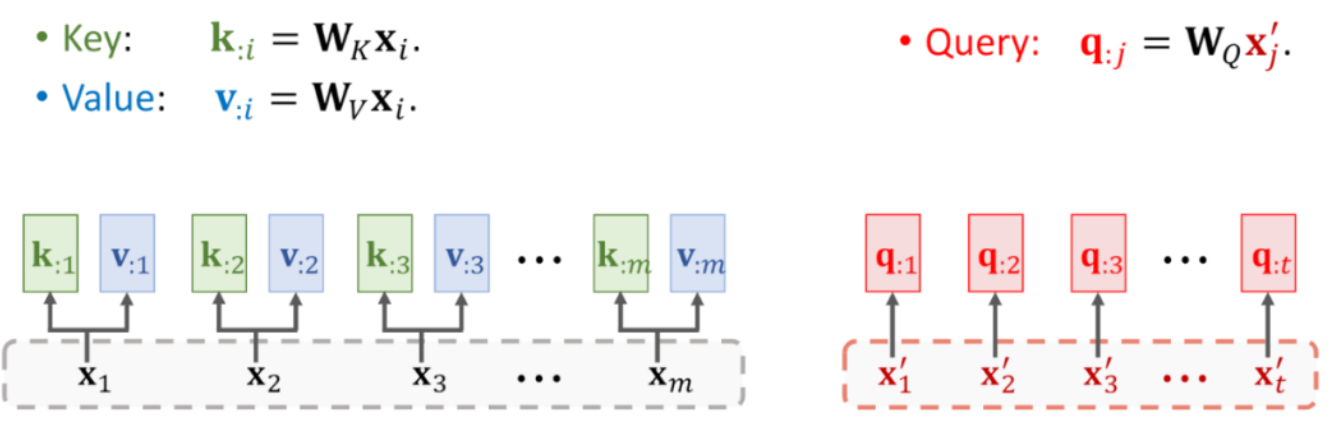
在注意力机制中,Q、K、V 分别代表查询(Query)、键(Key)和值(Value)。
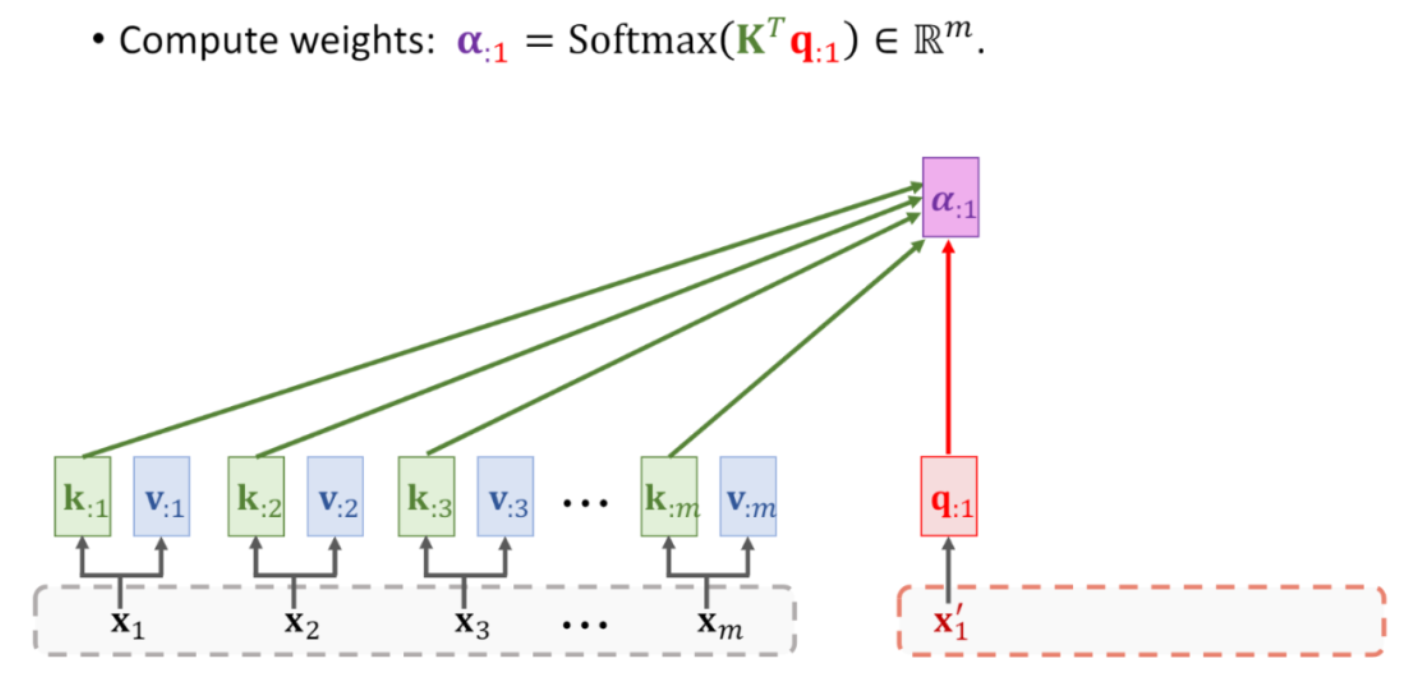
注意力机制的工作过程可以简单概括为:对于每一个查询,计算它与所有键的匹配程度(通常使用点积),然后对这些匹配程度进行归一化(通常使用 softmax 函数),得到每个键对应的权重。最后,用这些权重对所有的值进行加权求和,得到最终的输出。
这种机制允许模型在处理一个元素时,考虑到其他相关元素的信息,从而捕捉输入元素之间的依赖关系。在自然语言处理、计算机视觉等领域,注意力机制已经被广泛应用,并取得了显著的效果。
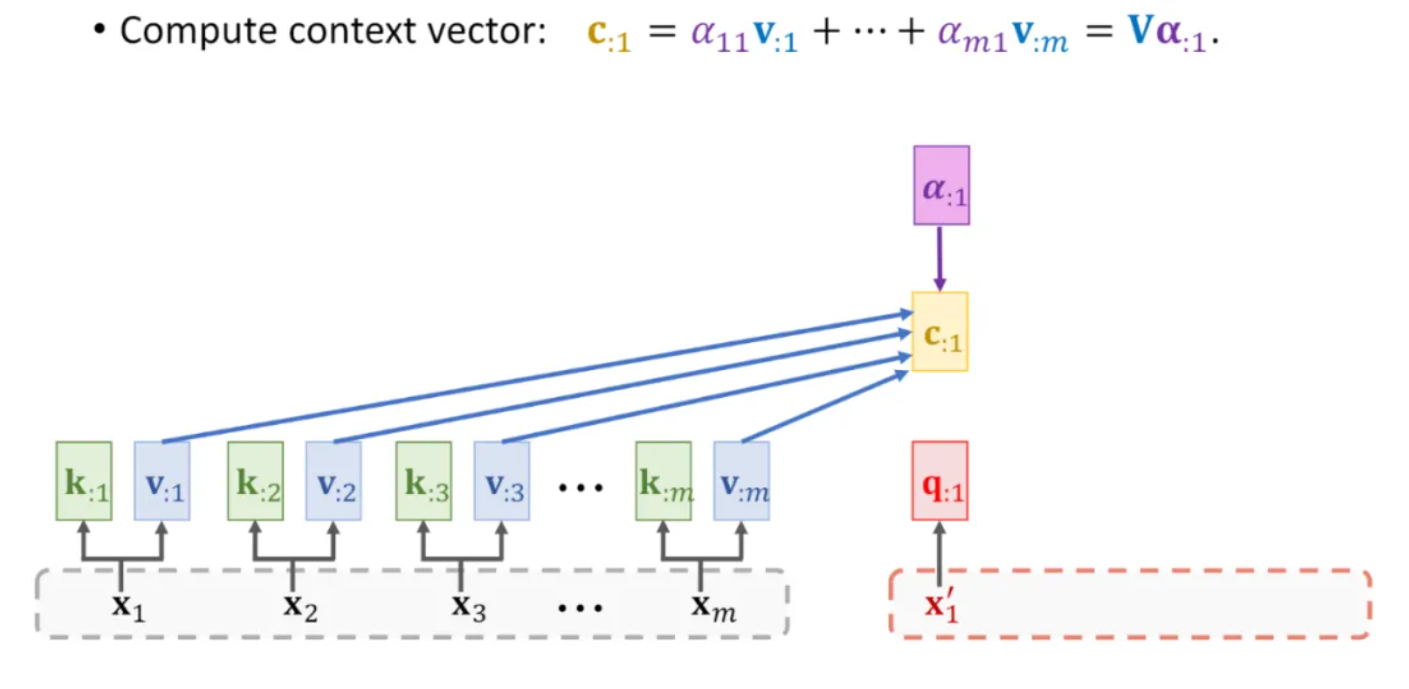
W是权重,都是学来的。
参考
Attention机制: https://www.bilibili.com/video/BV1YA411G7Ep

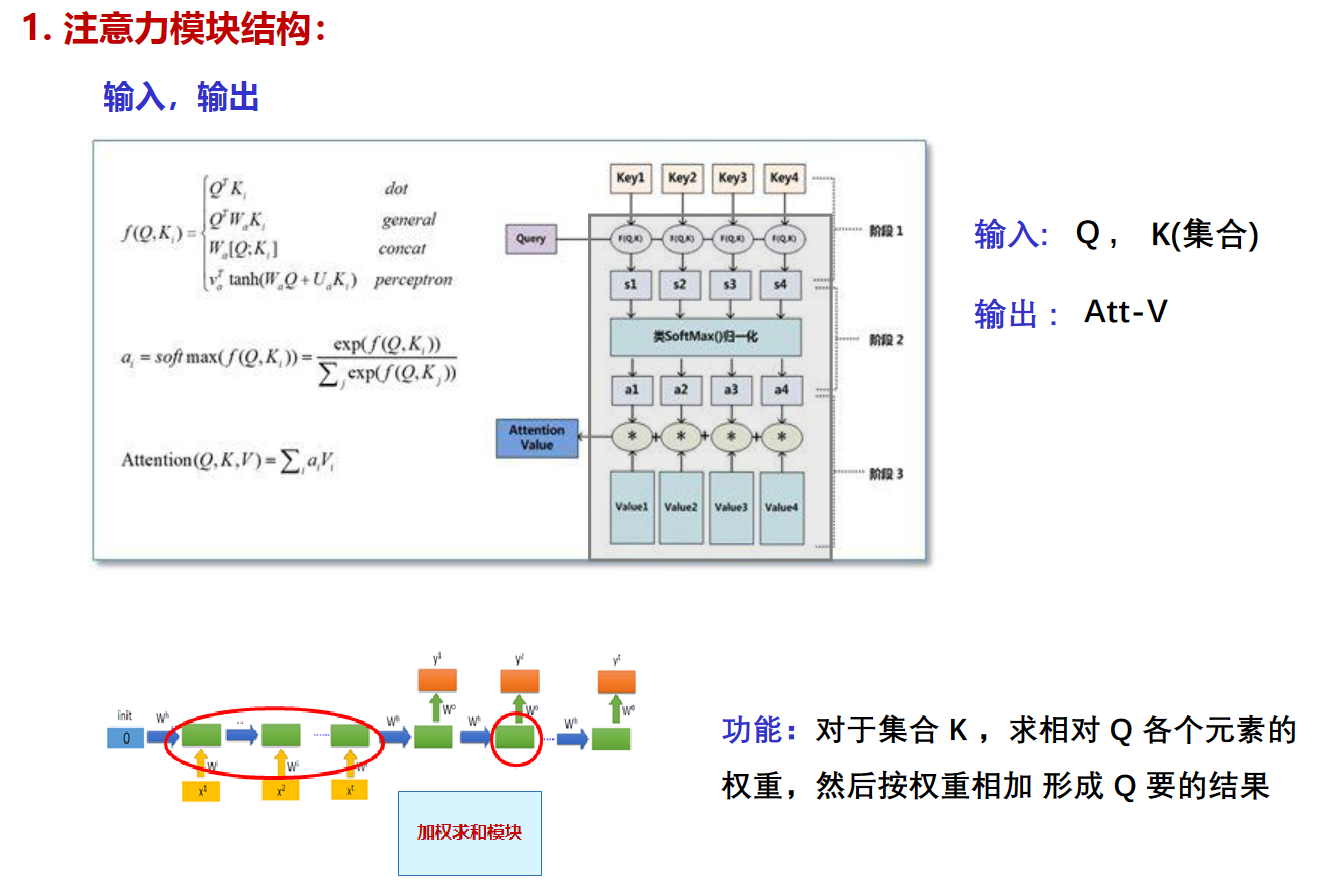
K、V都是经过线性变换的词向量集合(矩阵)
Q是隐藏状态(隐藏向量)
A是一个注意力值,就是我们设置的这个字的注意力值
通过attention的学习,可以得到a1、a2……,这些就是K中各个向量对Q的权重
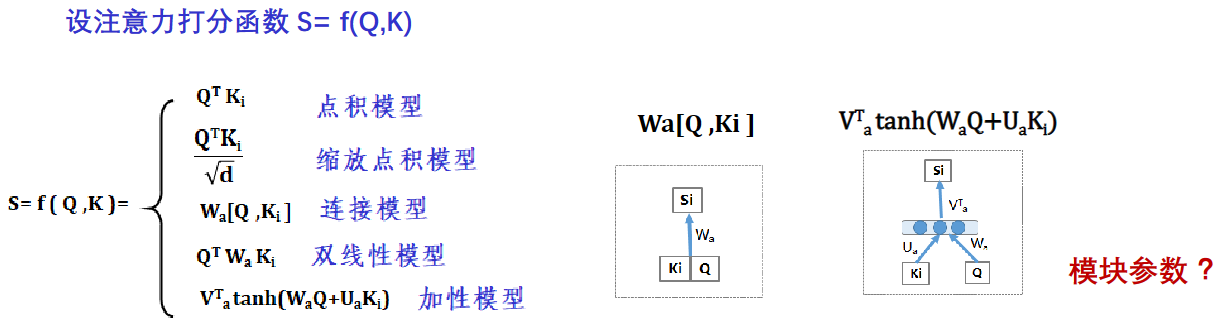
步骤1:计算 f ( Q ,Ki )
步骤2:计算对于Q 各个 Ki 的权重

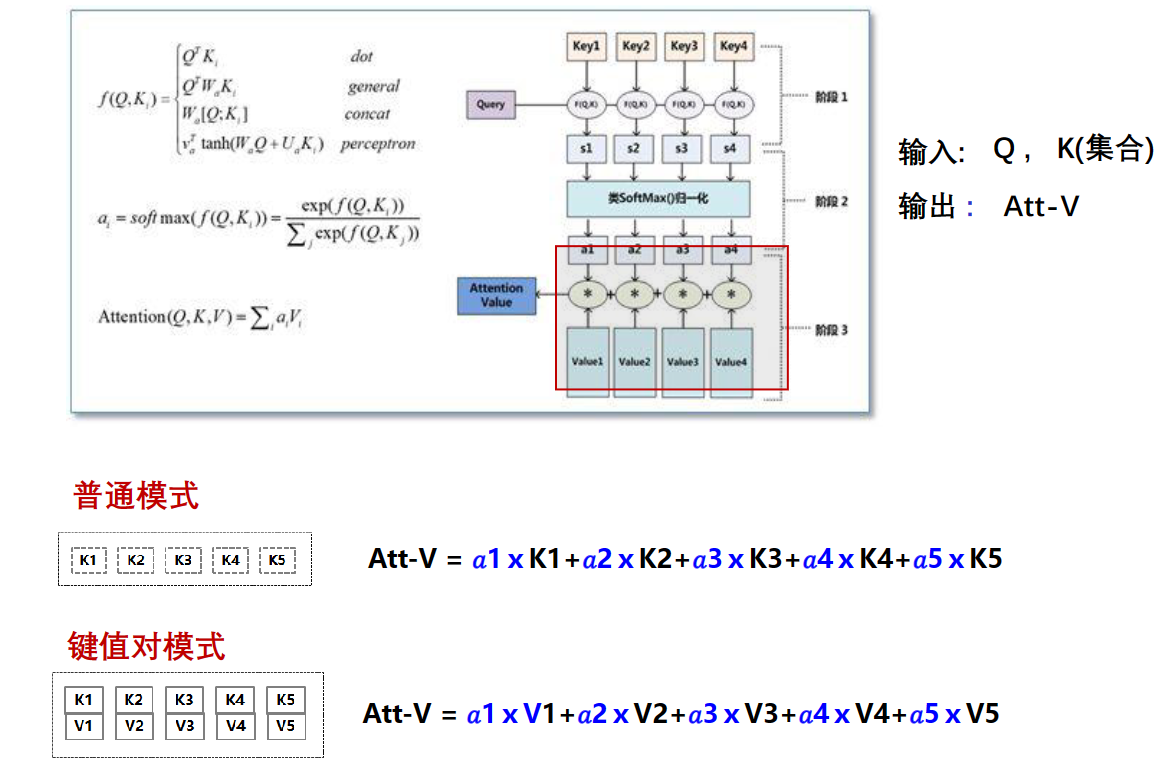
步骤3:计算输出 Att-V值(各 Ki 乘以自己的权重,然后求和 )
举例1, seq2seq(RNN2RNN)的机器翻译中
seq2seq做机器翻译的过程,需要大量的两种语言的平行语料,就是意思相同的语言的一一对应的关系。
其中x为词向量,A为权重矩阵,h为隐藏状态(隐藏向量)。
RNN是用预训练的词向量,然后通过学习权重矩阵A来微调,得到隐藏状态,可以理解为隐藏状态是带了上下文的更加符合RNN的词的向量表示。
每一个时间步中,A都被微调, 因此x1、x2、x3的A可能都是不一样的。在大量预料的训练下会获得表现比较好的A和A'
h可以表示为$h_t = f(W_{hh}h_{t-1} + W_{xh}x_t + b_h)$其中$h_t$ 是当前时间步的隐藏状态,$h_{t-1}$ 是前一时间步的隐藏状态,$x_t$ 是当前时间步的输入,$W_{hh}$ 和 $W_{xh}$ 是权重矩阵,$b_h$ 是偏置项,$f$ 是激活函数
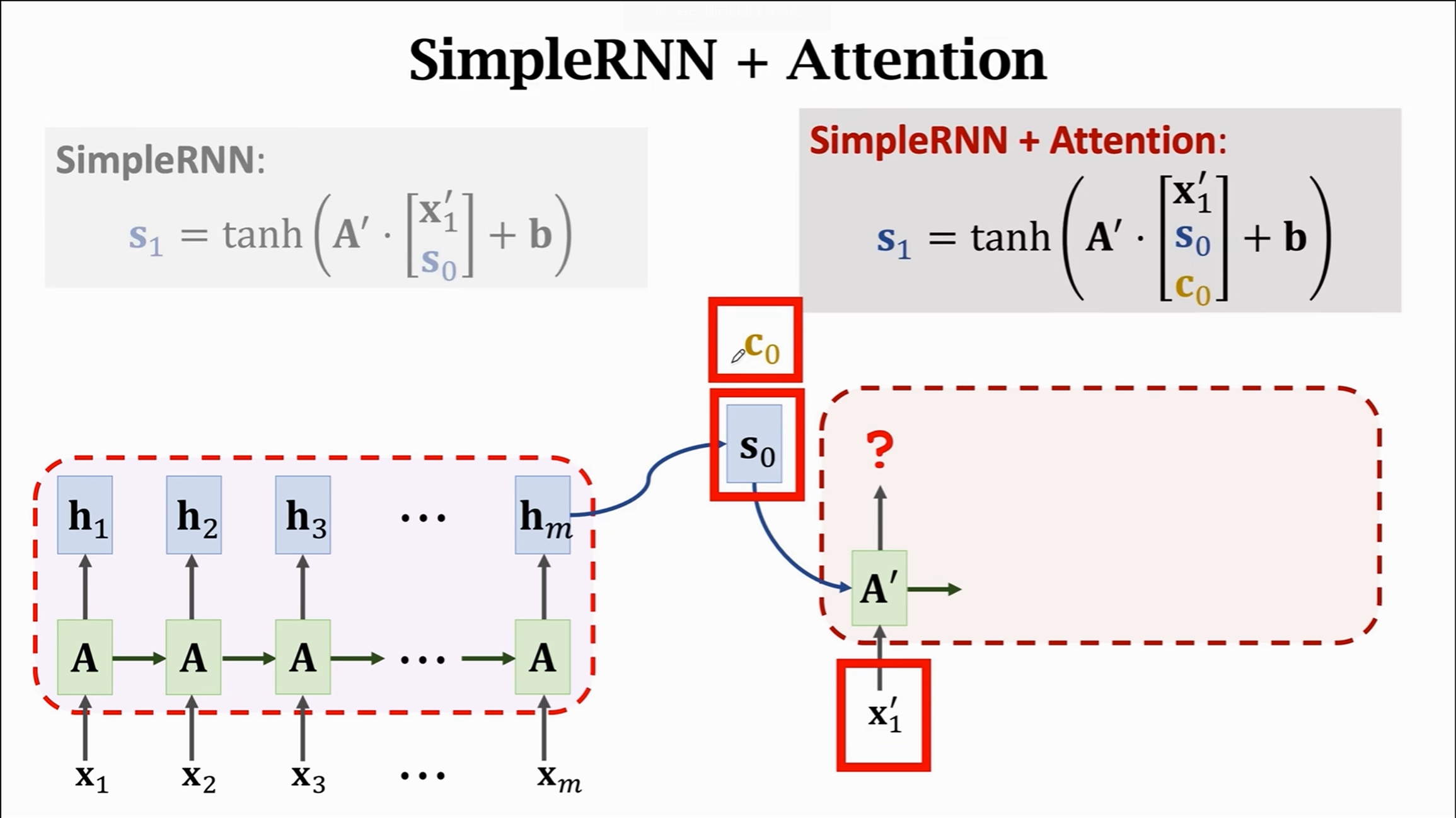
不加注意力机智的seq2seq模型,encoder是RNN,decoder也是RNN,在encoder接受了$x_1$到$x_m$的词向量序列后,得到最终的隐藏状态$h_m$, 也就是$s_0$,作为decoder的初始状态。
如果不加注意力机制,decoder那边也就是靠隐藏状态、x和参数(A矩阵,偏置值b)来继续进行RNN的步骤。
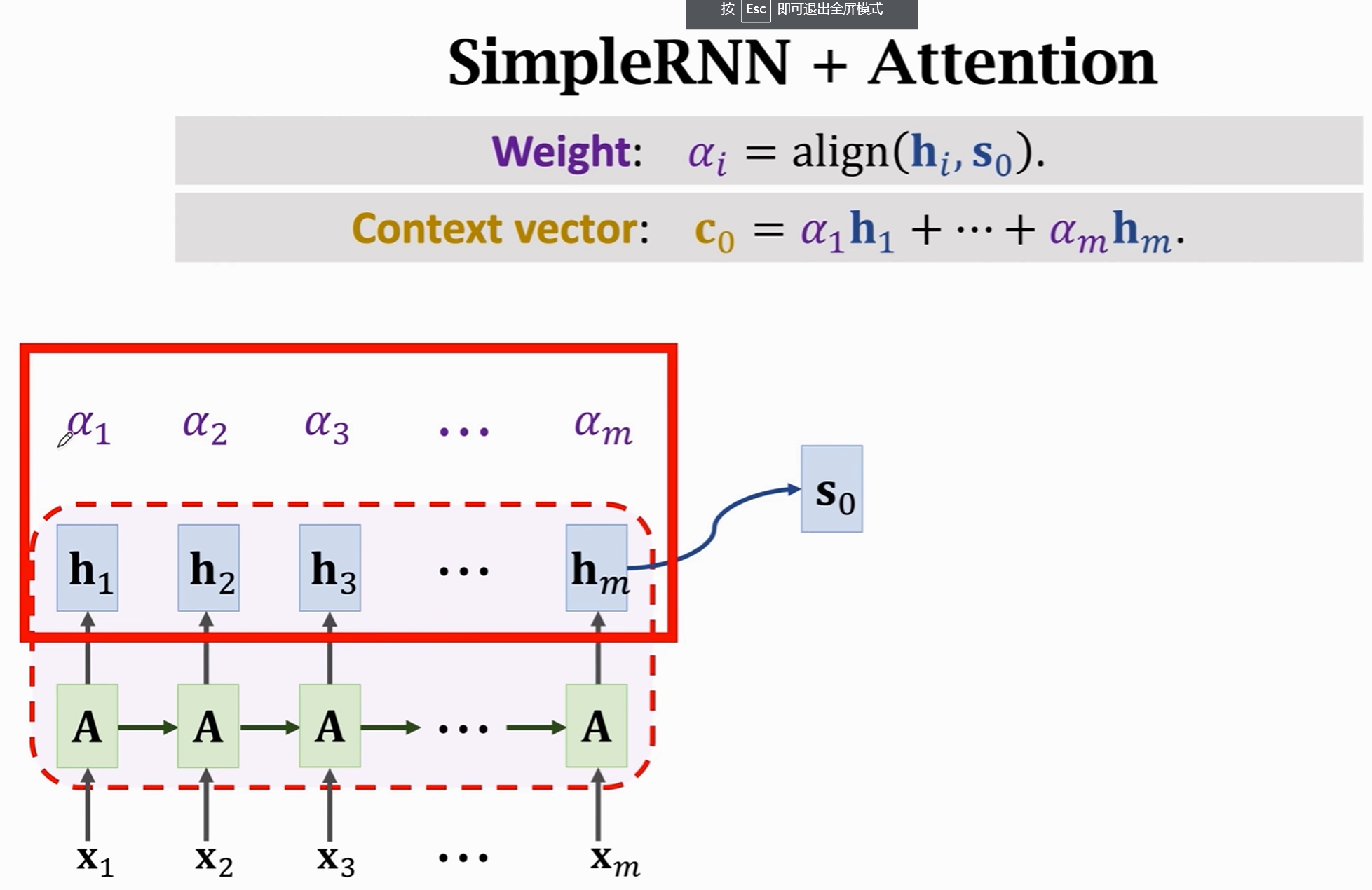
现在我们引入注意力机制,也就是图上的$c_0$,权重的计算按照上面所说的KQV计算方法,这里K是词向量集合x1,x2… Q是隐藏状态。也就是对于每一个隐藏状态,都可以求一个关于词向量序列的权重值$\alpha$。
通过求出这一系列的$\alpha$,就可以加权求出上下文矩阵$c$,c知道当前隐藏状态和词向量矩阵的全部关系。
加了注意力机制之后,decoder的各个隐藏状态求解过程就会向之前提到的那样变得更复杂

