导语
doi is here
Abstract
问题引入
目前互联网上的流量已被广泛加密,同时流量加密总是被攻击者滥用以隐藏其恶意行为,现有的加密恶意流量检测方法受到监督,它们依赖于已知攻击(例如,标记数据集)的先验知识。
提出方法
提出了HyperVision,一种基于实时无监督机器学习的恶意流量检测系统。
- 能够利用基于流量模式构建的紧凑内存图来检测加密恶意流量的未知模式。该图捕获由图结构特征表示的流交互模式,而不是特定已知攻击的特征。
- 我们开发了一种无监督图学习方法,通过分析图的连接性、稀疏性和统计特征来检测异常交互模式
- 建立了一个信息论模型来证明图保存的信息接近理想的理论边界。
Introduction
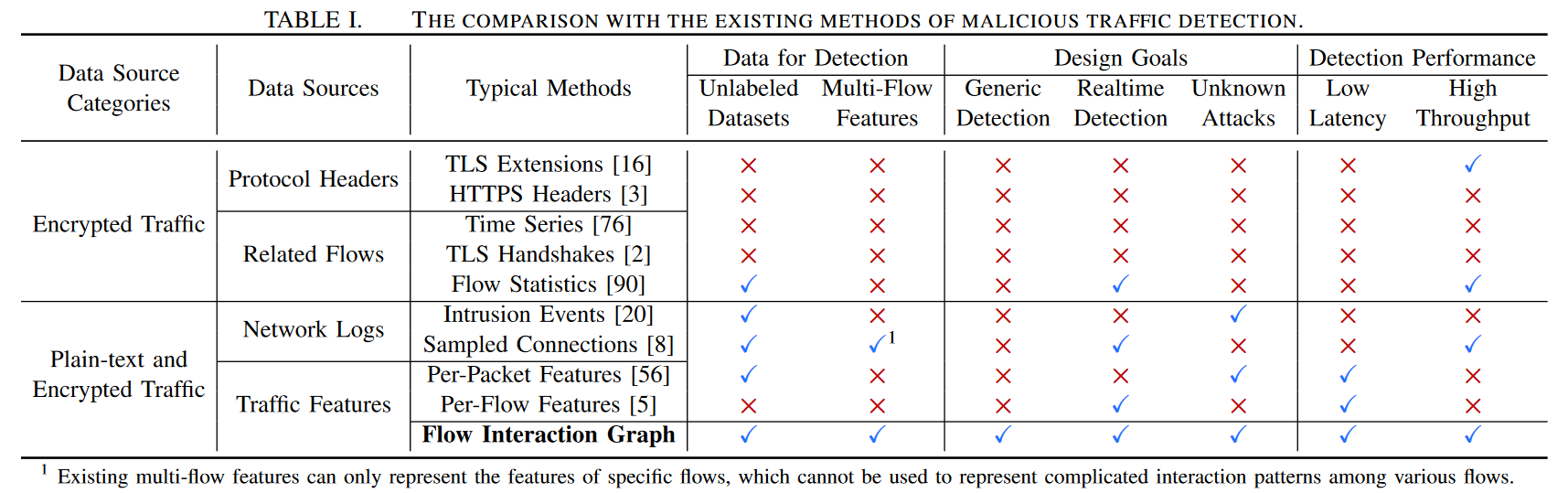
现有方法
深度数据包检测(DPI)的传统基于签名的方法在加密有效载荷的攻击下无效,加密流量具有与良性流量相似的特征,因此也可以逃避现有的基于机器学习。特别是,现有的加密流量检测方法受到监督,即依赖于已知攻击的先验知识,并且只能检测具有已知流量模式的攻击。此外,这些方法无法检测使用和不使用加密流量构建的攻击,并且由于加密和非加密攻击流量的特征显着不同,因此无法实现通用检测
简而言之,现有方法无法实现无监督检测,也无法检测具有未知模式的加密恶意流量。特别是,加密的恶意流量具有隐蔽行为,这些方法无法捕获这些行为,这些方法根据单个流的模式检测攻击。但是,检测此类攻击流量仍然是可行的,因为即使攻击的单个流与良性攻击流相似,这些攻击涉及攻击者和受害者之间具有不同流交互的多个攻击步骤与良性流交互模式不同。