而每一个步骤的c都不一样,比如
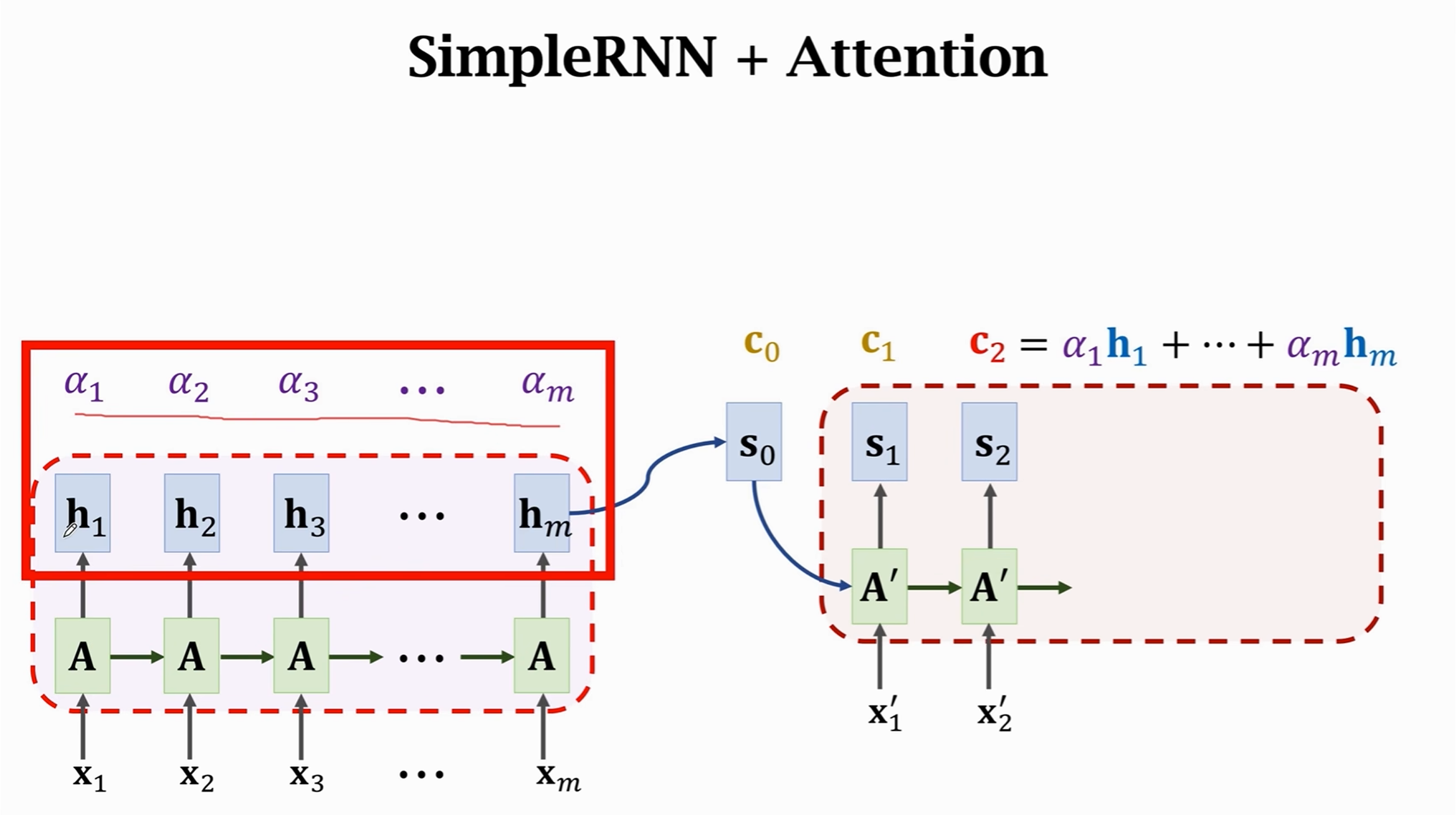
c0是s0对于x1,x2…的att-V,也就是hm对于x1,x2…的att-V;c1是隐藏状态s1对于x1,x2…的att-V,c2是隐藏状态s2对于x1,x2…的att-V这些c都需要花算力来算
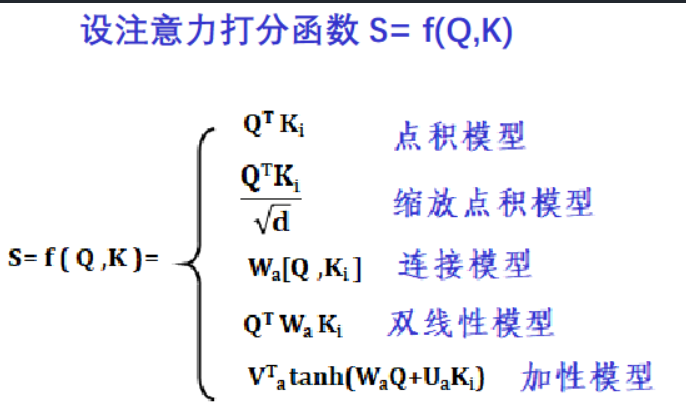
注意力机制的问题是时间复杂度太大了。如果是简单的RNN2RNN,如果encoder词向量矩阵大小为m,decoder词向量矩阵大小为n,所需的时间复杂度为O(m+n),而使用注意力机制之后就会变成O(mn),还是打分函数比较简单的情况下。
注意力编码机制
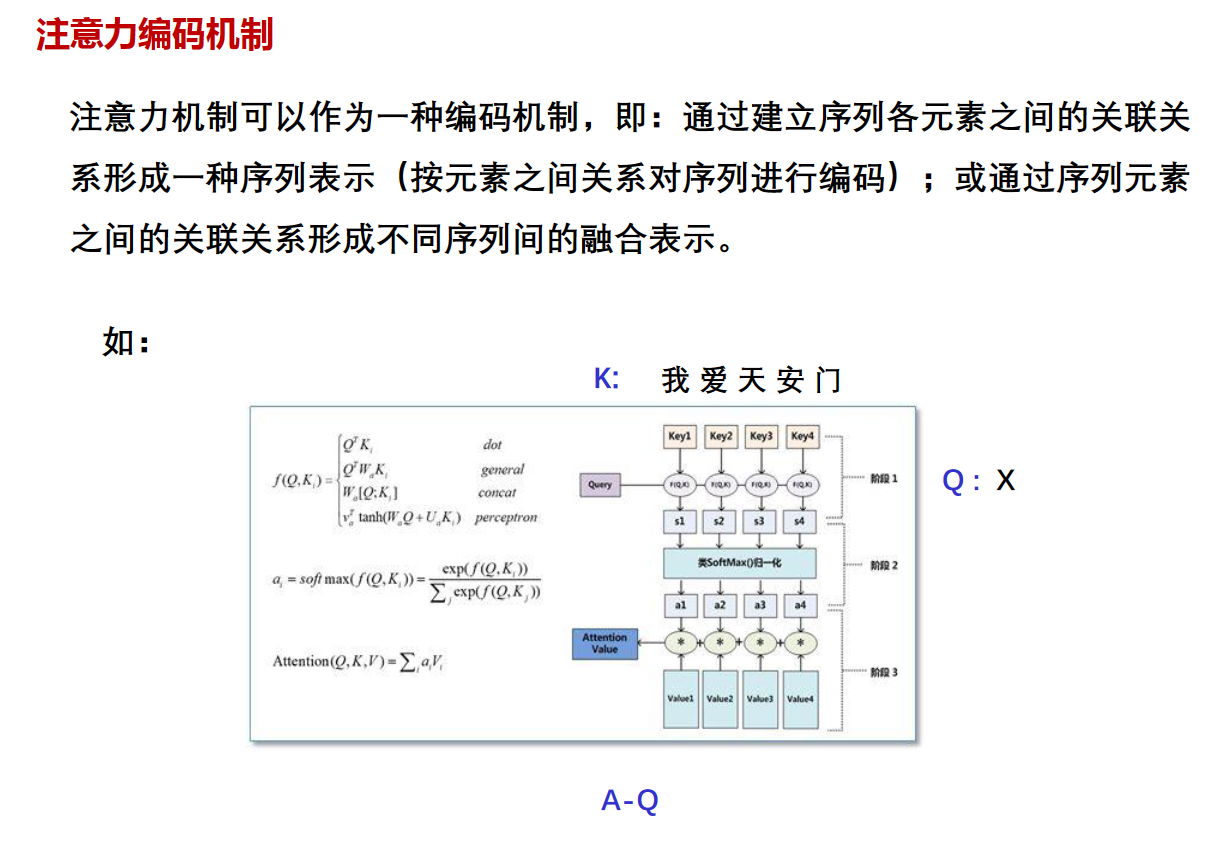
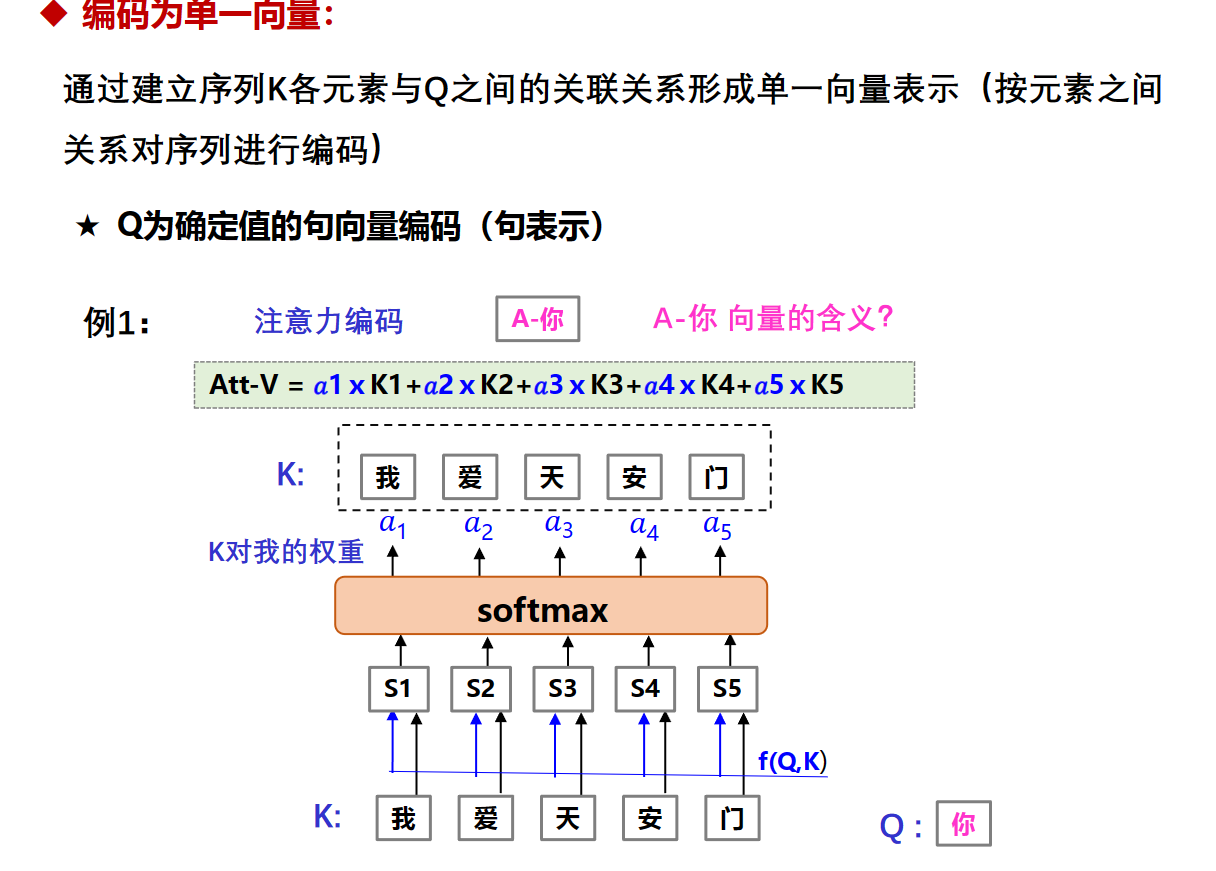
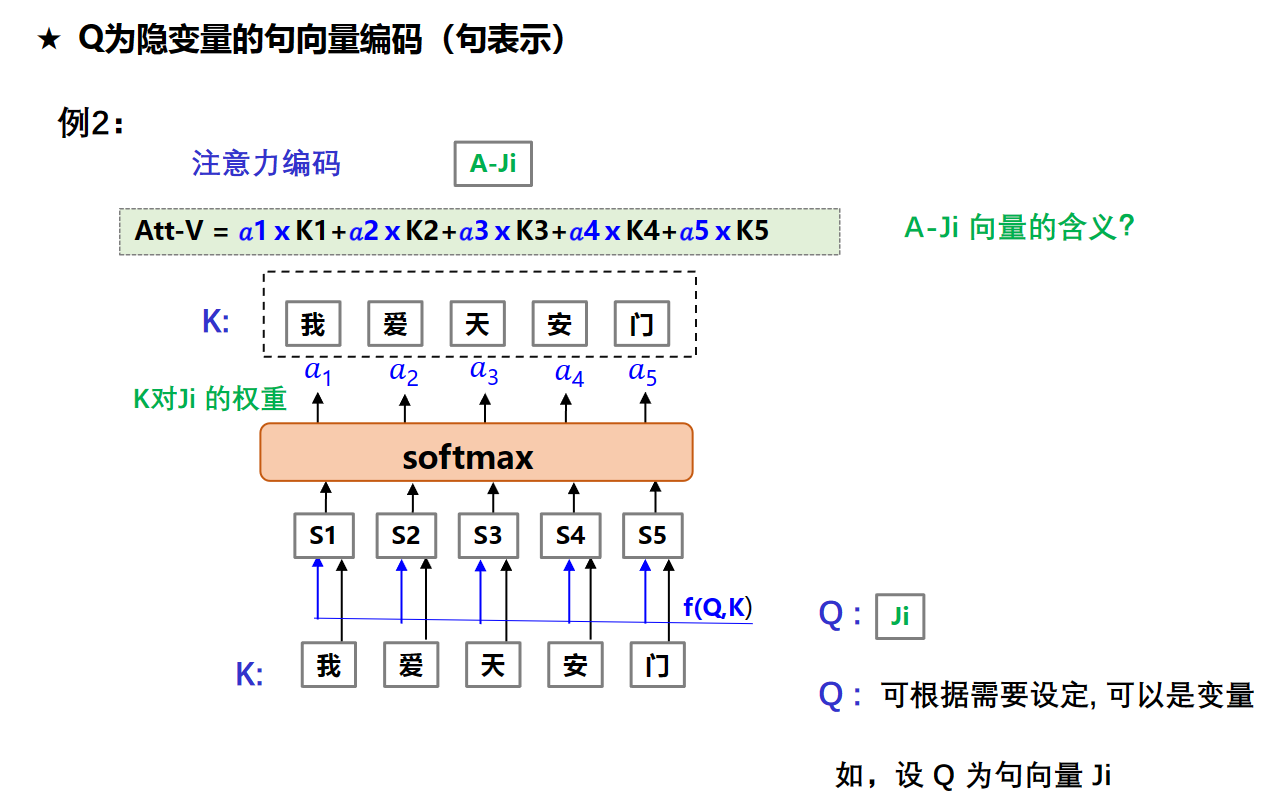
attention机制还可以将不同序列融合编码(将多个序列经过某种处理或嵌入方式,转换为一个固定长度的向量或表示形式。)
就是给每个词向量乘个权重加起来,被称作注意力池化(Attention Pooling)或加权求和(Weighted Sum)。这个操作的含义是将注意力权重分配给输入序列中的不同部分,从而形成一个汇聚了注意力的向量表示。
这个操作的效果是聚焦于输入序列中具有更高注意力权重的部分,形成一个综合的表示,其中对于重要的部分有更大的贡献。这对于处理序列数据中的上下文信息,关注重要元素,以及实现对不同部分不同程度的关注都非常有用,特别是在自然语言处理中的任务中。
预训练语言模型
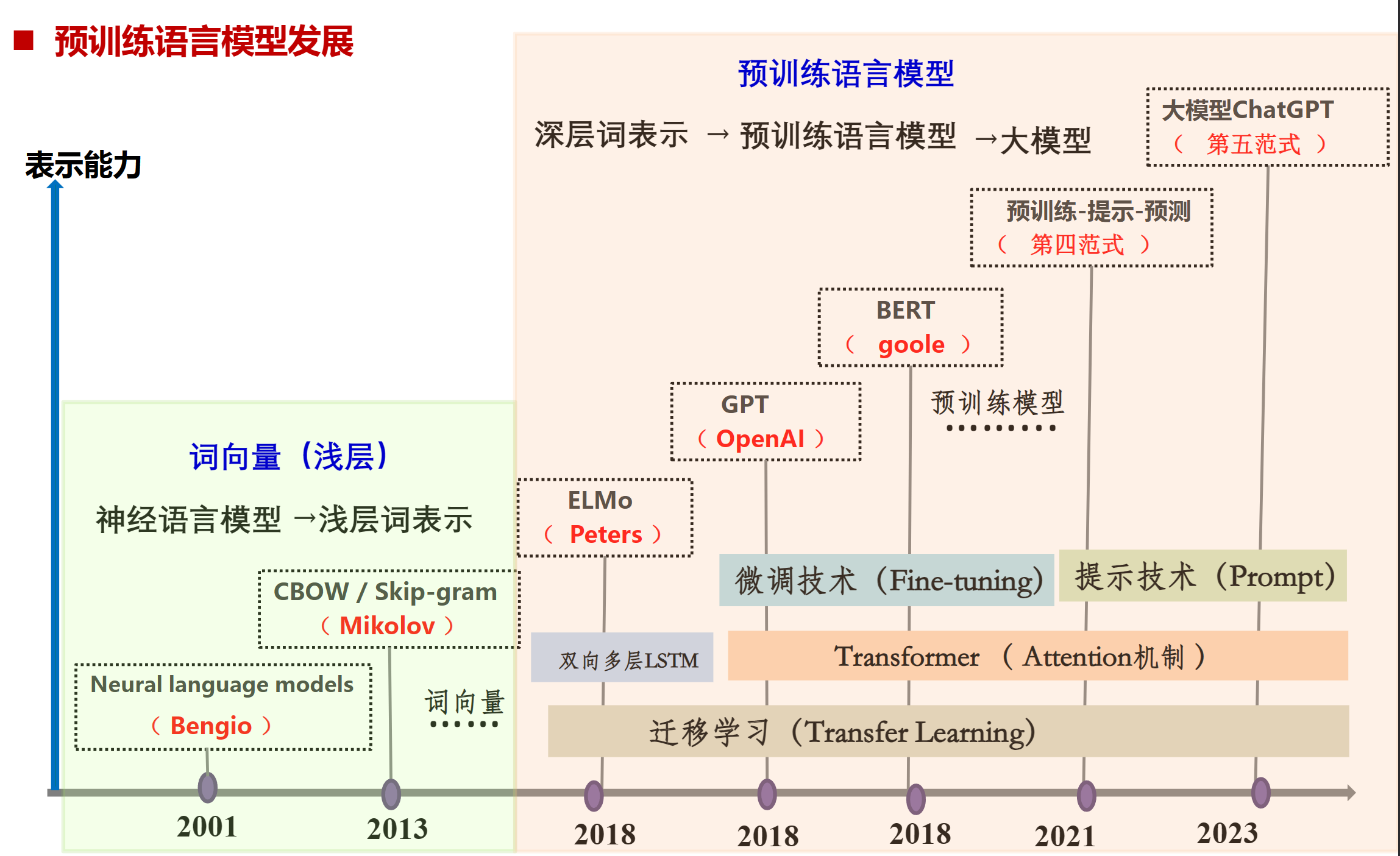
迁移学习
迁移学习(Transfer Learning)是一种机器学习方法,其核心思想是利用已有的知识来辅助学习新的知识。例如,已经会下中国象棋,就可以类比着来学习国际象棋;已经会编写Java程序,就可以类比着来学习C#。
迁移学习通常会关注有一个源域(源任务) $D_ {s}$ 和一个目标域(目标任务) $D_ {t}$ 的情况.
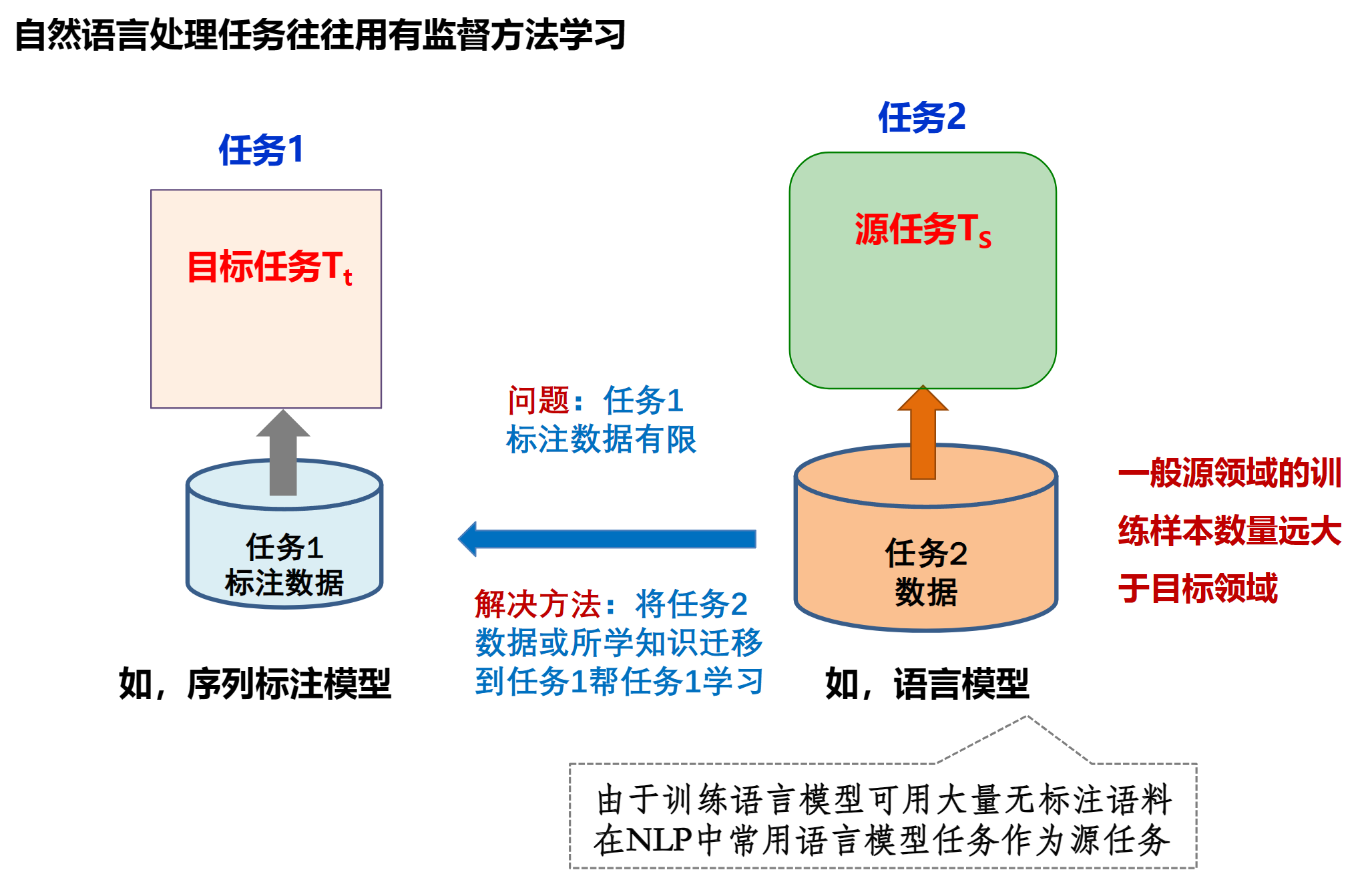
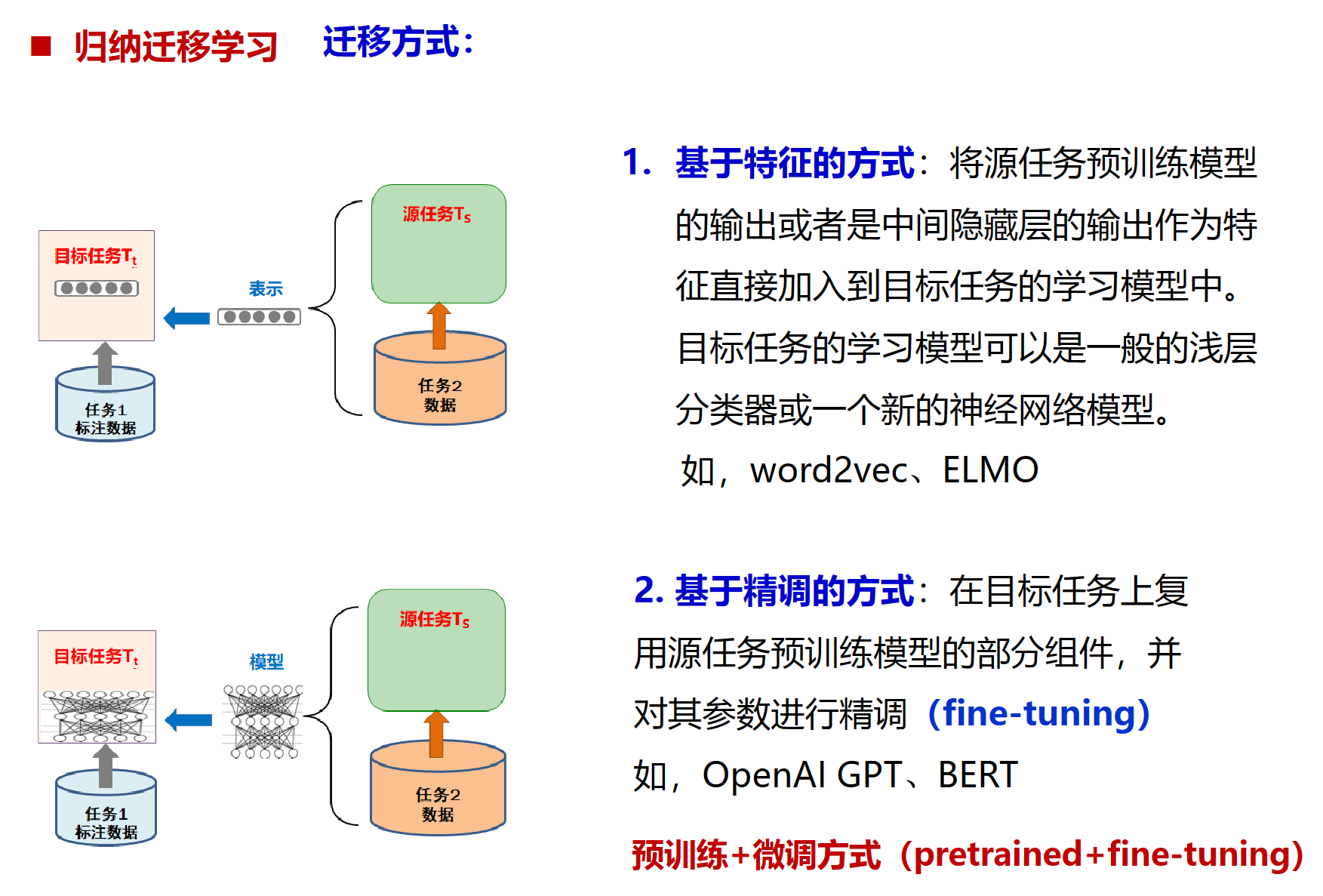
迁移方式分为两种
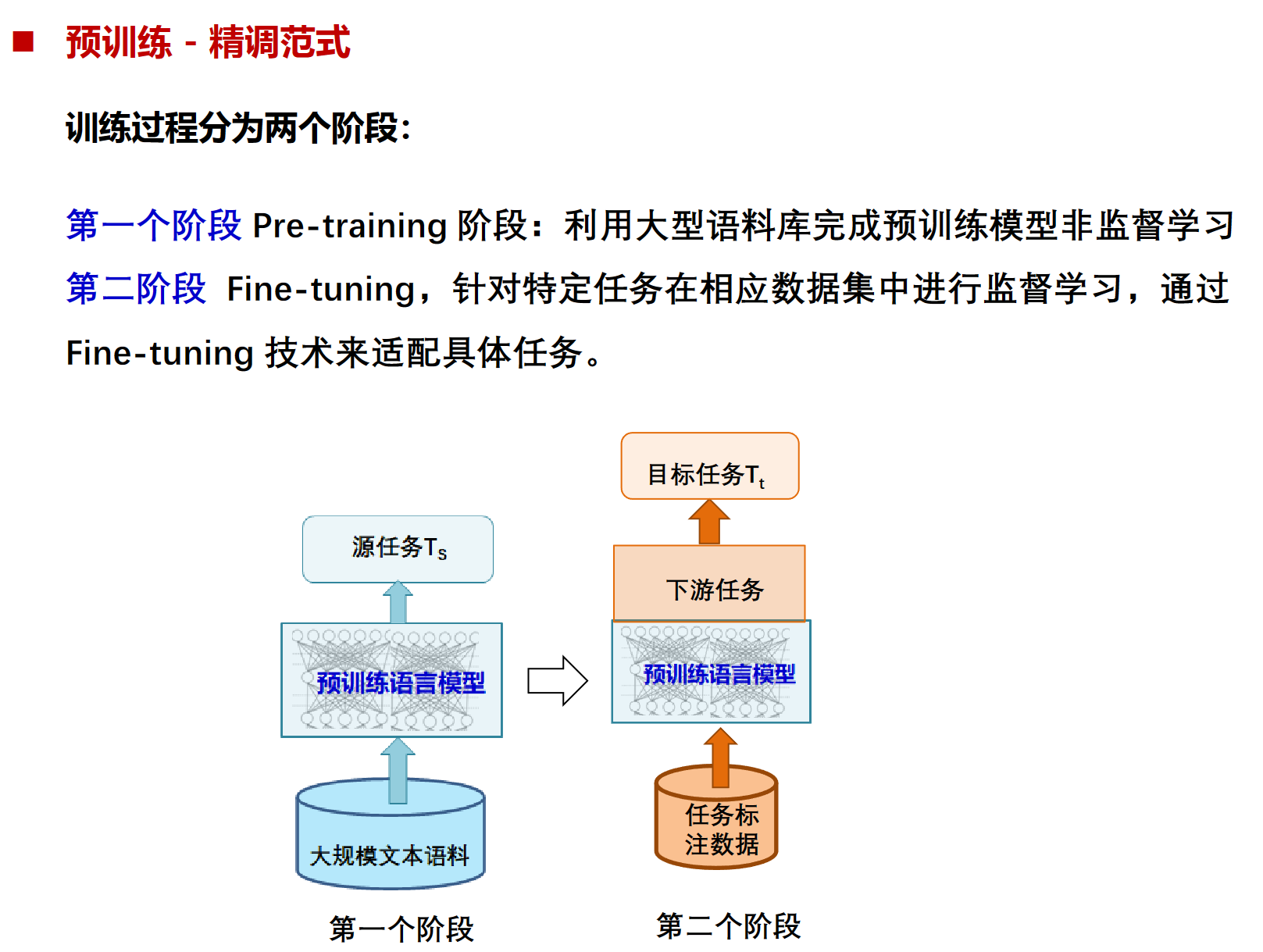
几个范式

第三范式:预训练-精调范式

自回归:预测序列的下一个或者上一个
自编码:预测序列中的某一个或某几个
广义自回归:和自回归主要区别在于他们处理输入数据的方式。自回归预训练语言模型在生成序列时,会一个接一个地生成新的词,每个新词都依赖于前面的词。如GPT,而广义自回归预训练语言模型则更为灵活,它们可以在生成序列时考虑更多的上下文信息,模型不仅可以查看前面的词,还可以查看后面的词或者整个序列。如XLNet

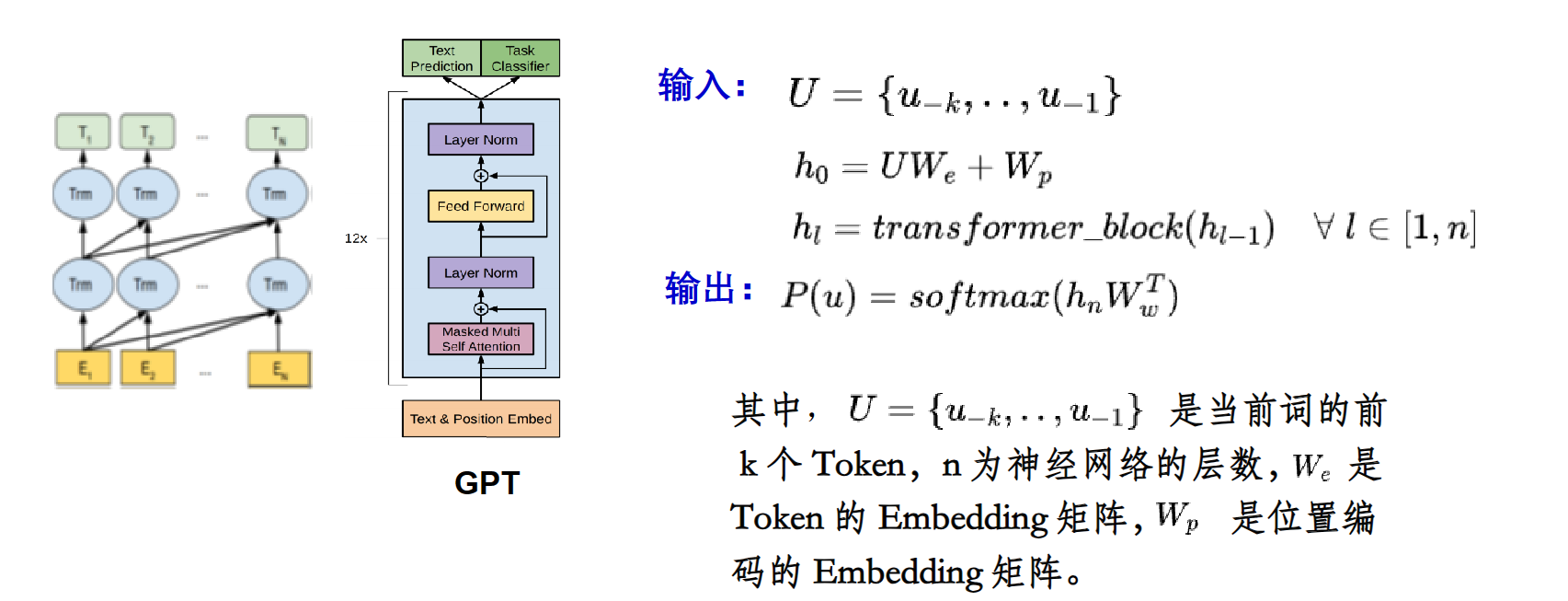
GPT训练和对接
GPT 采用了 Transformer 的 Decoder 部分,并且每个子层只有一个 Masked Multi Self-Attention(768 维向量和 12 个 Attention Head)和一个FeedForward (无普通transformer解码器层的编码器-解码器注意力子层),模型共叠加使用了 12 层的 Decoder。使用了从左向右的单向注意力机制
Masked Multi Self-Attention的768维向量和12个attention head: 意思是12个独立的attention组件,每个组件的参数都独立,然后每个attention的Q向量都是768维,也可以理解为一个词在模型中的向量(或者说词嵌入)是768维]
feedforward: 作用是提取更深层次的特征。在每个序列的位置单独应用一个全连接前馈网络,由两个线性层和一个激活函数组成。线性层将每个位置的表示扩展,为学习更复杂的特征提供可能性,激活函数帮助模型学习更复杂的非线性特征,第二个线性层将每个位置的表示压缩回原始维度。这样,位置特征敏感的部分就会被表达出来,提供给后续网络学习。
就是十二个下图这样的小东西
transformer输入有token embedding和position embedding
对比一下transformer,transformer的decoder是6个右边的,少了一层multi-head attention的encoder-decoder注意力子层(cross-attention的那个子模块)
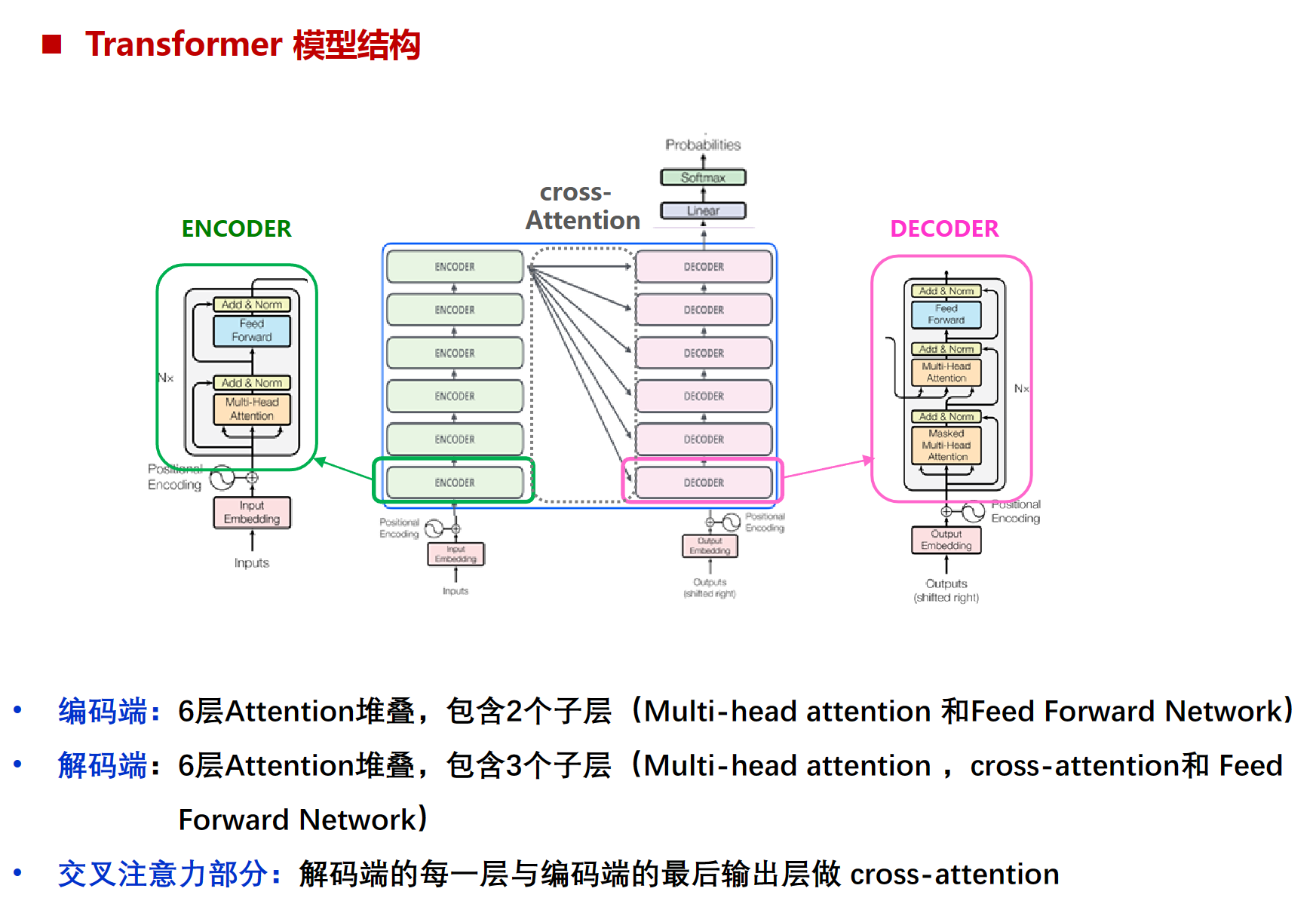
6层attention堆叠就是六个encoder就是个小的encoder,每个encoder里都有attention机制,上图N=6的意思。
训练:

maximize负数=近0最小化
与下游任务对接:
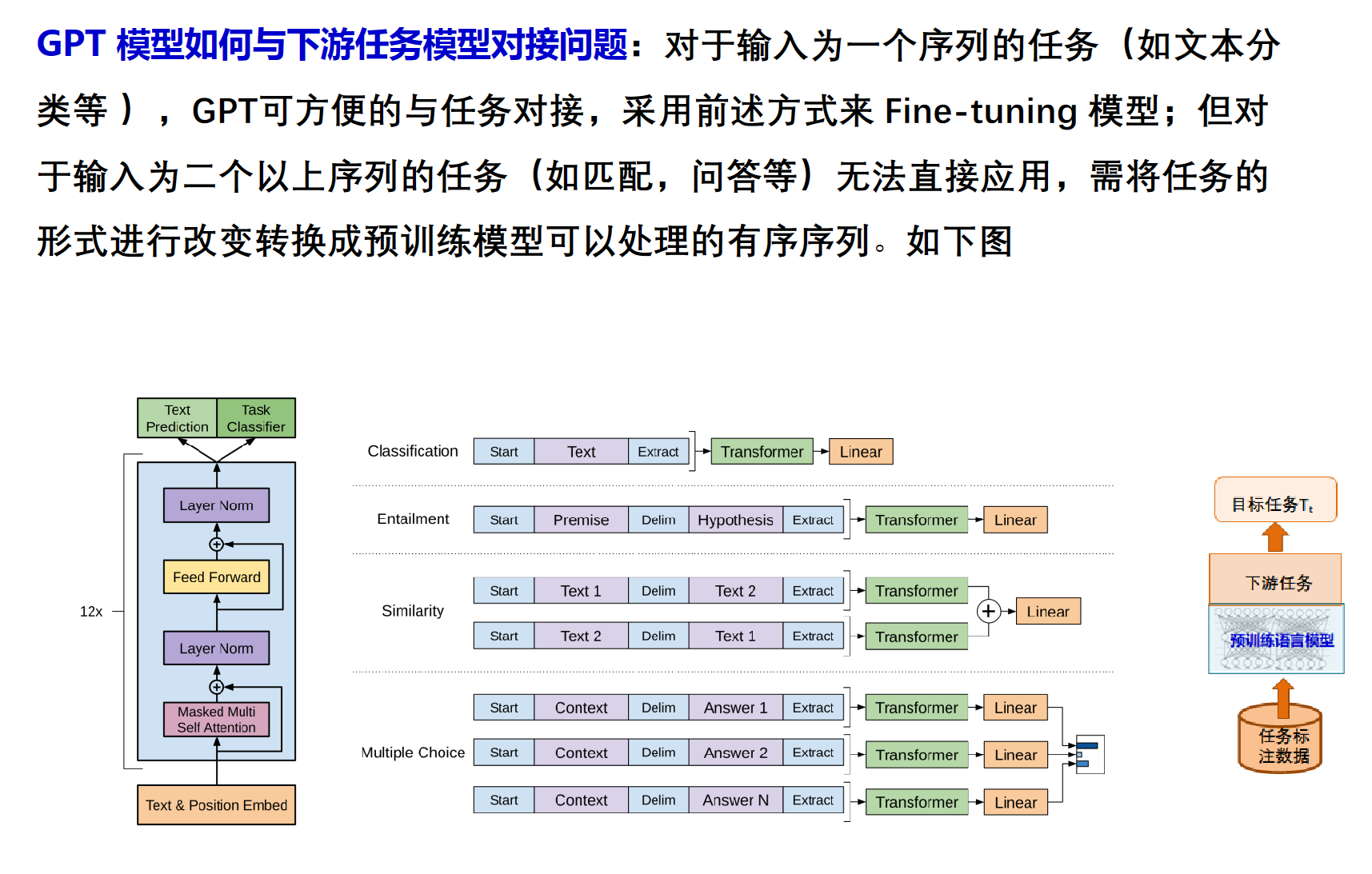
把多序列通过一些特定的规则拼成一个单序列。

微调:
任务微调有2种方式 :① 只调任务参数 ② 任务参数和预训练模型参数一起调,这样可以让预训练模型更加适配任务
举例:

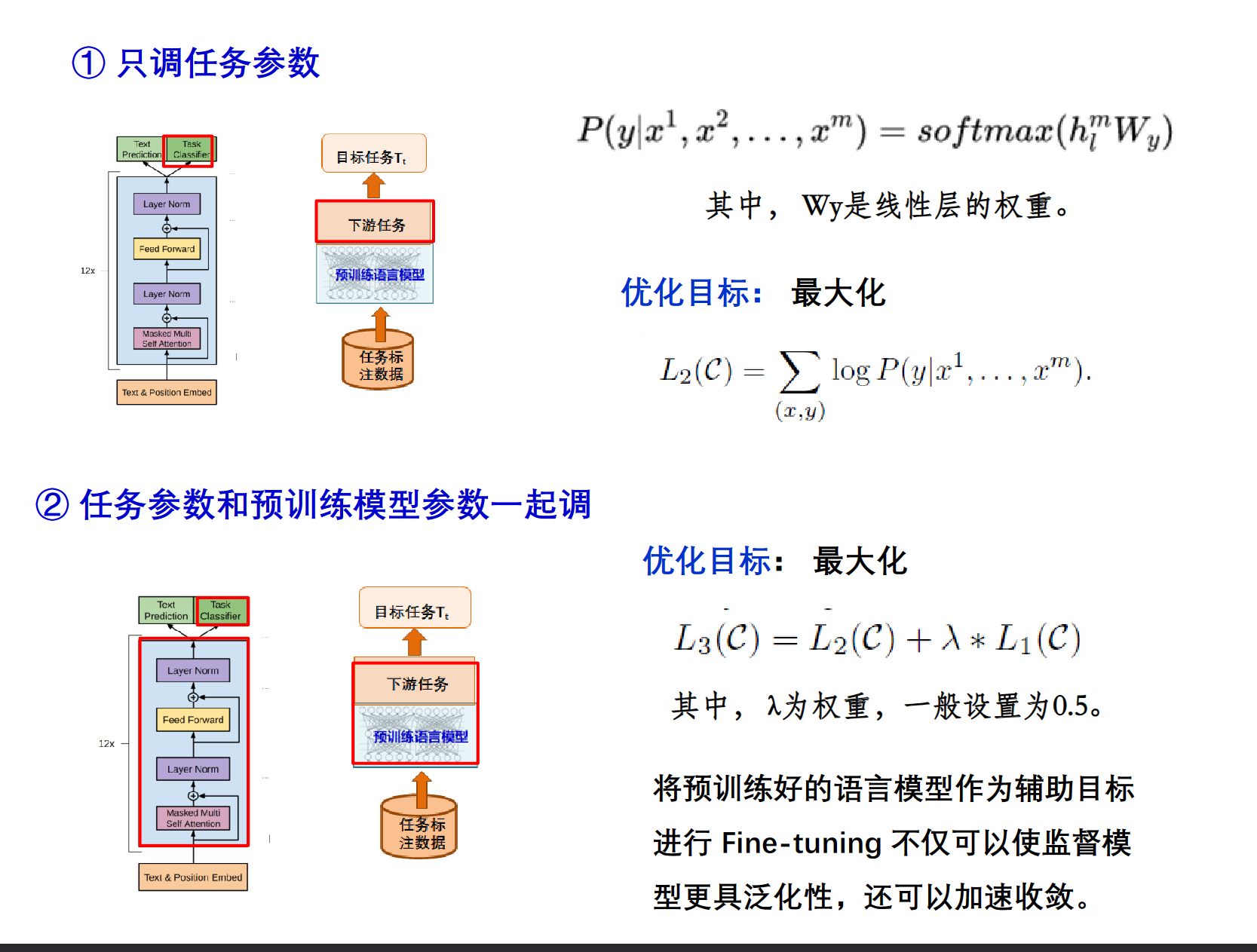
这儿的$L_1(C)$是上面提到的预训练过程中的
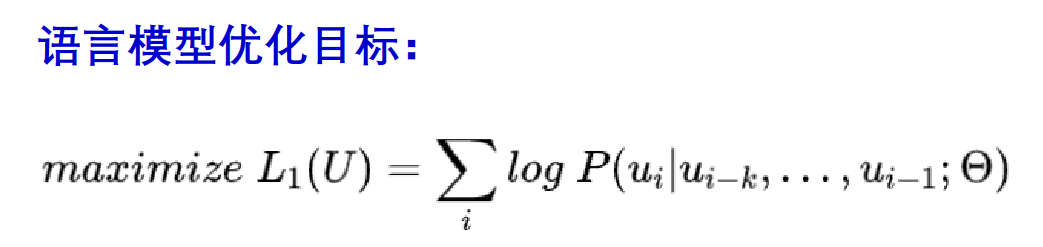
BERT训练和对接
用了transformer的encoder再加FFN(前馈神经网络,FFN 层有助于学习序列中的非线性关系和模式)层
【但是transformer的encoder不是带FeedForward吗?】FFN仅在MLM过程中有用,而BERT的最终输出是模型在整个预训练过程中学到的表示的某种组合。这些表示在后续的任务中可以进一步微调或者用作特征。(BYD,原来只是训练过程中的一个b东西)
下图中一个trm是一个子层,
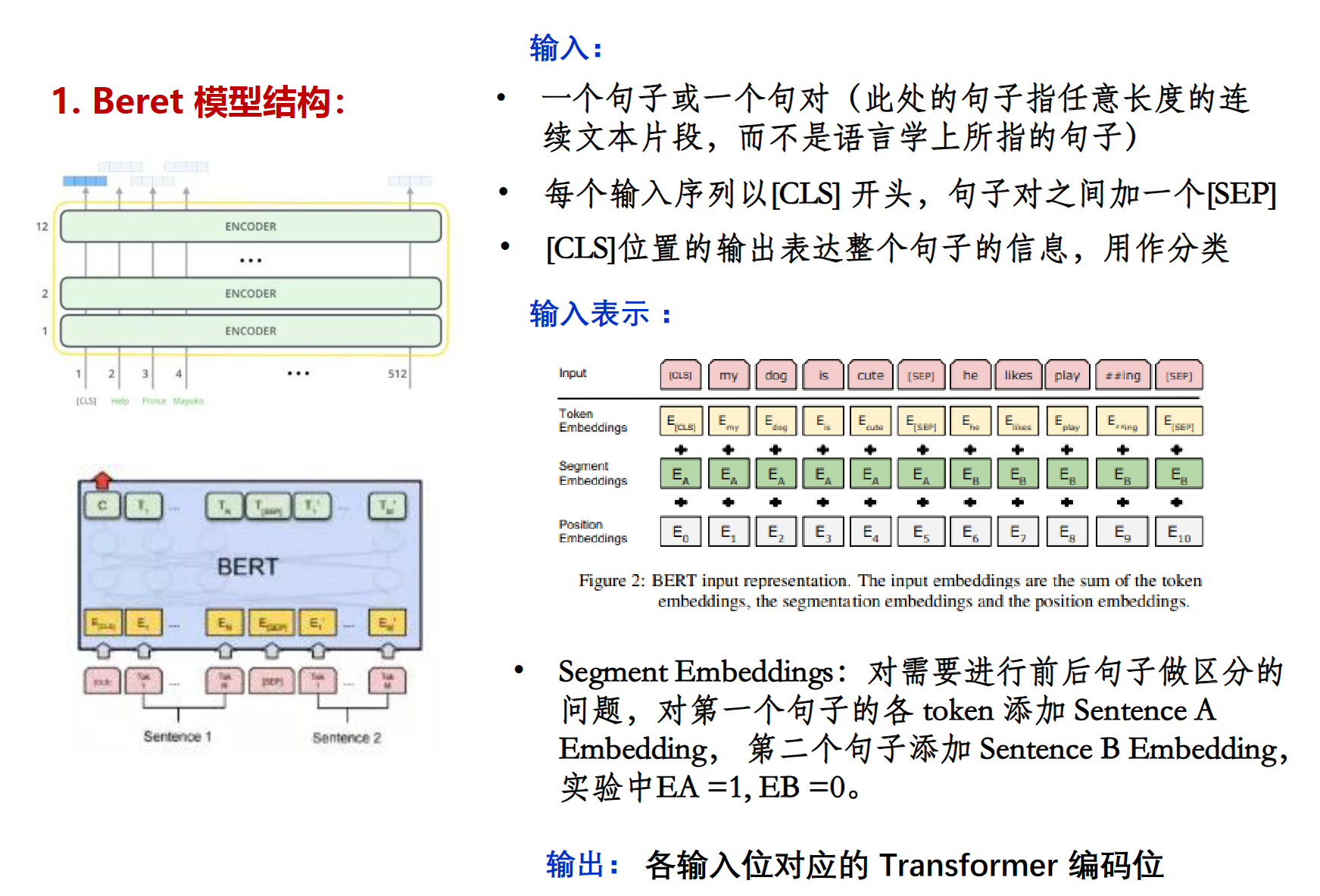
在BERT模型中,输入的每个单词都会通过三种嵌入(embedding)进行编码
Token Embedding:是将每个单词或者词片映射到一个向量,这个向量能够捕获该单词的语义信息。在BERT中,使用了WordPiece标记化,其中输入句子的每个单词都被分解成子词标记。这些标记的嵌入是随机初始化的,然后通过梯度下降进行训练。
Segment Embedding:是用来区分不同的句子的。在处理两个句子的任务(如自然语言推理)时,BERT需要知道每个单词属于哪个句子。
Position Embedding:由于Transformer模型并没有像循环神经网络那样的顺序性,因此需要显式地向模型添加位置信息,以保留句子中单词的顺序信息
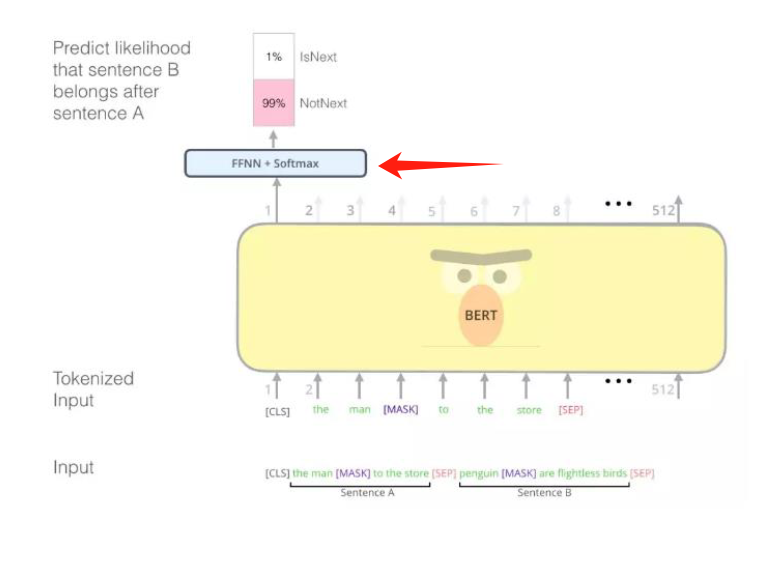
训练:

MLM:把一个序列的几个word给mask了让模型猜的训练方法。

(2).句子顺序模型训练
凑一些下一句不是下一句的负样本来训练预训练模型对句子顺序的敏感。

对接:
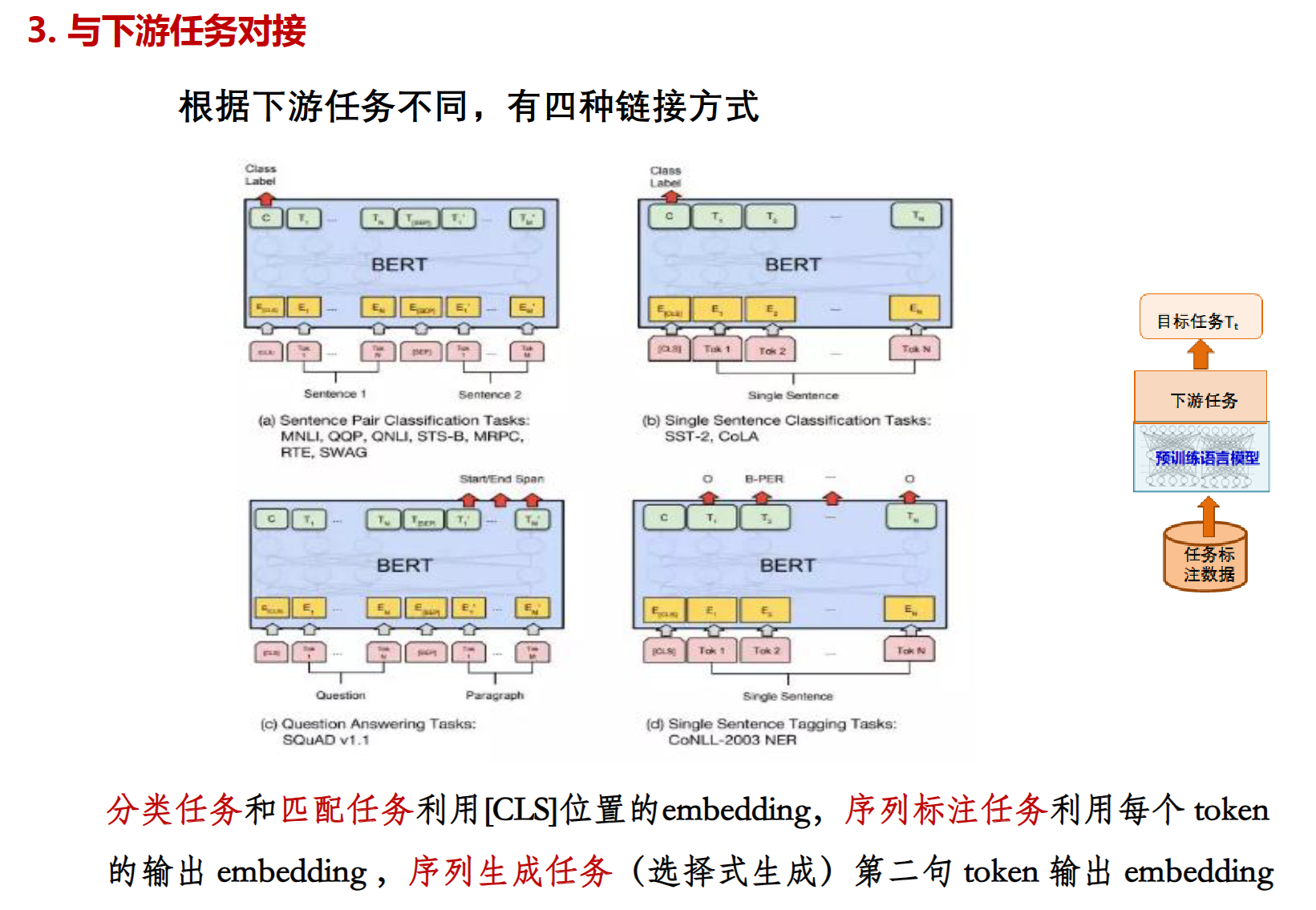
微调同样有两种① 只调任务参数 ② 任务参数和预训练模型参数一起调,这样可以让预训练模型更加适配任务
其他
RoBERTa:把BERT使用Adam默认的参数改为使用更大的batches,训练时把静态mask改为动态mask。

BART:GPT只用了transformer的decoder,BERT只用了transformer的encoder。导致
BERT具备双向语言理解能力的却不具备做生成任务的能力。GPT拥有自回归特性的却不能更好的从双向理解语言.
(模型的"自回归"特性指的是,当前的观察值是过去观察值的加权平均和一个随机项)
BART使用标准的Transformer结构为基础,吸纳BERT和GPT的优点,使用多种噪声破坏原文本,再将残缺文本通过序列到序列的任务重新复原(降噪自监督)

BERT在预测时加了额外的FFN, 而BART没使用FFN.
(还记得这个Beyond吗)
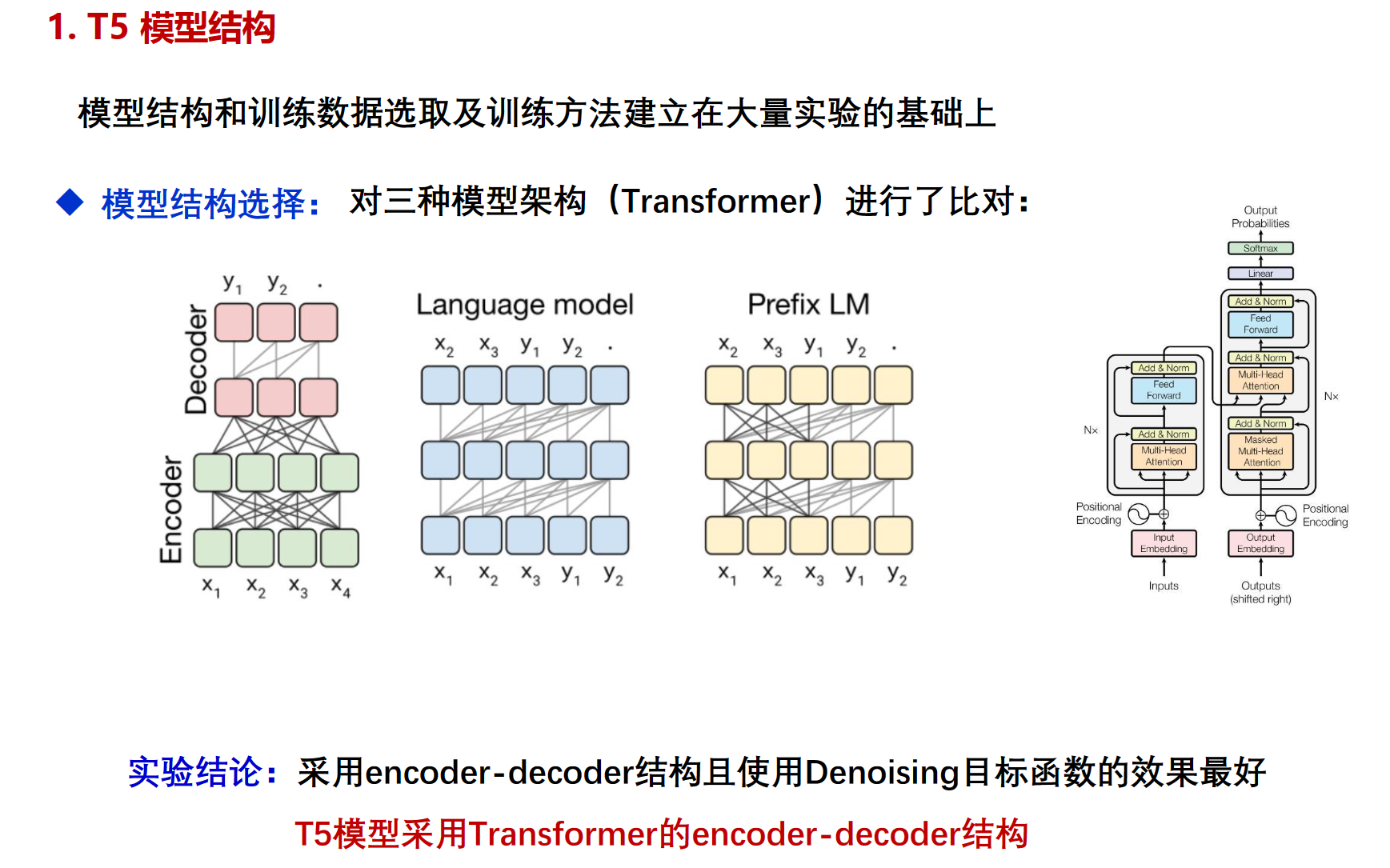
T5
给整个 NLP 预训练模型领域提供了一个通用框架,把所有NLP任务都转化成一种形式(Text-to-Text),通过这样的方式可以用同样的模型,同样的损失函数,同样的训练过程,同样的解码过程来完成所有 NLP 任务。以后的各种NLP任务,只需针对一个超大预训练模型,考虑怎么把任转换成合适的文本输入输出。


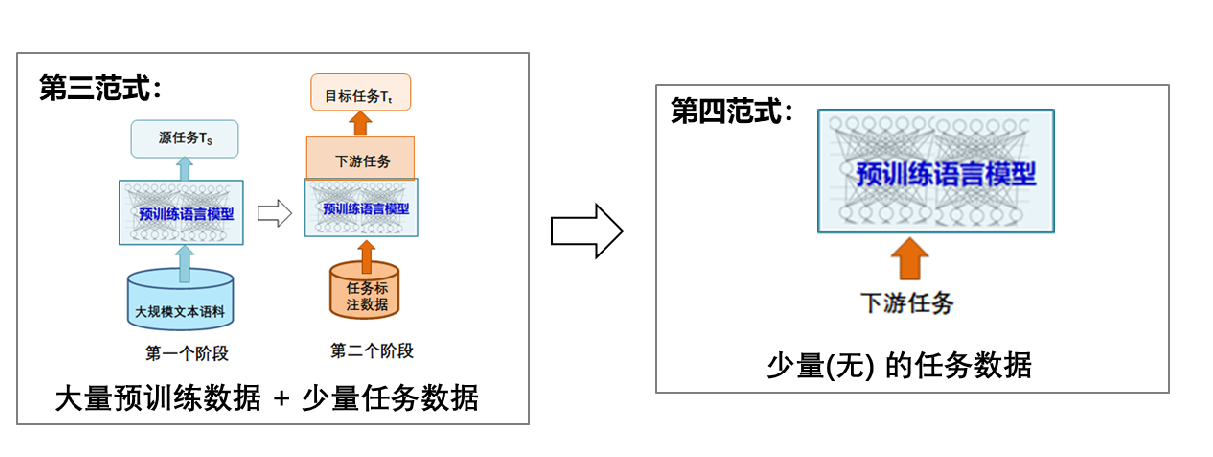
第四范式:预训练,提示,预测范式(Pre-train,Prompt,Predict)
prompt挖掘工程
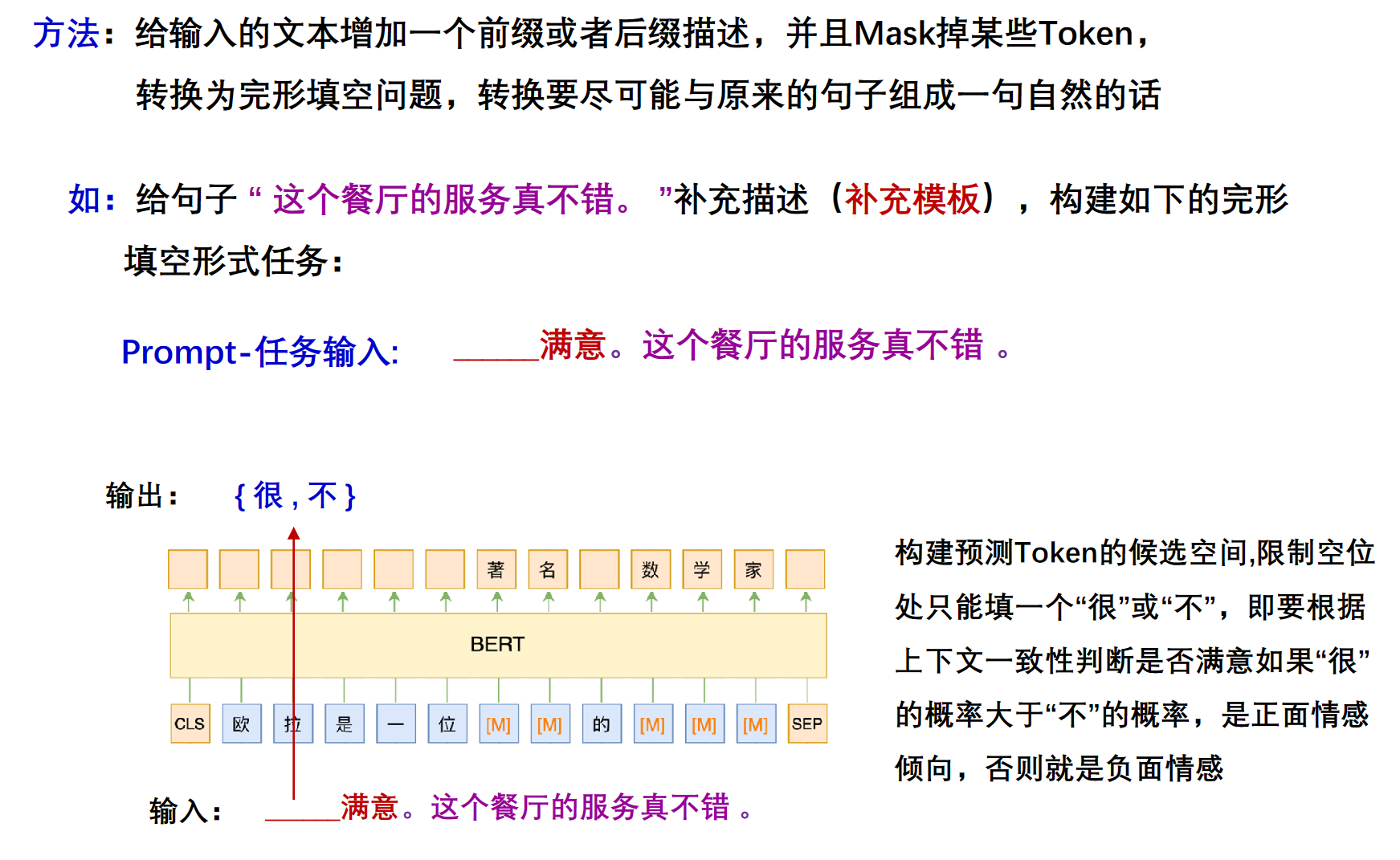
特点:不通过目标工程使预训练的语言模型(LM)适应下游任务,而是将下游任务建模的方式重新定义(Reformulate),通过利用合适prompt实现不对预训练语言模型改动太多,尽量在原始 LM上解决任务的问题。
实现方法eg:




要素:

输入端
prompt工程
完形填空和前缀提示


模板创建

输出端

方法

微调

生成类任务用法与第五范式相同
第五范式:大模型
大语言模型 (Large Language Model,LLM) 通常指由大量参数(通常数十亿个权重或更多)组成的人工神经网络预训练语言模型,使用大量的计算资源在海量数据上进行训练。
大型语言模型是通用的模型,在广泛的任务(例如情感分析、命名实体识别或数学推理)中表现出色,具有与人类认证对齐的特点。

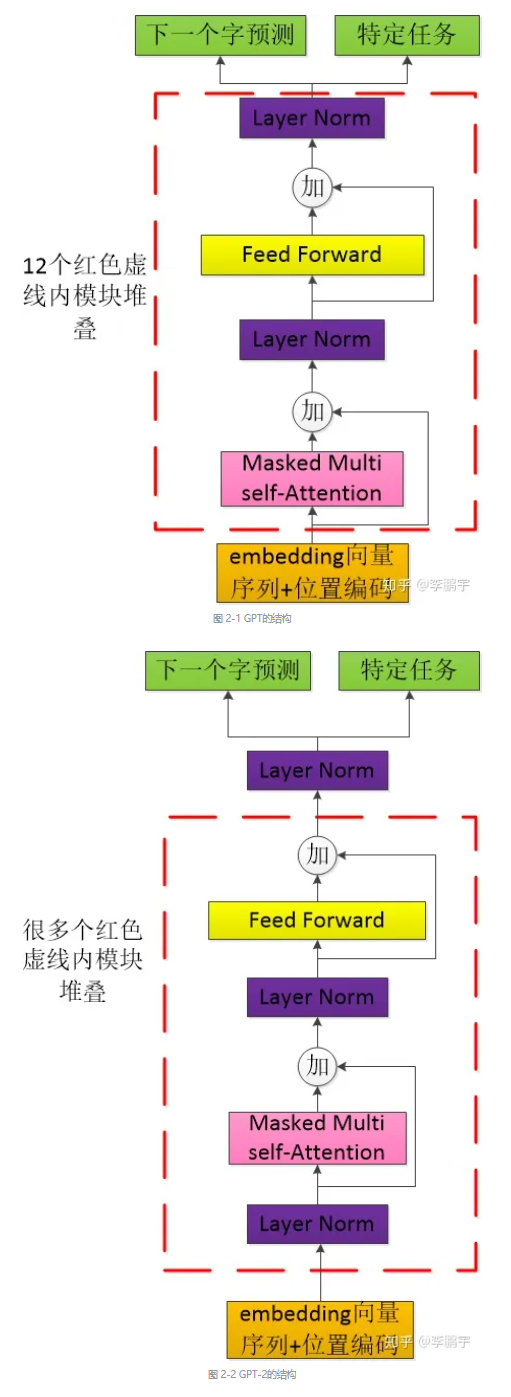
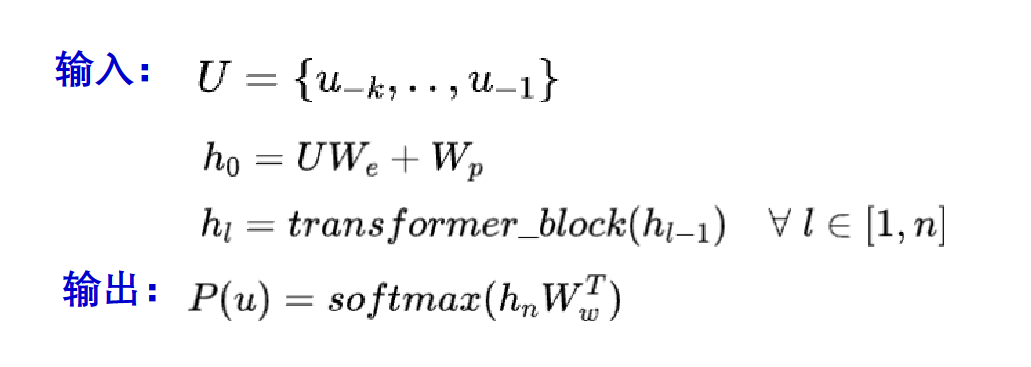



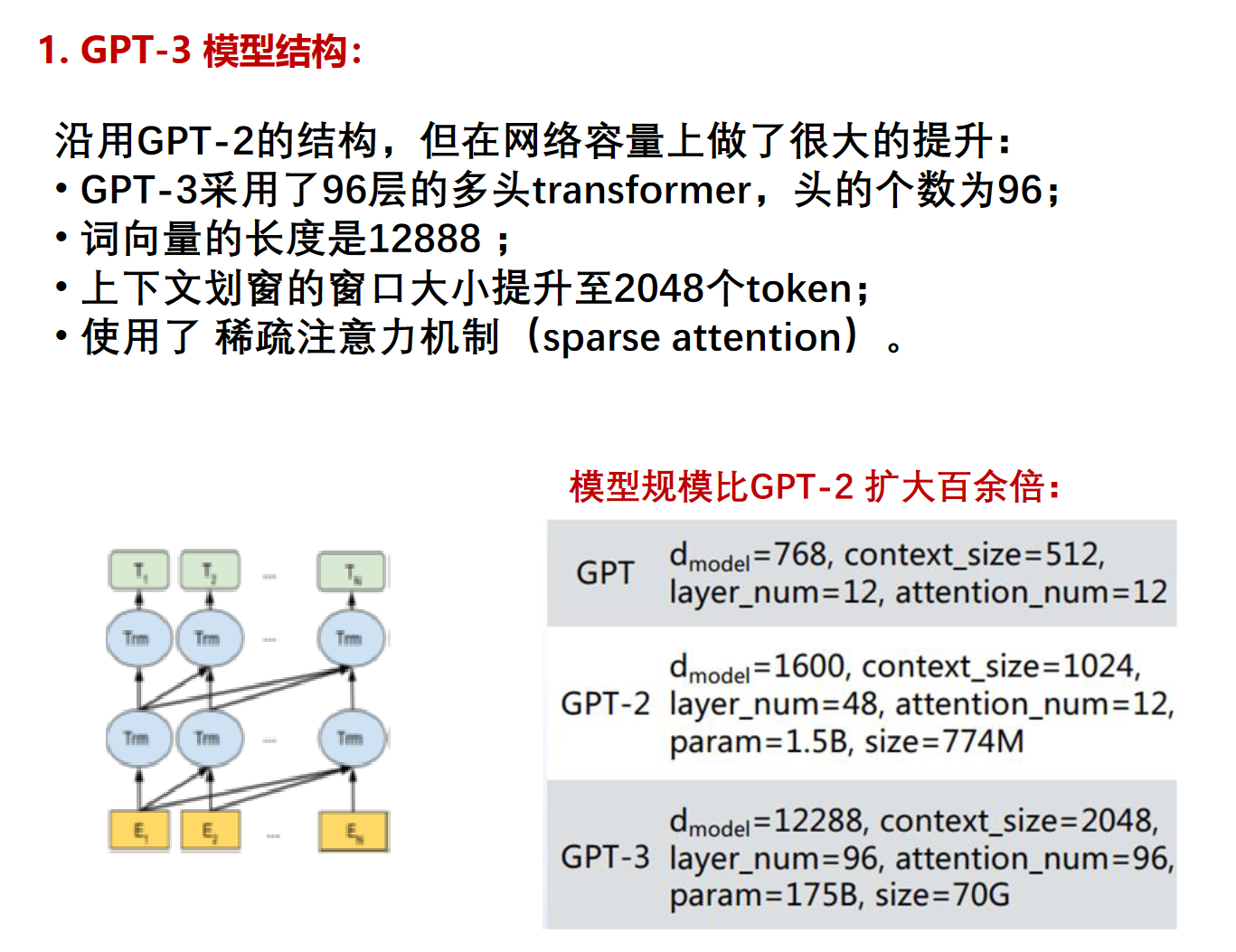
不需要任务模型的意思是只要有预训练就行
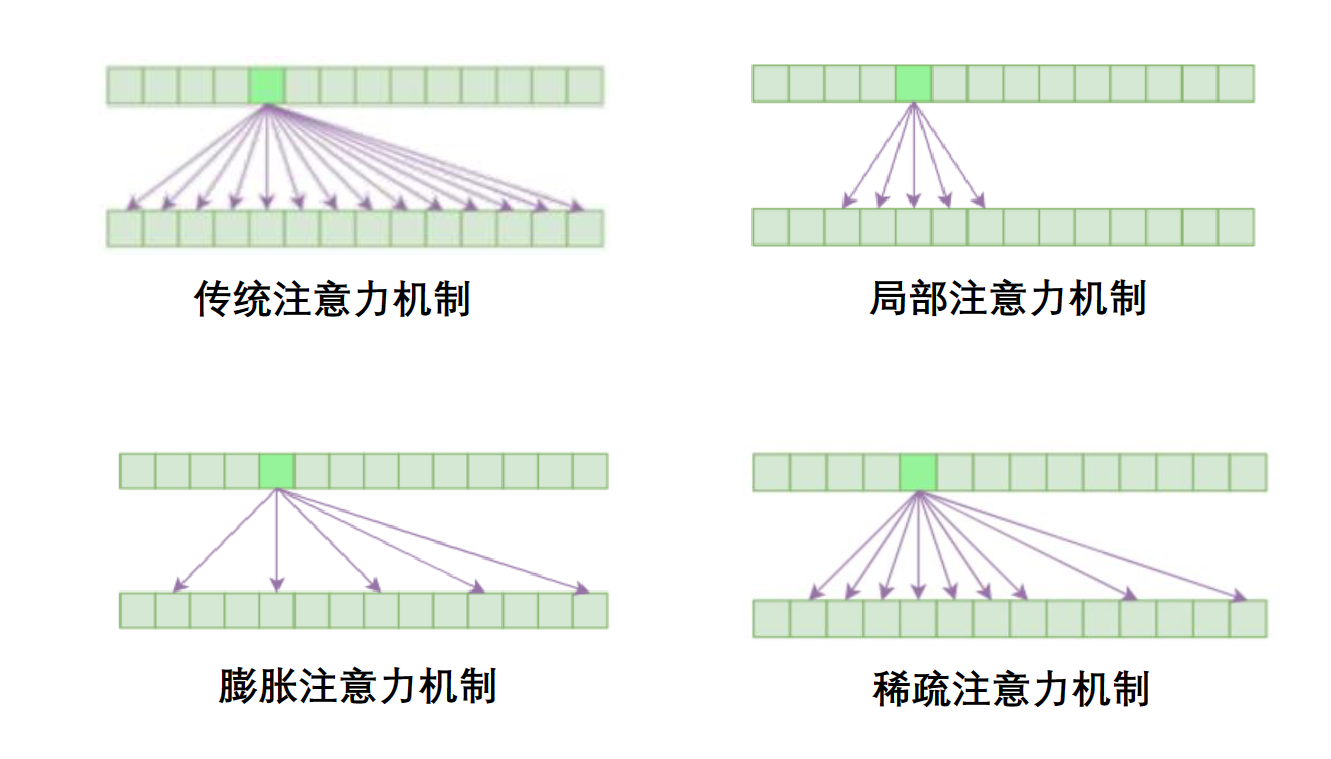
(我靠,这要传统注意力算死了)
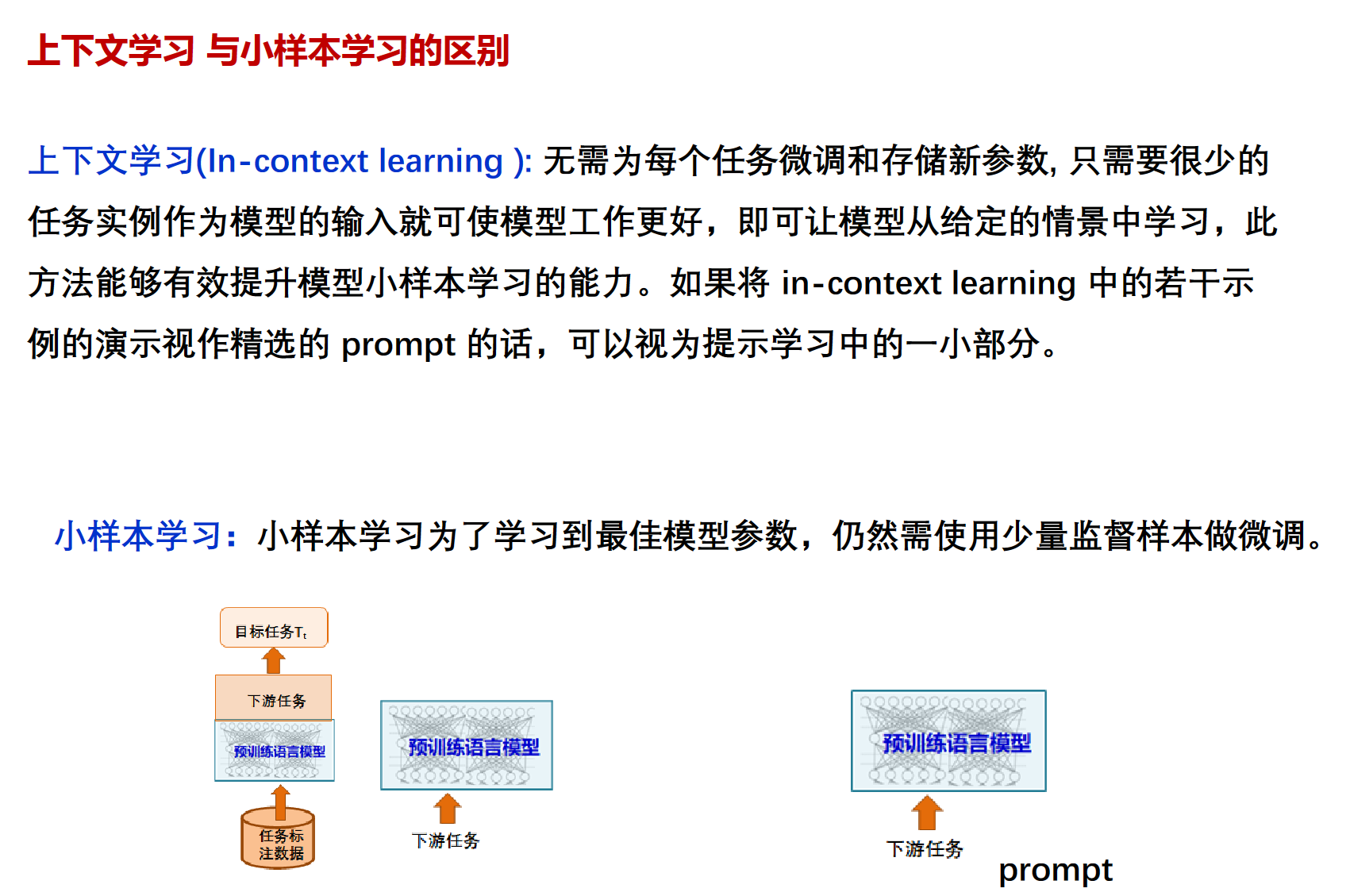
学习方法

因为上下文学习,在使用的时候也可以用zero-shot, one-shot和few-shot。

chain-of-thought


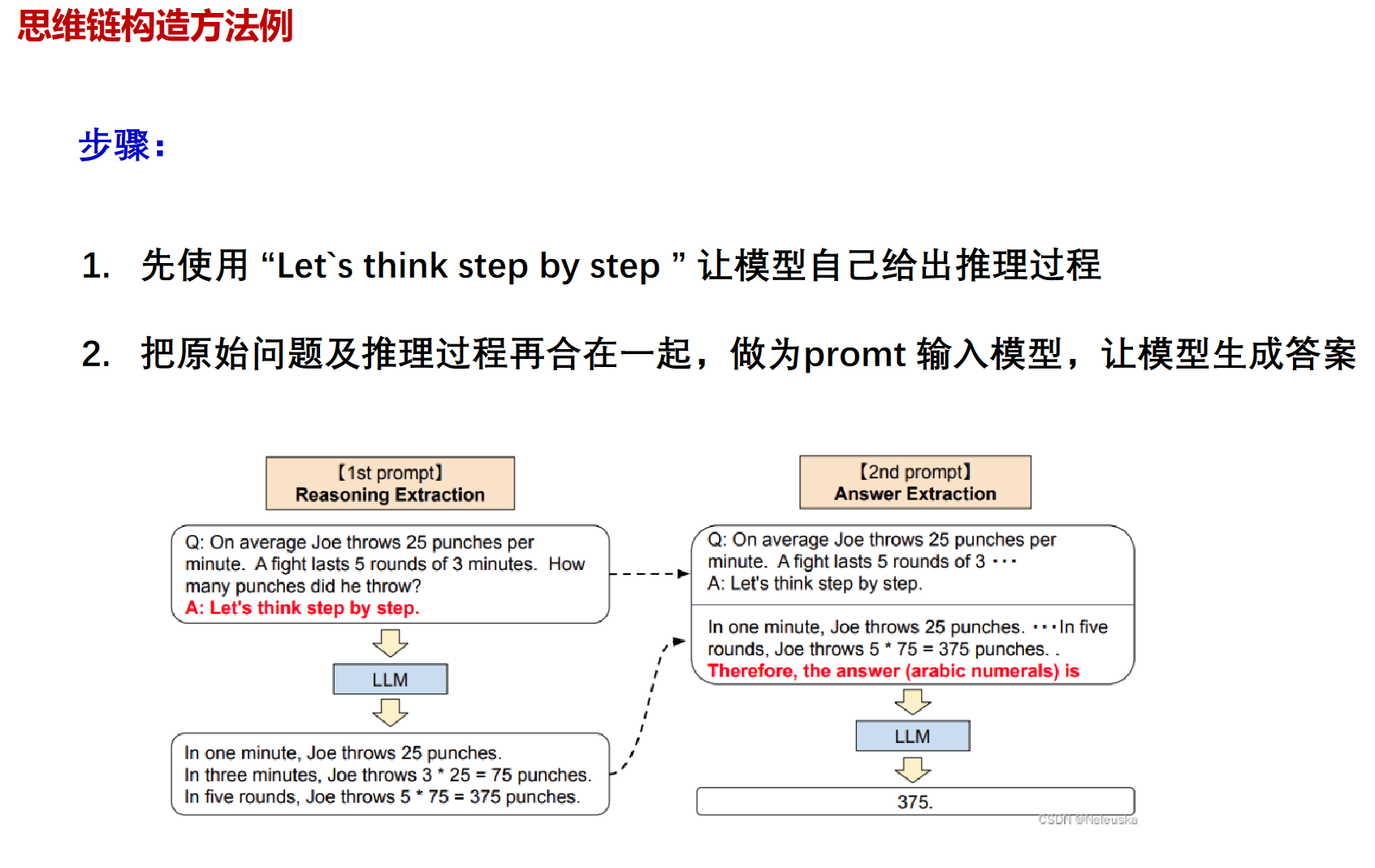


与人类对齐:RLHF
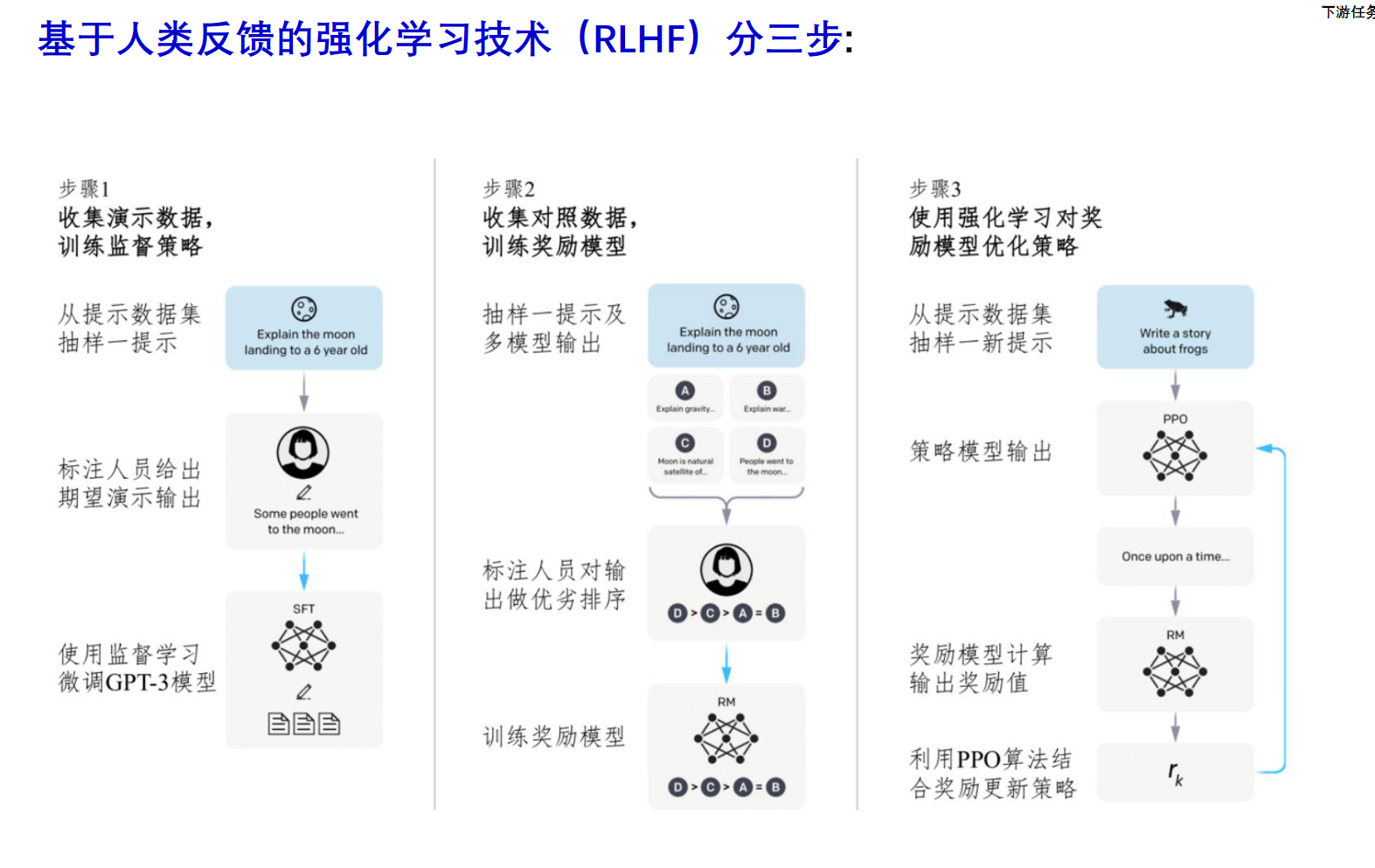
简而言之:1、在人工标注数据上SFT(有监督微调)模型
2、多模型给标注人员做排序,用来训练奖励模型(RM)
3、使用强化学习PPO算法,交互地优化模型参数。

文本分类在各个范式上的例子

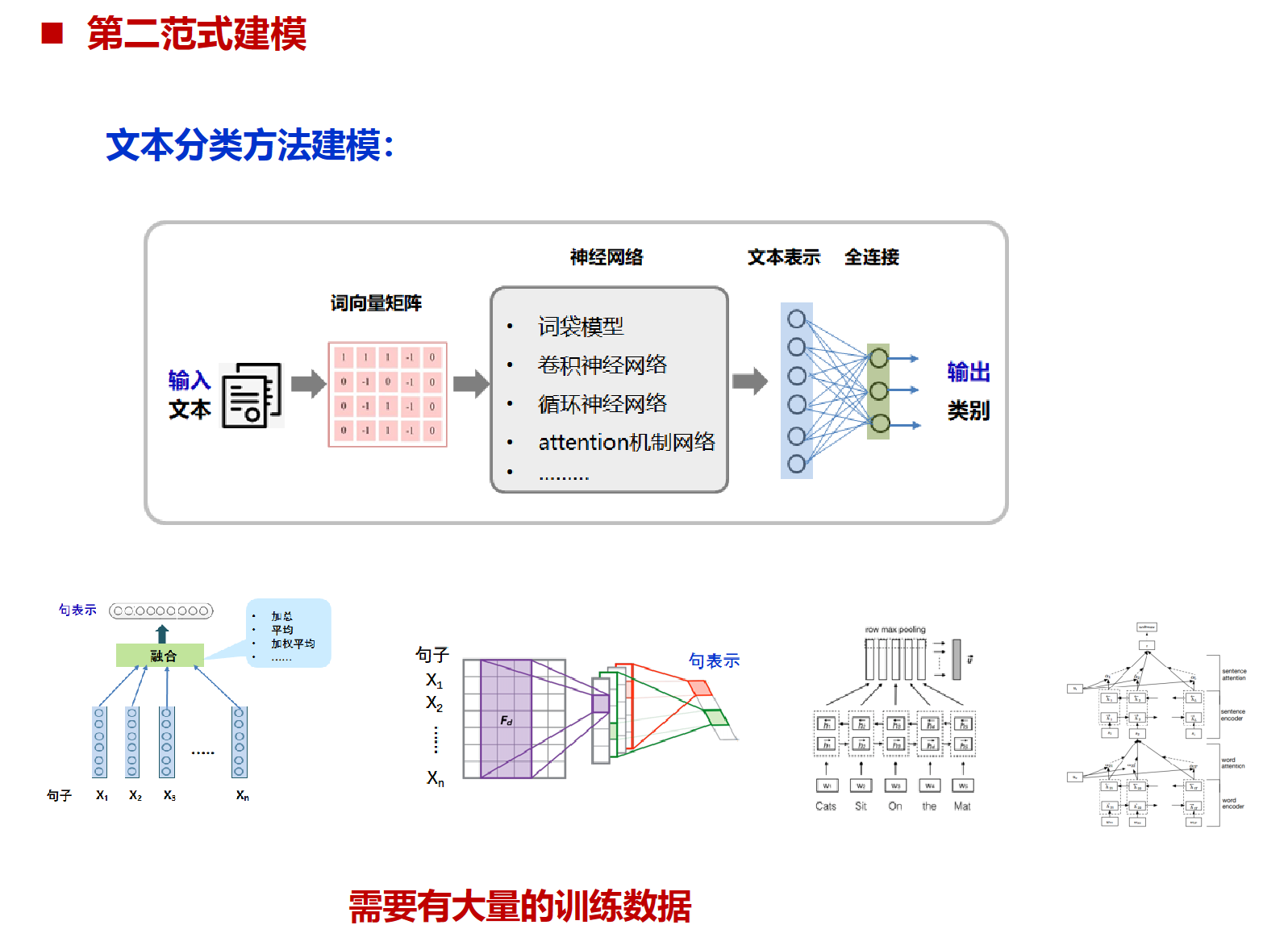

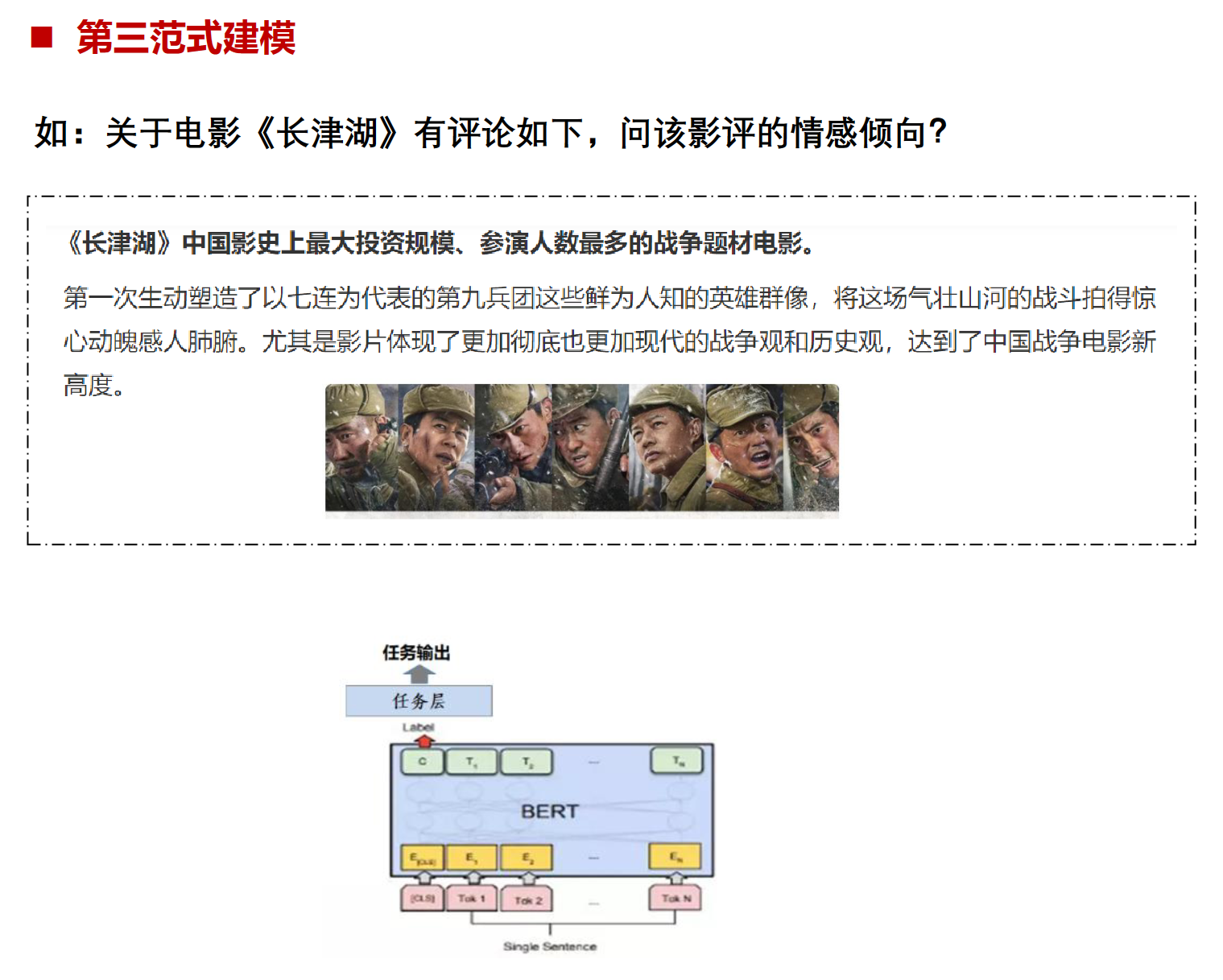


方面级情感分类
方面级情感分类(Aspect-Level Sentiment Classification)是自然语言处理(NLP)中的一个任务,它的目标是识别文本中特定方面的情感倾向。例如,在产品评论中,“这款手机的电池寿命很长,但屏幕质量差。”这句话中,“电池寿命”这个方面的情感是积极的,而“屏幕质量”这个方面的情感是消极的。所以,方面级情感分类不仅要识别出文本中的各个方面,还要判断这些方面的情感倾向。这个任务在许多领域都有应用,比如产品评论分析、社交媒体监控等。


问题定义


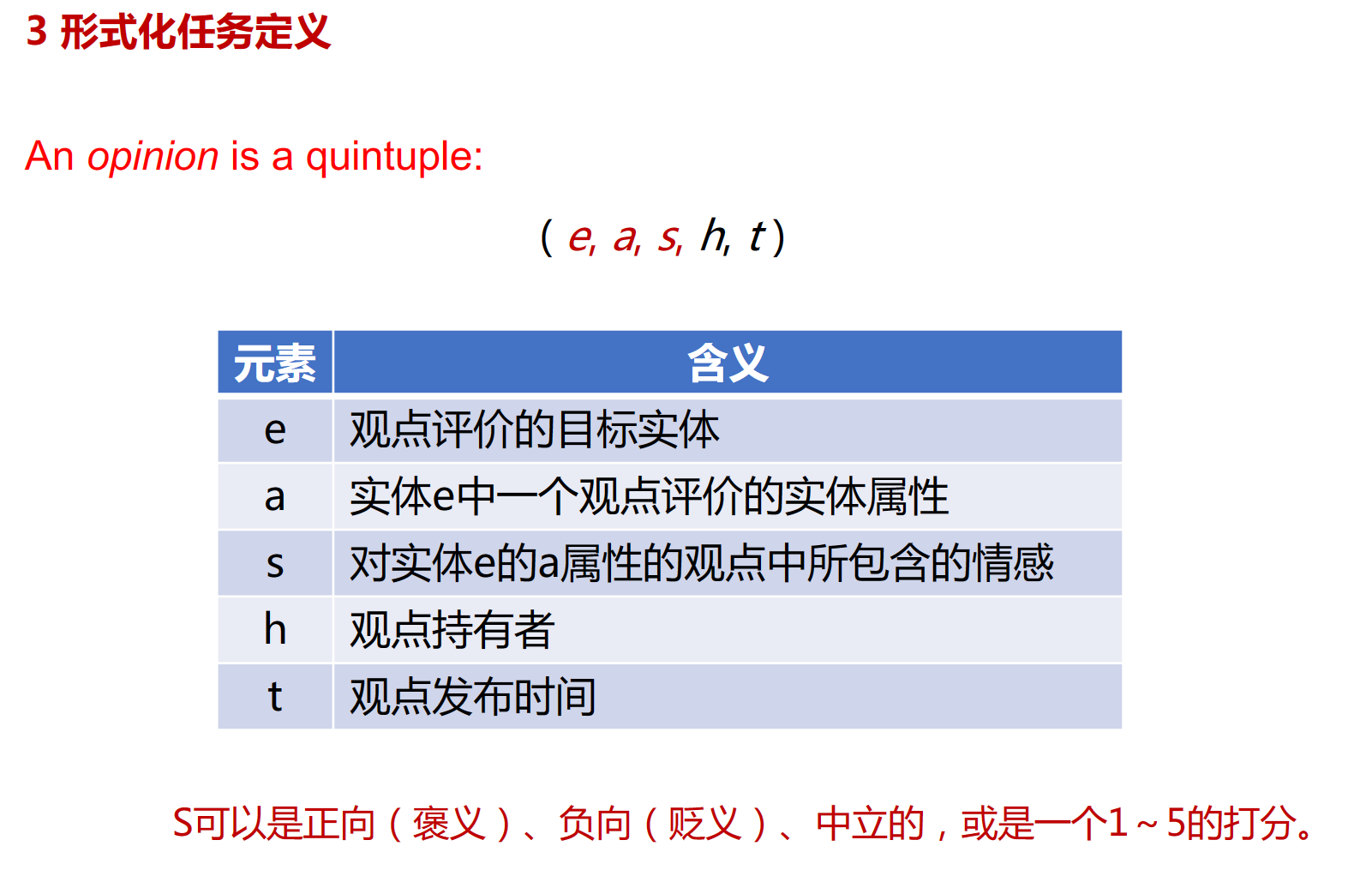
基本方法、原理
子任务等:
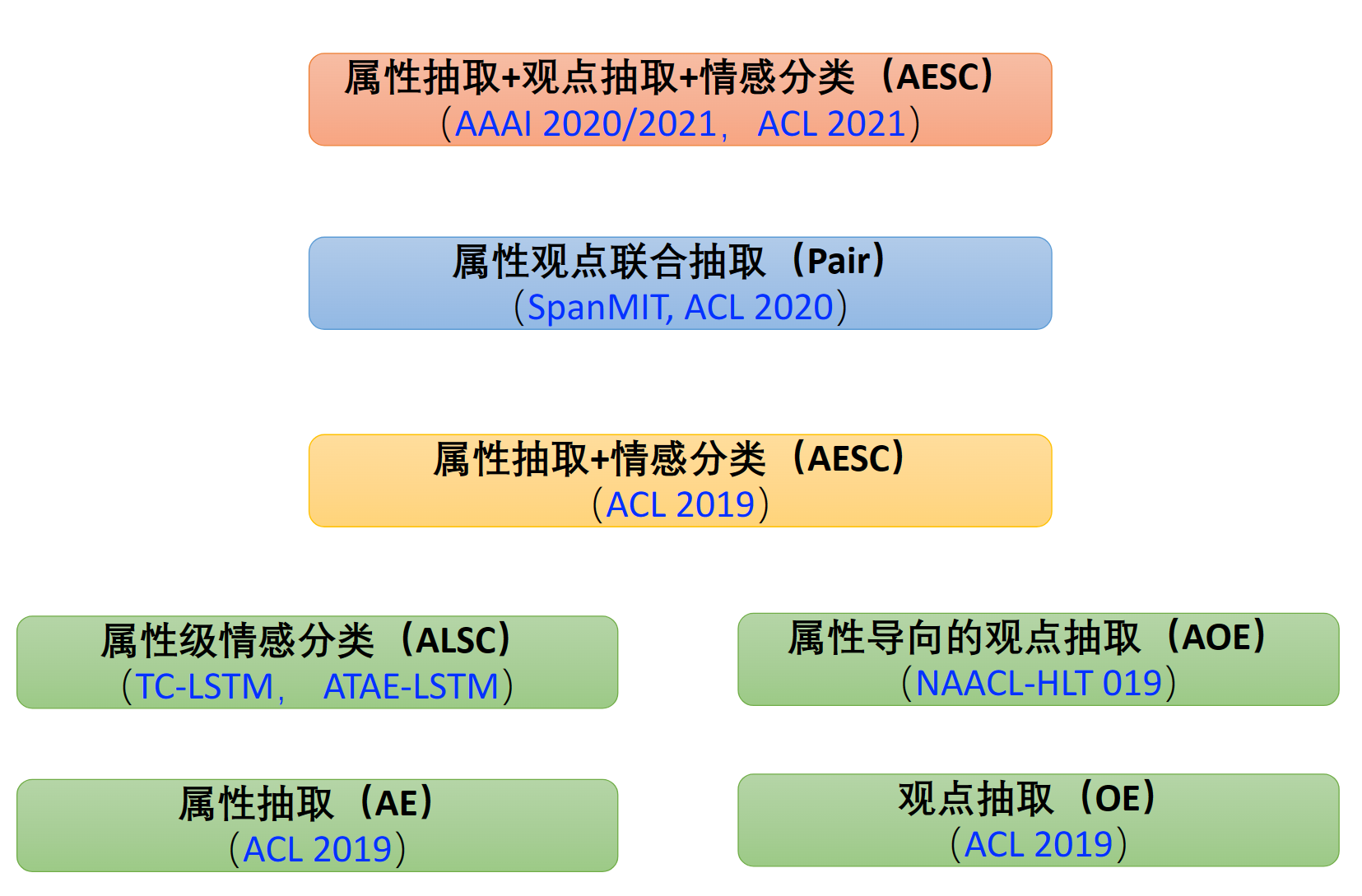
-
Entity/Target:评论的对象或者物品是什么,例如某个餐厅,某款手机。“Target"这个词用的比较模糊,其既可以被当作Entity,又可以当作Aspect Term。和在AE里提到的opinion target是一个意思。
-
Aspect:隶属于某个Entity的属性。在这里其因为学者提出的任务类型不同,又分为两类:
- Aspect Term:存在在句子中的Aspect。例如例句中的”拍照“、”电池“、”外观“。
- Aspect Category:预先给定的Aspect。例如,我们想知道评论对”华为手机“的”外观“、”售后服务“、”便携性“三个aspect的情感极性。
LSTM
LSTM 方法先将所有变长的句子均表示为一种固定长度的向量,具体做法是将最后一个word对应的计算得到的 hidden vector 作为整句话的表示(sentence vector)。之后,将最后得到的这个 sentence vector 送入一个 linear layer,使其输出为一个维度为情绪种类个数。最后对 linear layer 得出的结果做 softmax 并依次为依据选出该句(同时也是 target)的情绪分类。
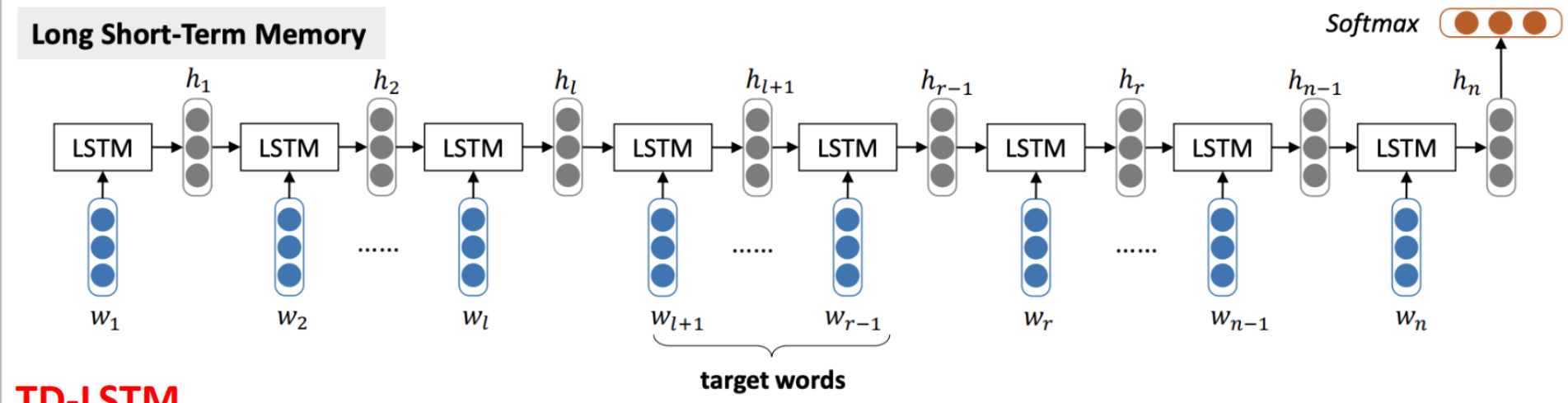
TD-LSTM
将输入的句子根据 aspect 分为两部分,两边都朝着 aspect 的方向分别同时把 words 送入两个 LSTM 中
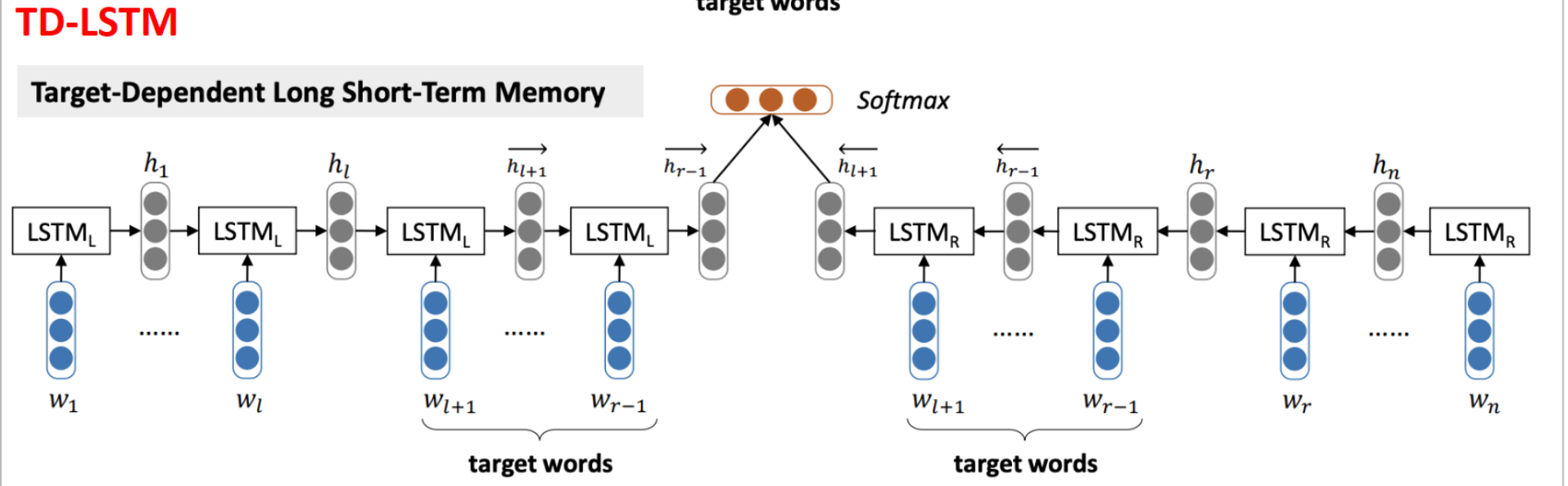
TC-LSTM
与 TD-LSTM 唯一的不同就是在 input 时在每个 word embedding vector 后面拼接上 aspect vector(如果 aspect 中有多个 word,则取平均)
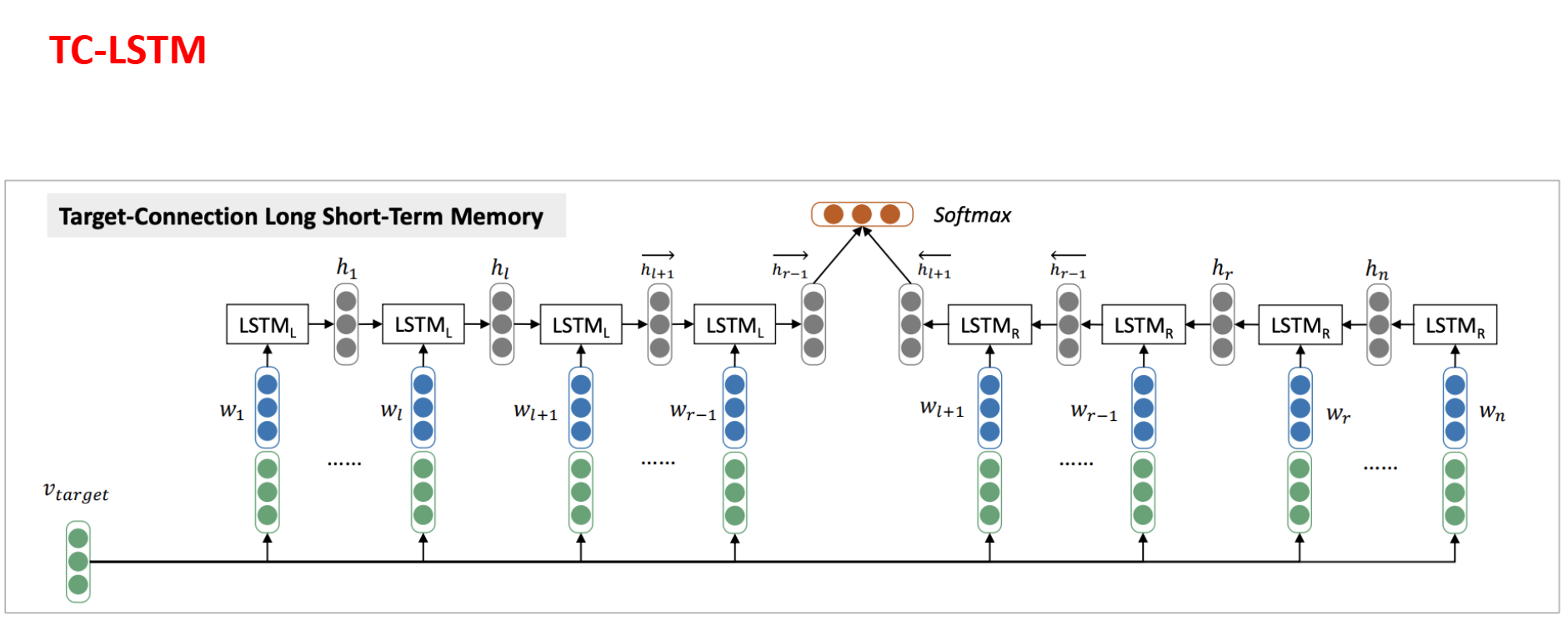
AT-LSTM
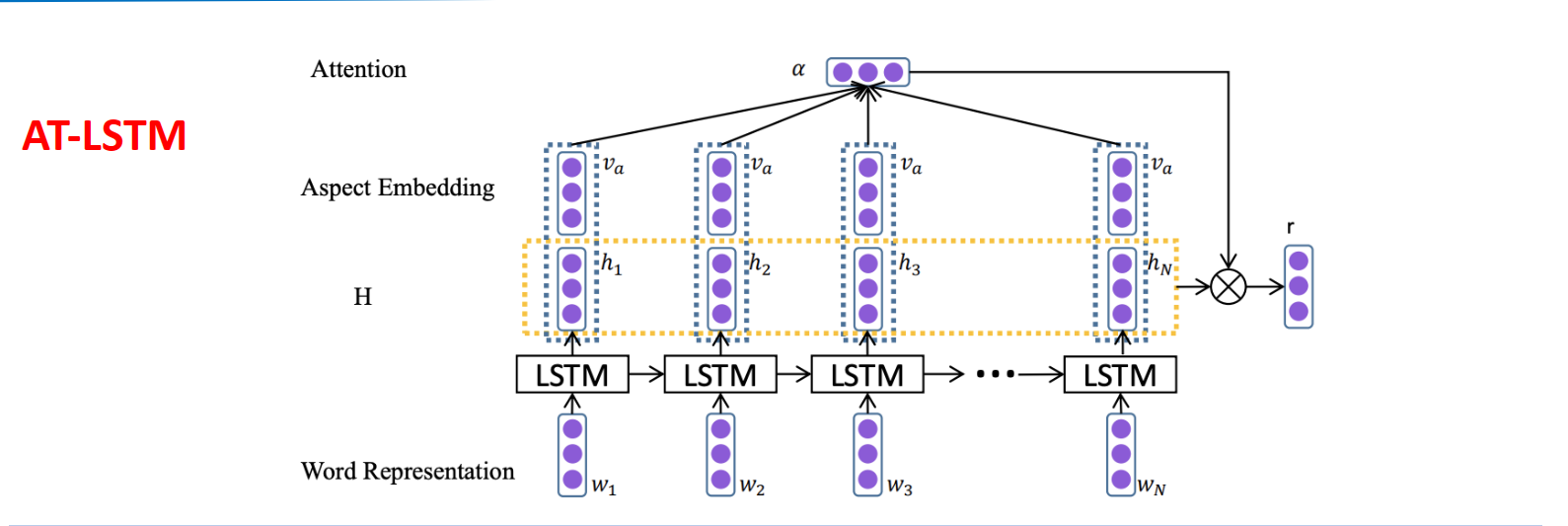
对隐藏状态h和aspect的词嵌入后施加attention
ATAE-LSTM
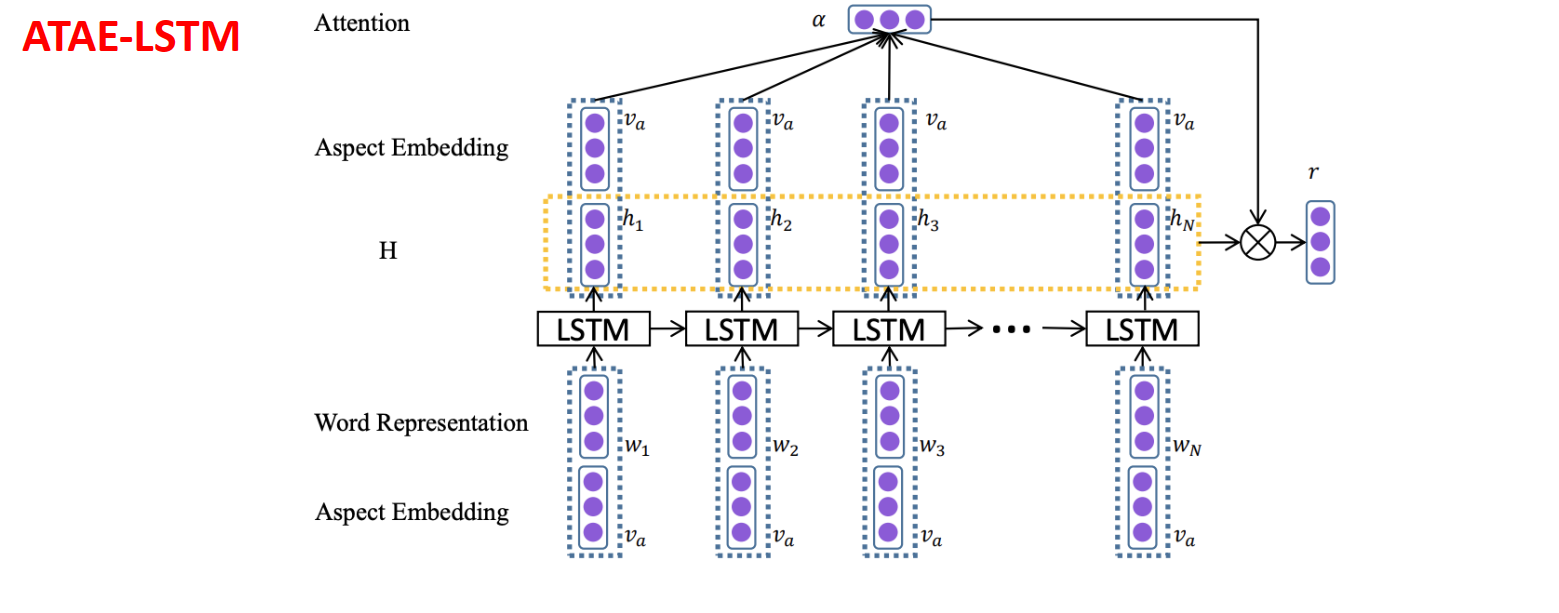
在LSTM的输入方面在concat一个aspect的词向量,说明aspect的重要性
IAN
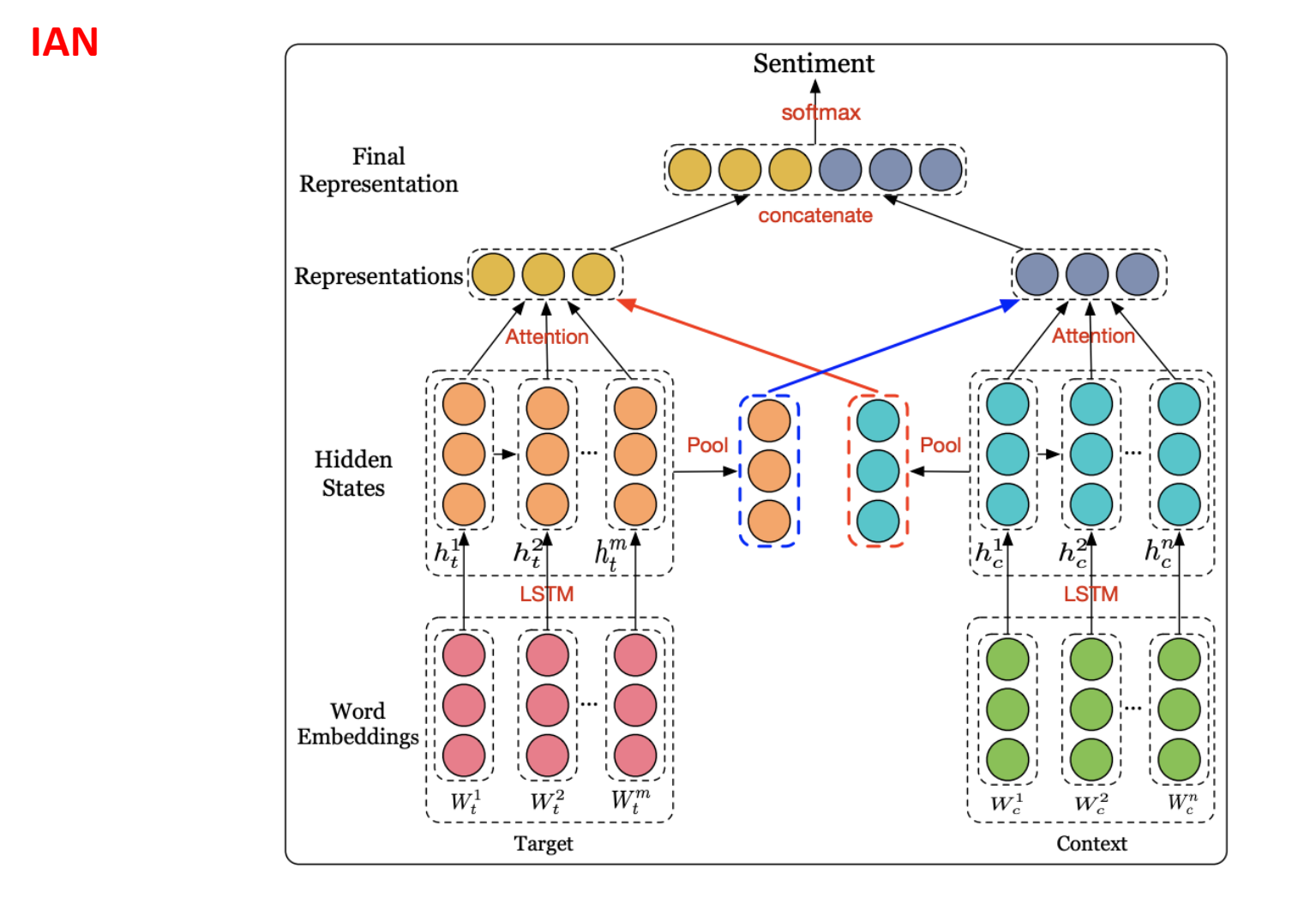
IAN 模型由两部分组成,两部分分别对 Target 和 Context 进行建模。每一部分都以词嵌入作为输入,再通过 LSTM 获取每个词的隐藏状态,最后取所有隐藏向量的平均值,用它来监督另一部分注意力向量的生成。attention学习隐藏状态和对应词向量序列的相关性。
attention部分是$h_t^i$&$avg(h_c)$在target上做注意力,$h_c^i$&$avg(h_t)$在context上做注意力
实体和关系联合抽取
信息抽取:从自然语言文本中抽取指定类型的实体、 关系、 事件等事实信息,并形成结构化数据输出的文本处理技术。一般情况下信息抽取别是知识抽取等其他任务的基础。主要在对无结构数据的抽取出现问题
基本方法原理
名词解释
span:指的是文本中的一段连续的子串,这段子串对应于某个实体或者关系的具体文本表述。
DyGIE
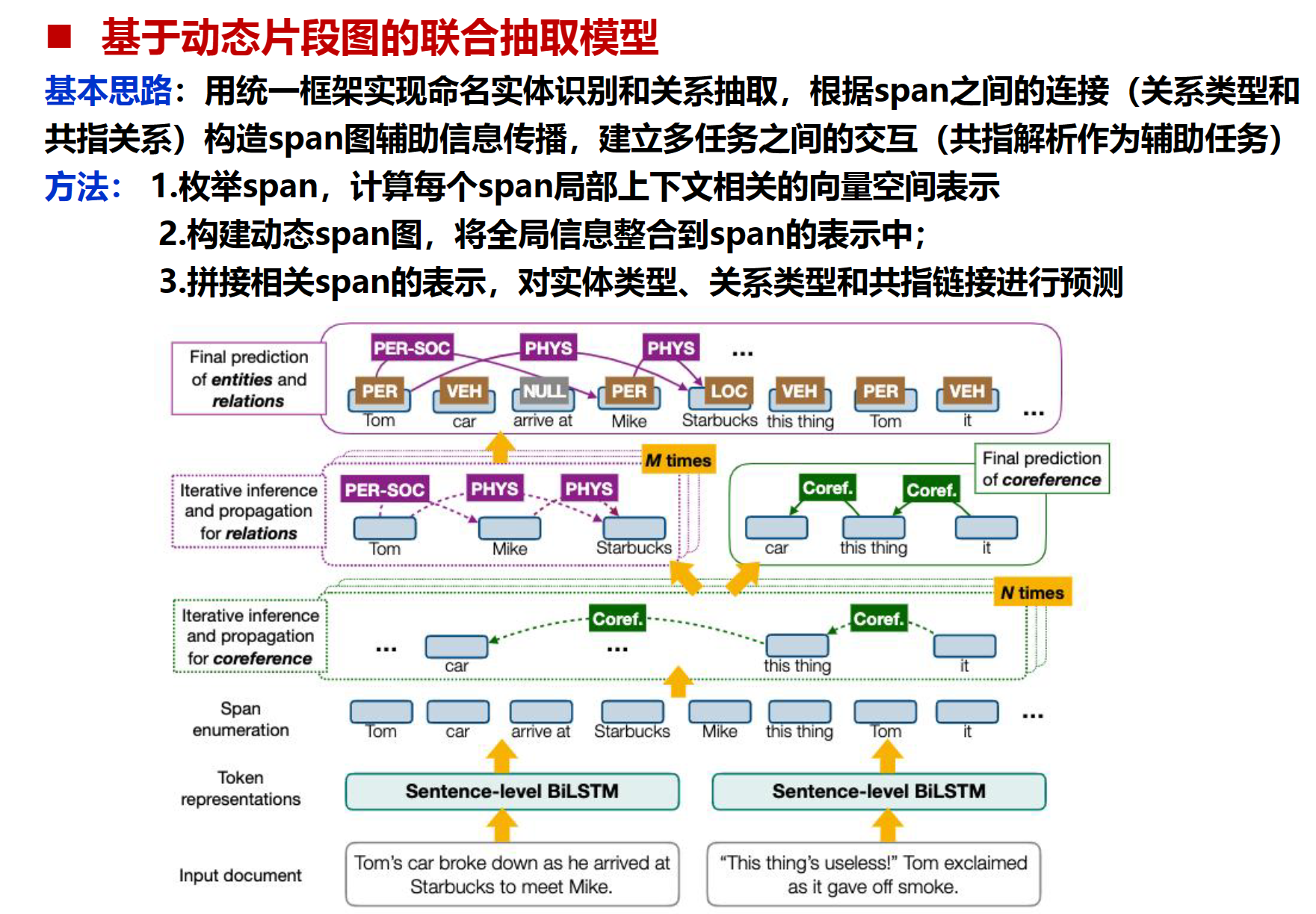
问题定义:
输入:所有句中可能的spans序列集合。
输出三种信息:实体类型,关系分类(同一句),指代链接(跨句);
Token Representation Layer(Token表示层):BiLSTM
Span Representation Layer(span表示层): 初始化来自BiLSTM输出联合起来,加入基于注意力模型。
Coreference Propagation Layer(指代传播层):N次传播处理,跨span共享上下文信息
Relation Propagation Layer(关系传播层):与指代传播层相似
Final Prediction Layer(最终预测层):去预测任务—实体任务,关系任务
OneIE
任务定义:给定一个输入的句子,输出一个图,图中节点(含节点类型)代表实体提及或者触发词,图中的边表示表示节点之间的关系
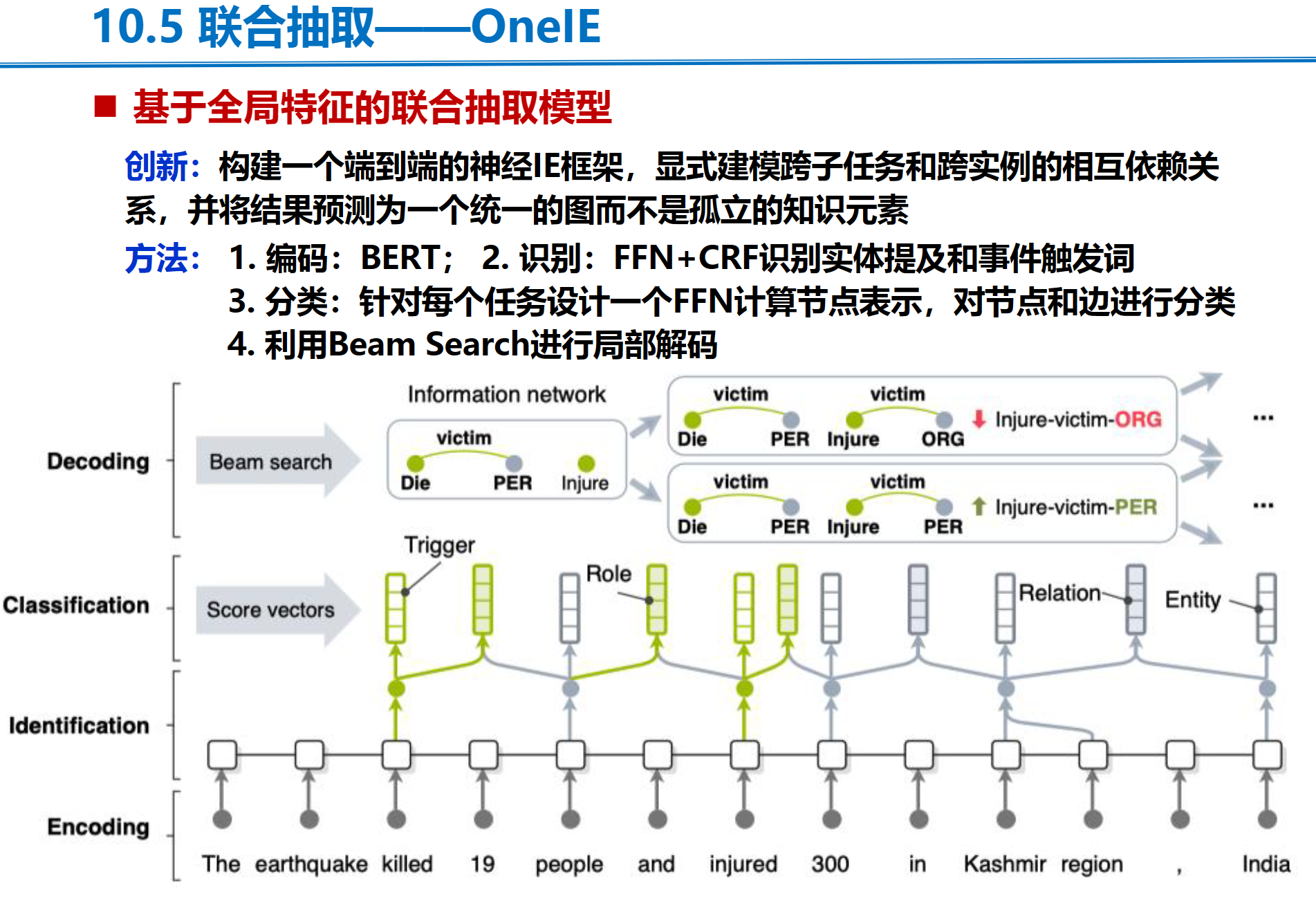
条件随机场(Conditional Random Field,CRF)是一种在自然语言处理(NLP)中广泛使用的模型。CRF的主要作用是解决序列数据的标注问题,它能够考虑整个序列的上下文信息,以做出更准确的预测。
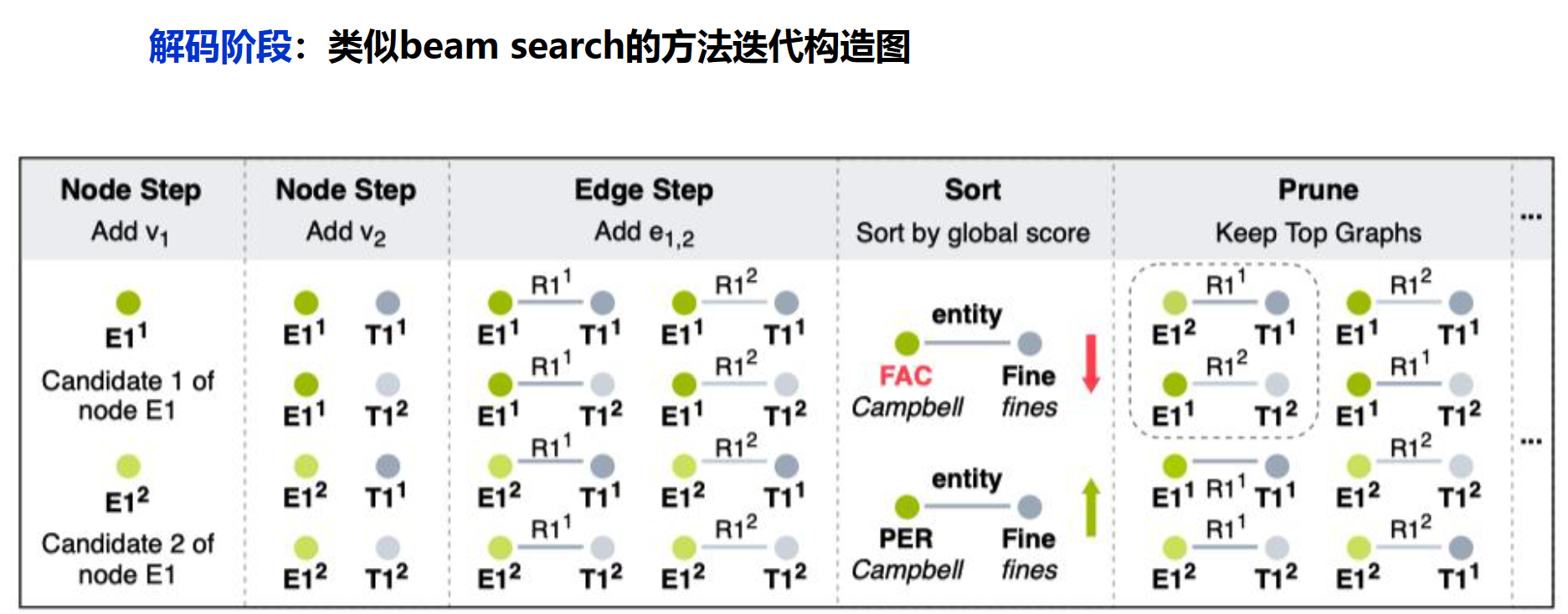
Beam Search(集束搜索)是一种启发式图搜索算法,通常用在图的解空间比较大的情况下,为了减少搜索所占用的空间和时间,在每一步深度扩展的时候,剪掉一些质量比较差的结点,保留下一些质量较高的结点。Beam Search不保证全局最优,但是比greedy search搜索空间更大,一般结果比greedy search要好。
在这里只保留最好的
UIE
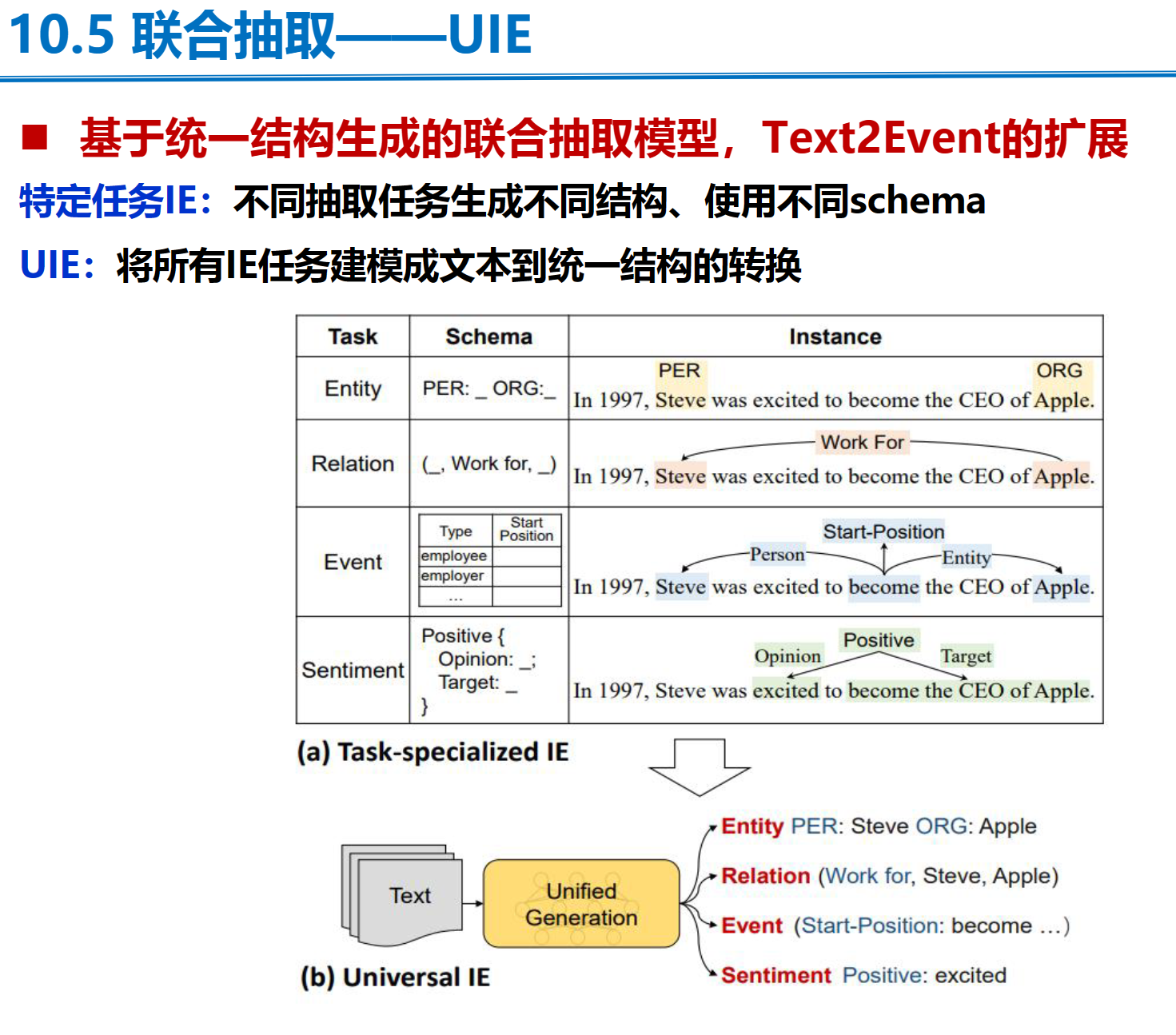
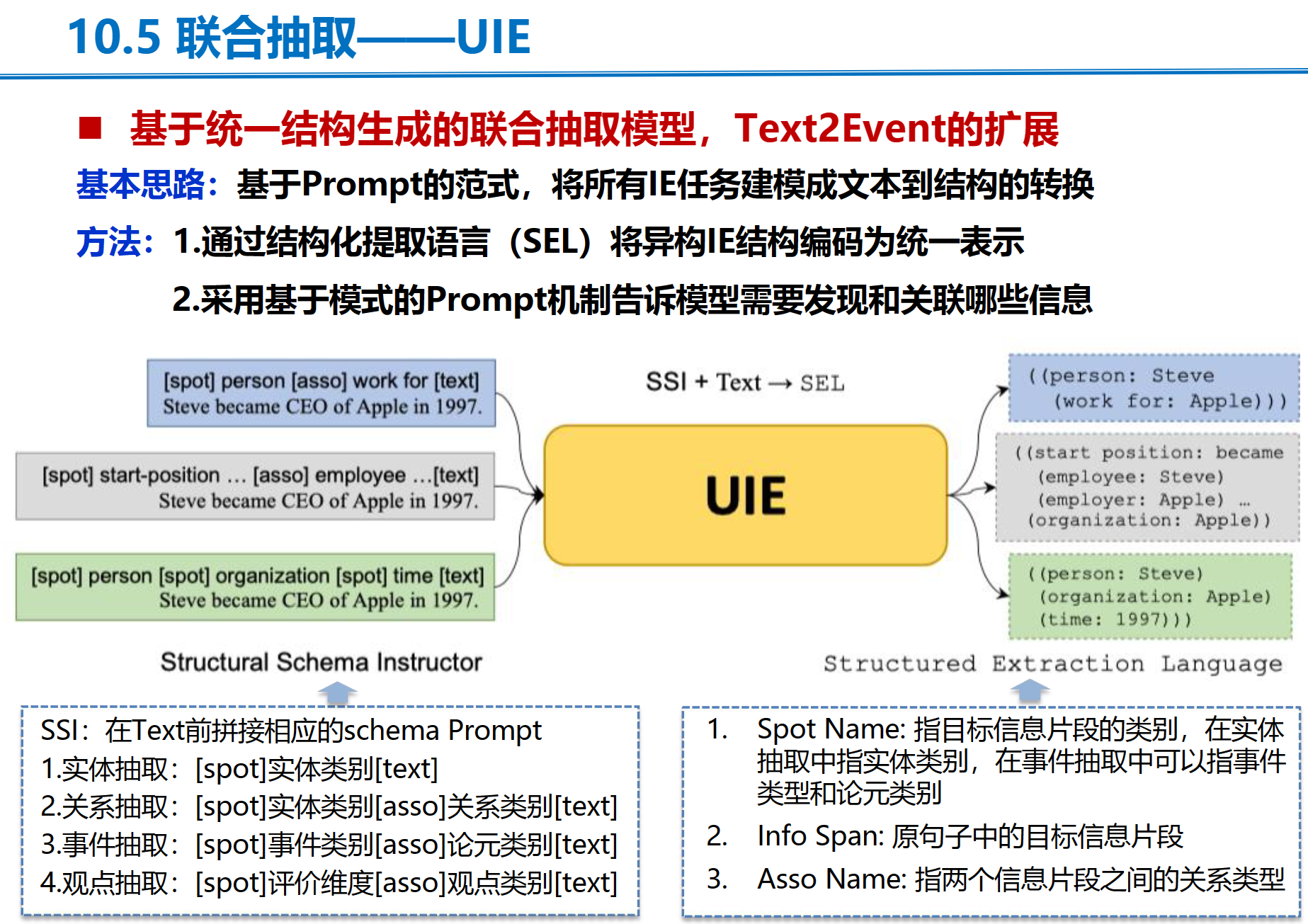
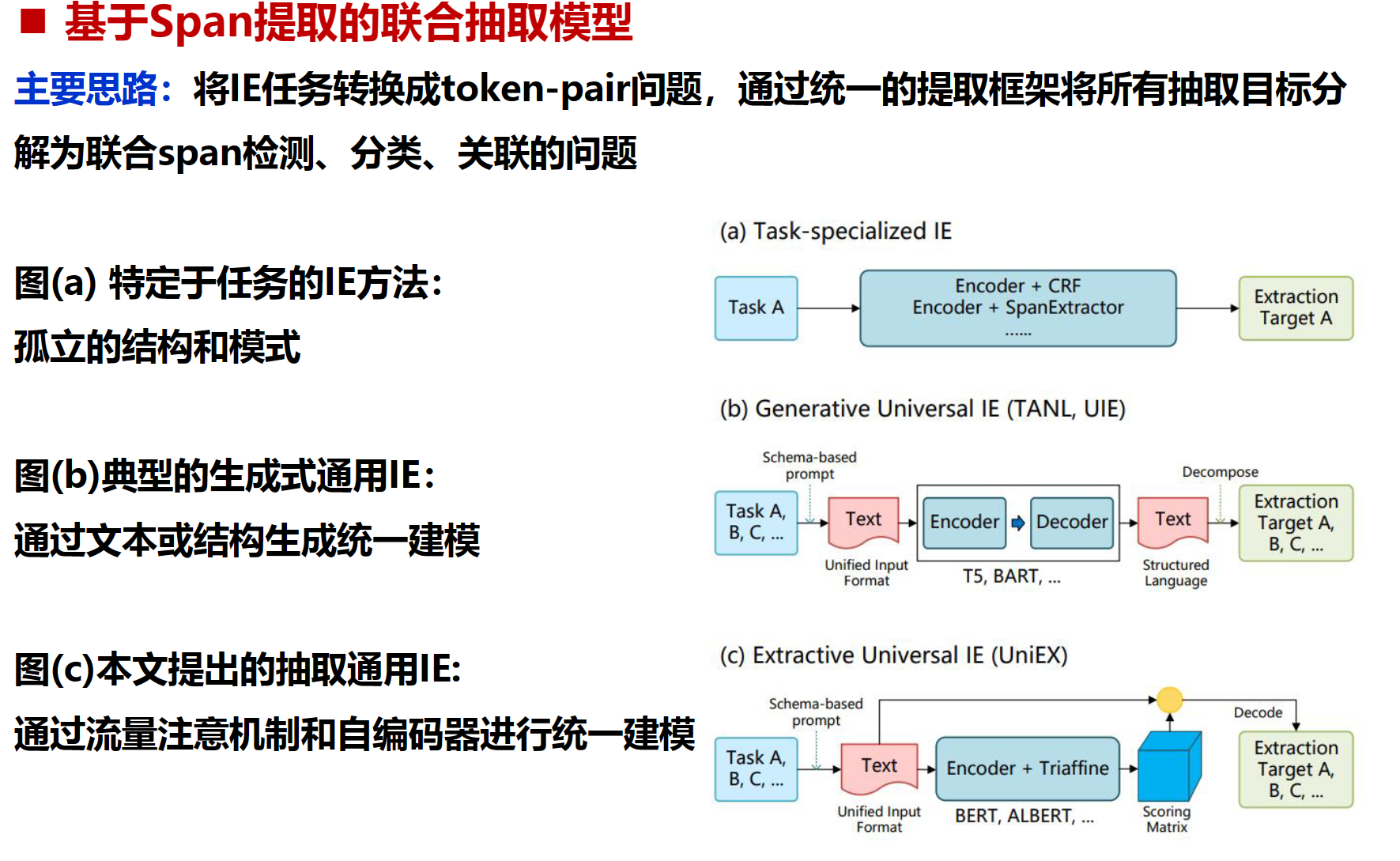
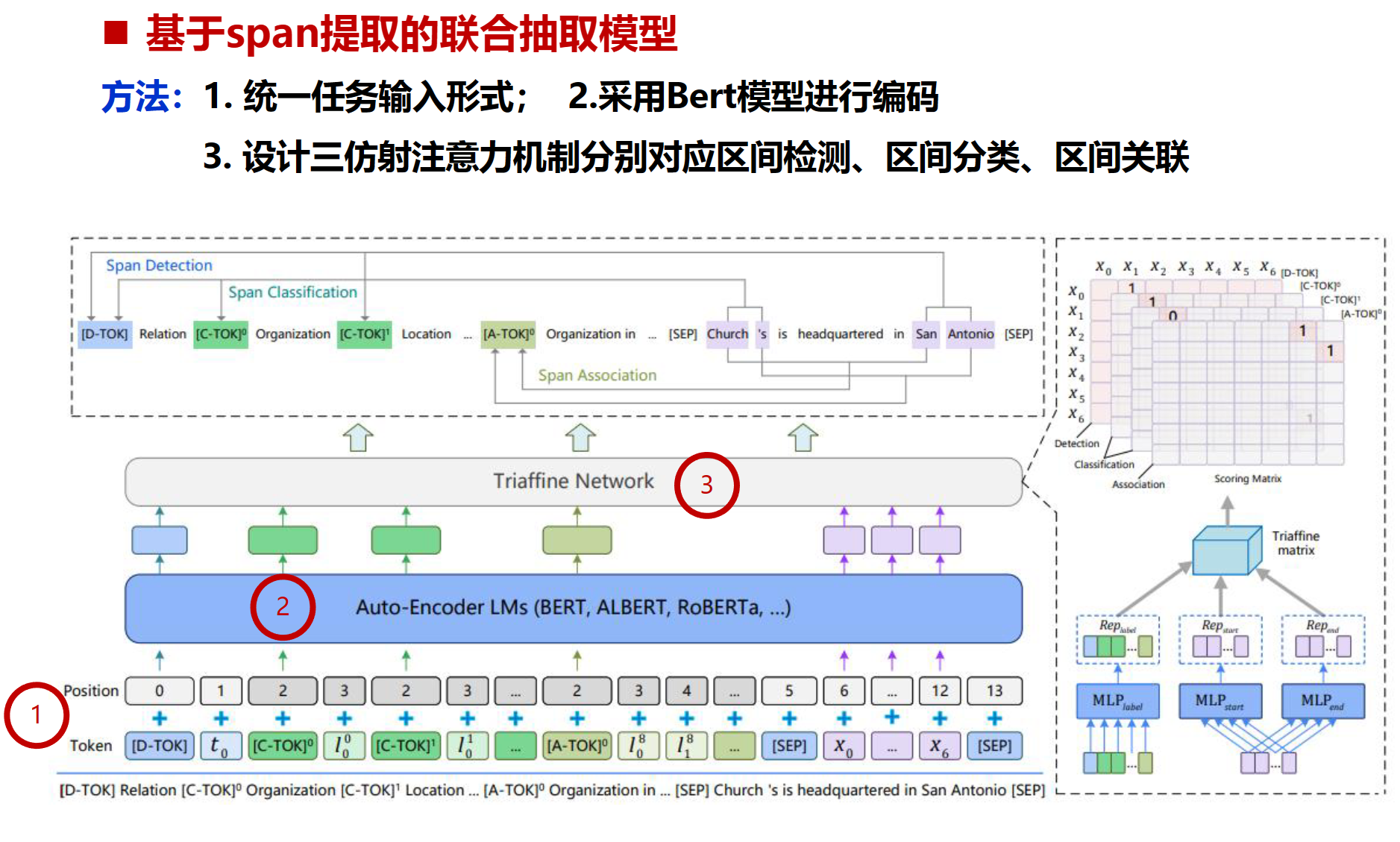
UniEX
检索式问答系统
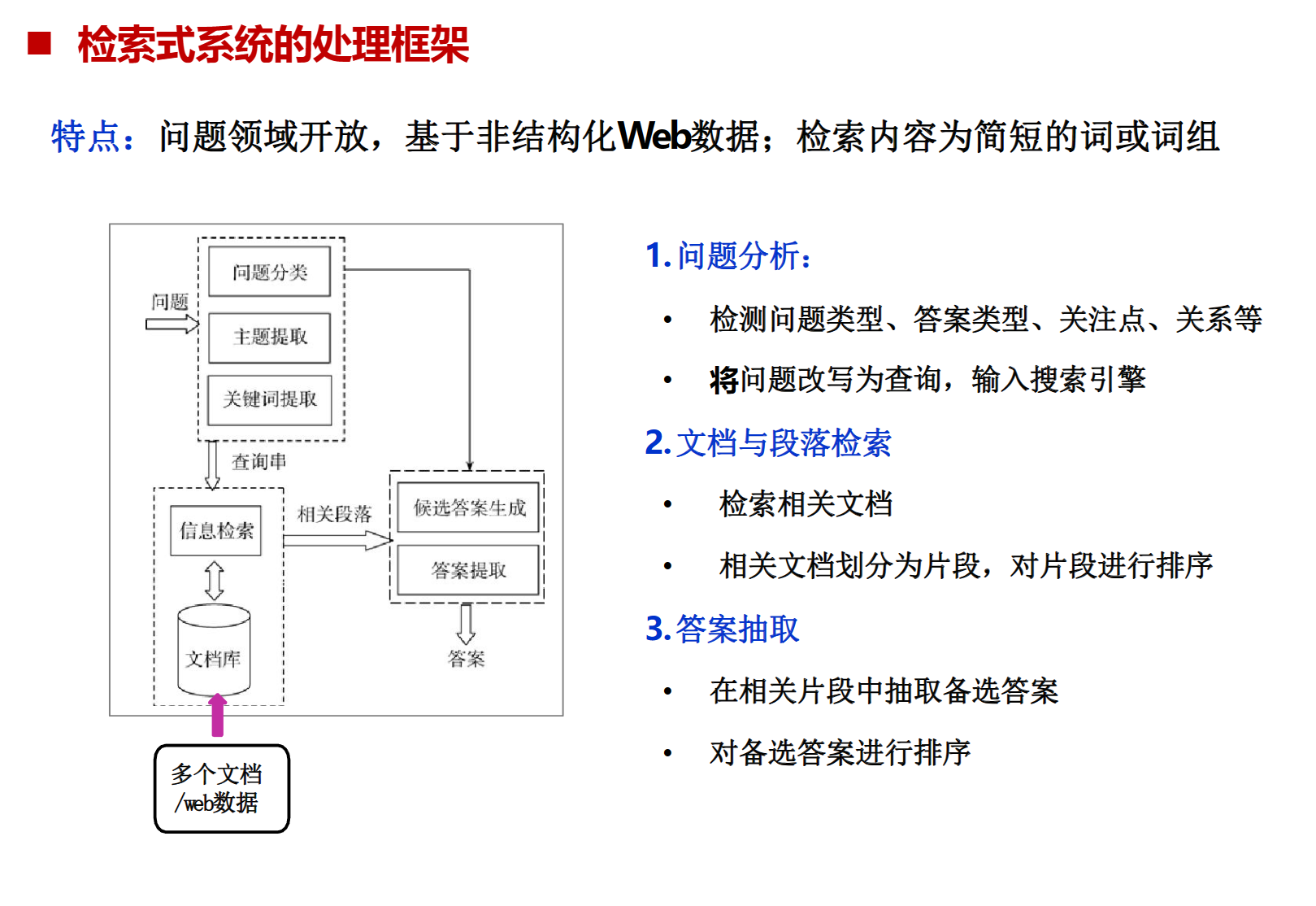
1、问题分析模块:问题分类和关键词提取
问题分类:

关键词提取:根据问题分类,用序列标注法抽取相应类别的实体做为检索关键词
2、检索模块:检索问题答案所在文档与段落
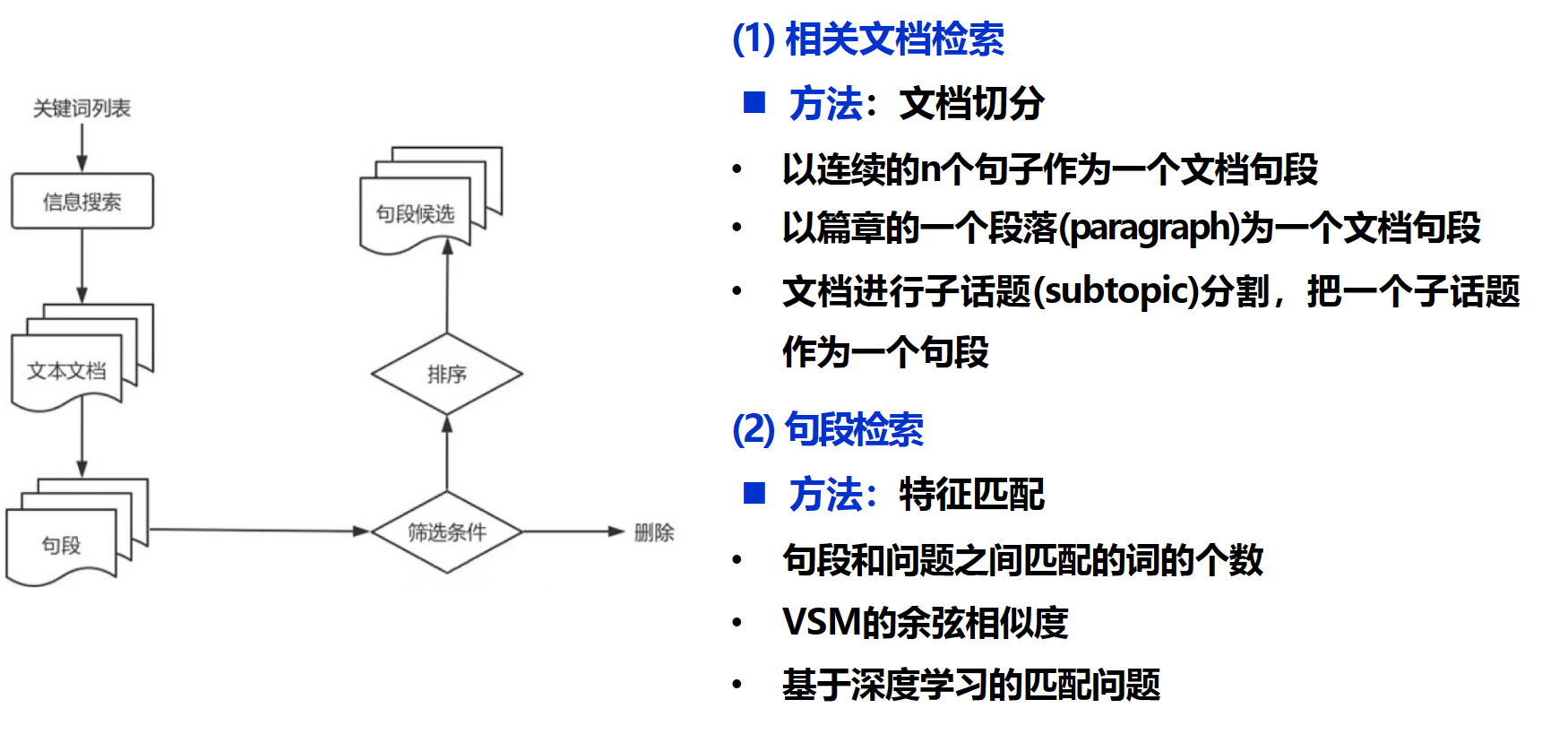
3、 答案抽取模块:在相关片段中抽取备选答案,并对备选答案进行排序

实现方法:
流水线方式
Document Retriever + Reading Comprehension Reader框架
DrQA
TF-IDF:(Term Frequency-Inverse Document Frequency,词频-逆文件频率)是一种用于信息检索和数据挖掘的常用加权技术。它是一种统计方法,用以评估一字词对于一个文件集或一个语料库中的其中一份文件的重要程度

使用TF-IDF获取与问题topK相关的文档

然后将对topK使用抽取式阅读理解,从原文中抽取出可以回答的文本
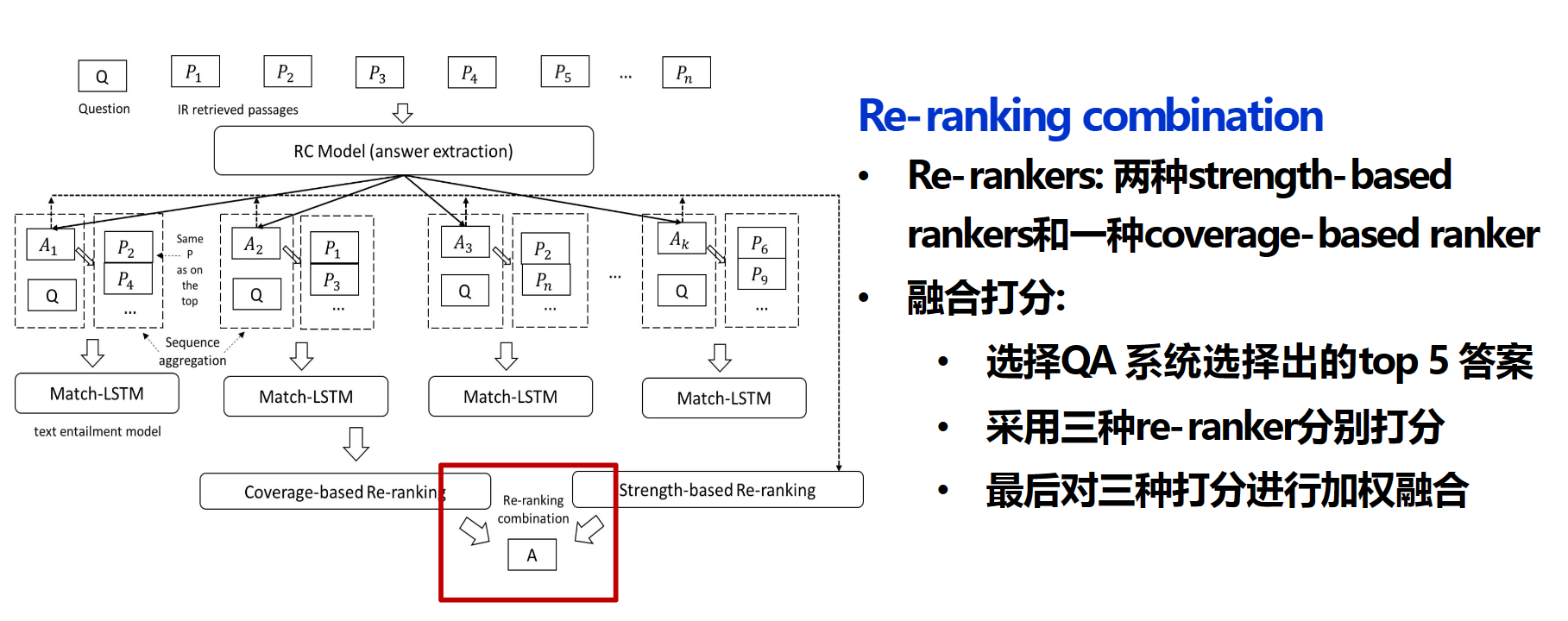
Evidence Aggregation for Answer Re-Ranking in Open-Domain Question Answering
有些问题需要来自不同来源的证据相结合才能正确回答。解决方法:strength-based re-ranker&coverage-based re-ranker
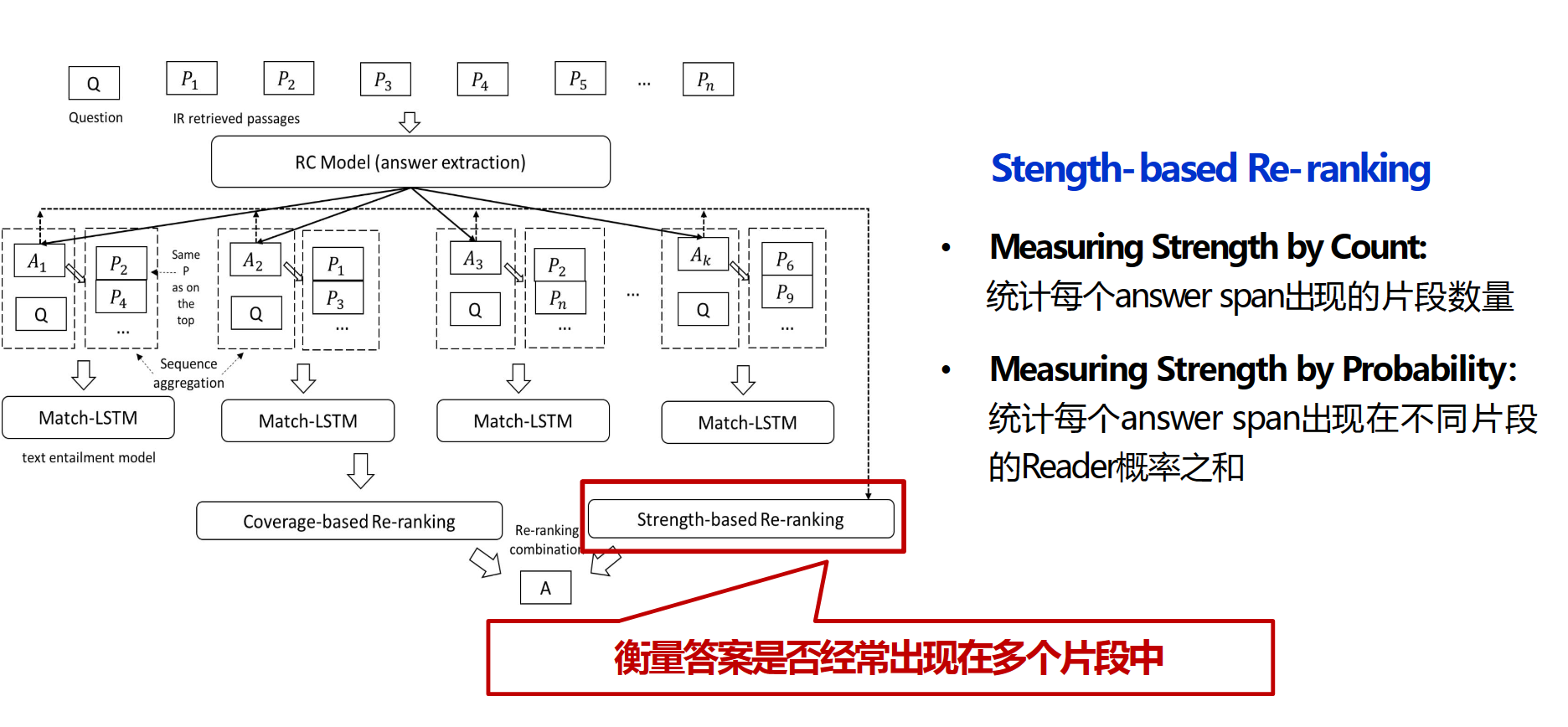
strength-based re-ranker的基本思想是,正确的答案通常会被更多的段落反复提及
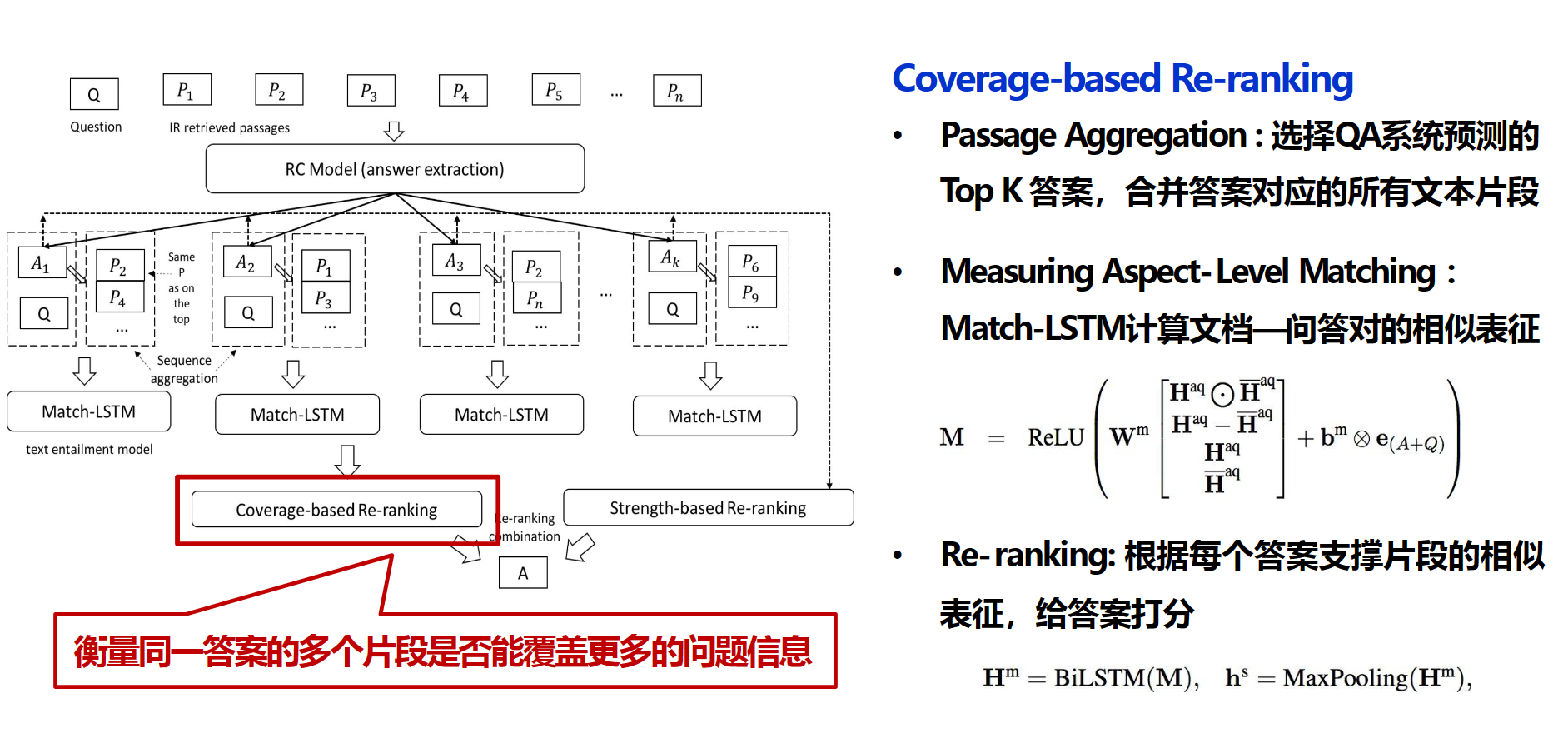
coverage-based re-ranker考虑每个答案在覆盖不同证据方面的能力,这里用一个BiLSTM来计算答案支撑片段的相似表征【指一个答案和它的支撑片段在表征空间中的相似度】,在垮文本上的相似表征很很高说明这个答案更可靠

端到端方式
Retriever-Reader的联合学习
ORQA: Open-Retriever Question Answering
问题引入:
1)需要具有强监督的支持证据:监督数据难以获得
2)利用IR(信息检索)系统检索候选证据:QA与IR存在一定差异性,IR更关注词法或语义相似性,QA对于语言理解层次更丰富
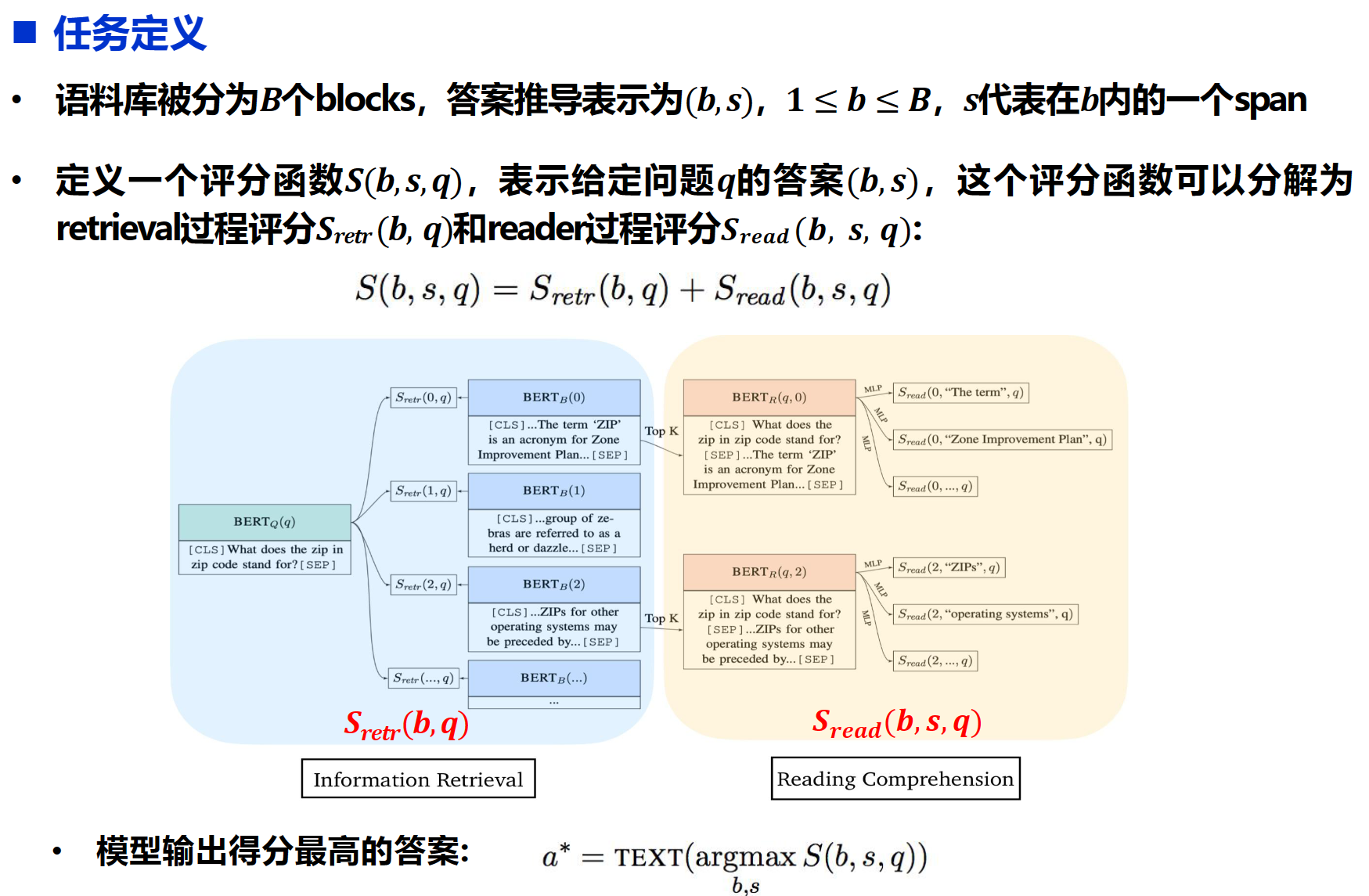
就是一个S是打分函数。评价retrieval和评价reader是两个不同的,$s_{retr}$是评价这个block和问题的相关性的,$S_{read}$是评价块儿里的文本和q的相关性的。这个里面的bert是用来理解retrieval和question的。
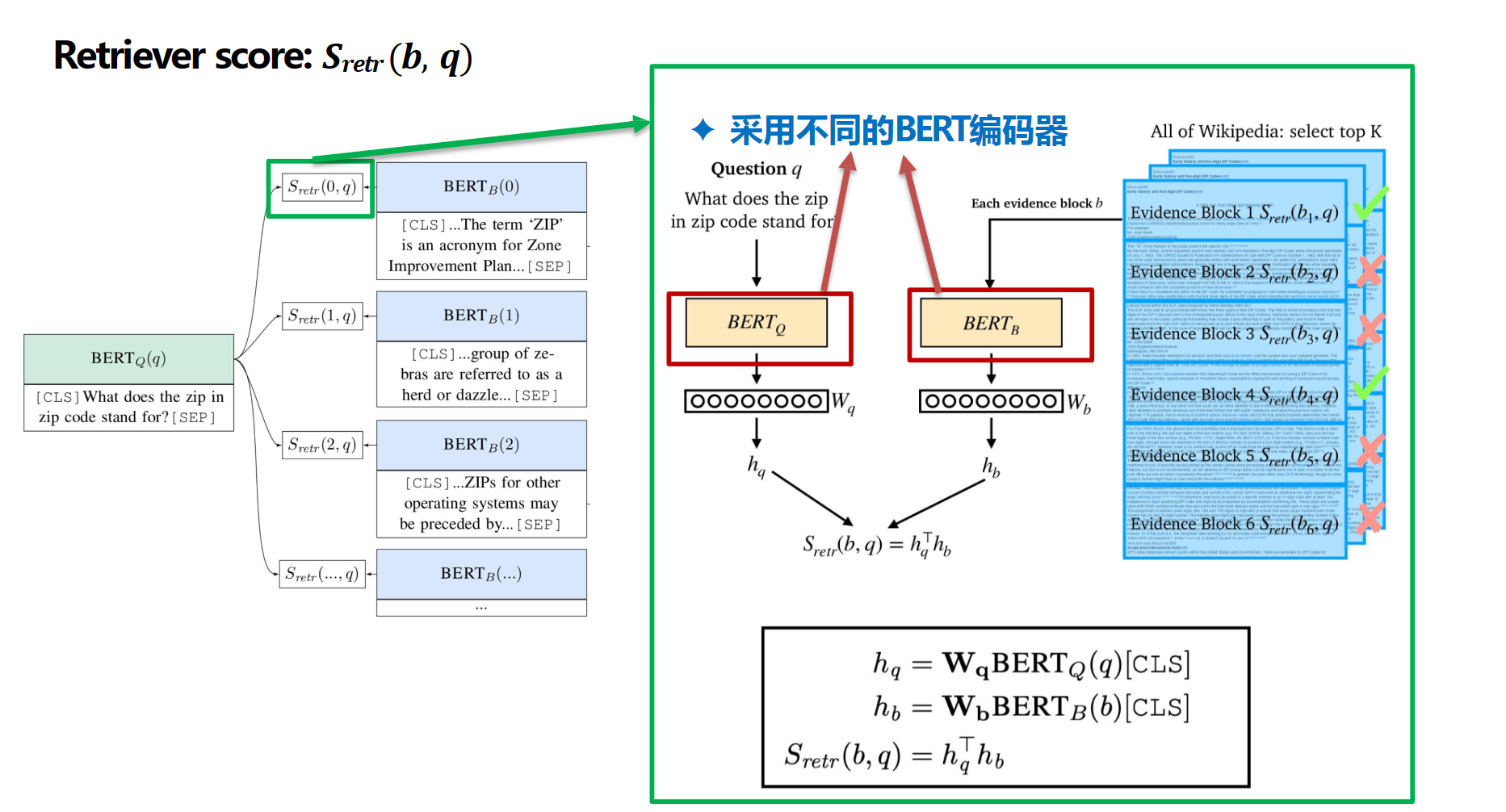
每个块通过BERT和权重矩阵b生成隐藏向量h,问题通过BERT和权重矩阵q生成隐藏向量h,通过点积判断相关性
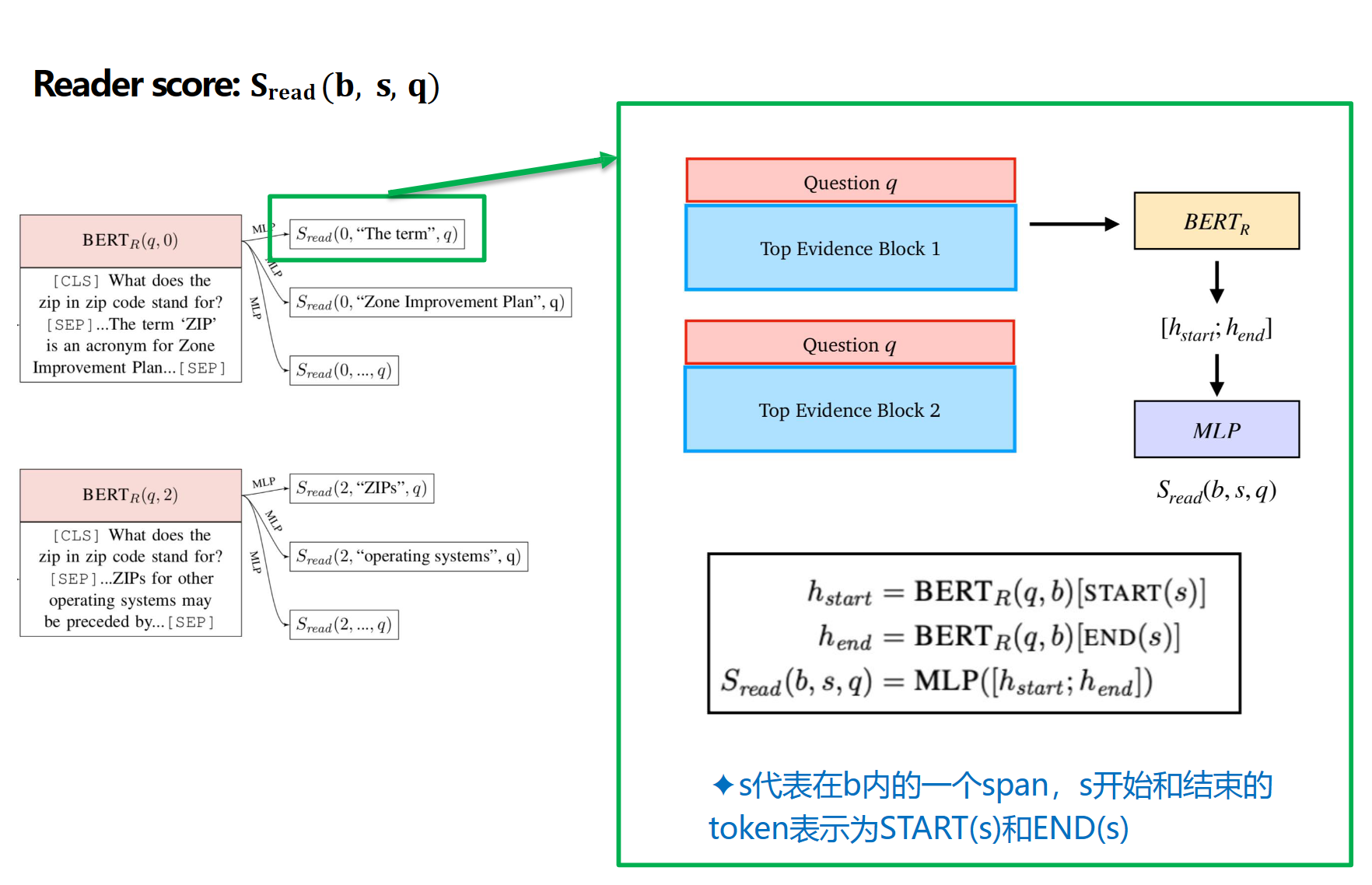
BERT_R+MLP生成s,给S_read来评分
有监督训练,需要手标与a有关的s

有挑战,但是懒得管了
基于预训练的Retriever-Free方法
对预训练模型进行微调,使其能够在没有任何外部上下文或知识的情况下回答问题
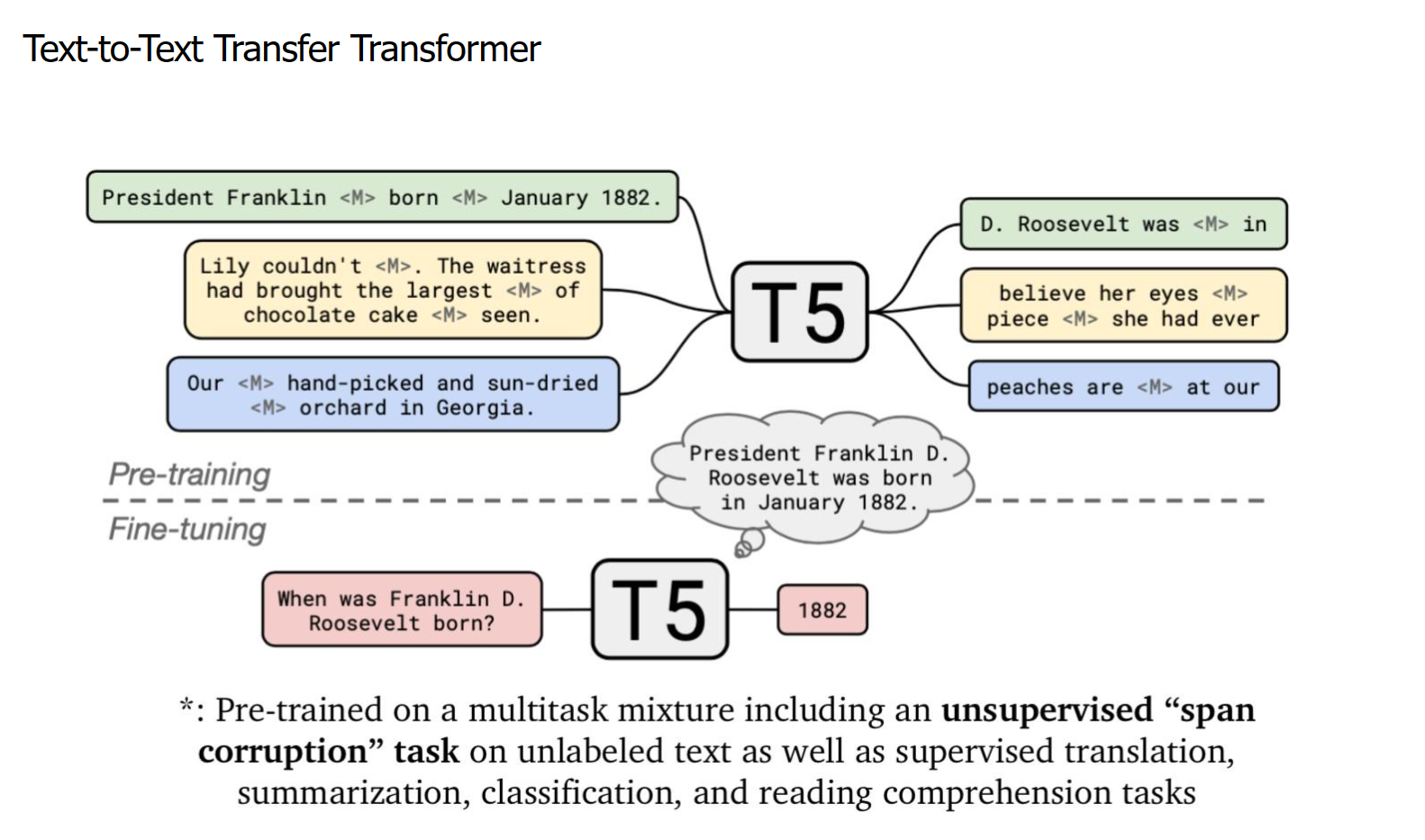
使用span corruption来预训练
Span Corruption是T5模型预训练任务中的一种方法。它将完整的句子根据随机的span进行掩码。例如,原句:“Thank you for inviting me to your party last week”,Span Corruption之后可能得到输入:“Thank you [X] me to your party [Y] week”,目标:“[X] for inviting [Y] last [Z]”。其中[X]等一系列辅助编码称为sentinels。
这种方法的目标是让模型学习如何从被打乱或被掩码的句子中恢复出原始的句子。

LLM在问答任务上与有监督微调效果不相上下
LLM在计数、多跳推理、日期、因果等类型上的性能较弱
最后一节课
讲了一节课的对话系统(不考)
参考:https://blog.csdn.net/ld326/article/details/112802292