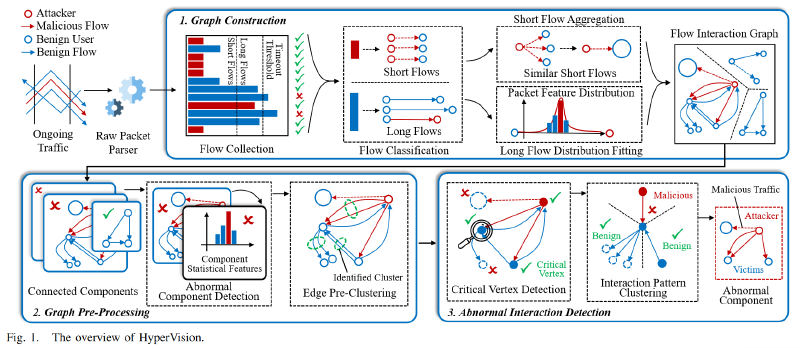
HyperVision,这是一个实时检测系统,旨在通过分析流之间的交互模式来捕获加密恶意流量的足迹。特别是,它可以通过识别异常流交互(即不同于良性的交互模式)来检测具有未知足迹的加密恶意流。
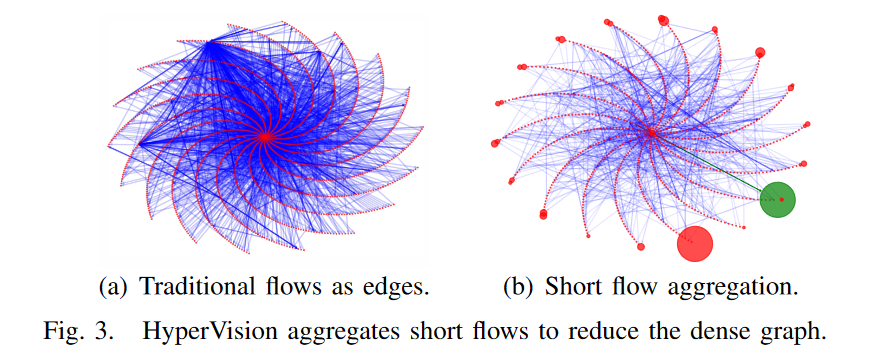
但是,构建用于实时检测的图形具有挑战性。我们不能简单地使用 IP 地址作为顶点,而传统的四元组流(源目的ip,源目的port)作为边来构建图,因为生成的密集图无法维持各种流之间的交互模式,例如,引起依赖爆炸问题 。
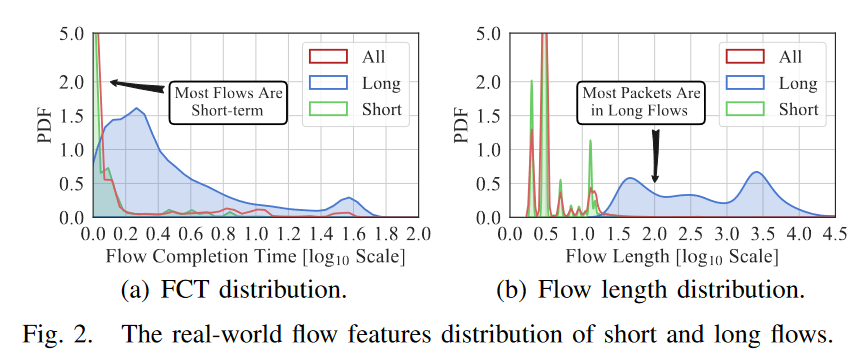
收到流量尺寸分布的研究的启发,互联网上的大多数流都是短流,而大多数数据包与长流相关联,我们利用两种策略来记录不同大小的流,并在图中分别处理短流和长流的交互模式。
我们设计了一种四步 轻量级 无监督 图学习方法,通过利用图上维护的丰富流交互信息来检测加密的恶意流量。
- 首先,我们通过提取连通分量来分析图的连通性,并通过对高层次统计特征进行聚类来识别异常分量。通过排除良性分量,我们还显著减少了学习开销。
- 其次,我们根据在边特征中观察到的局部邻接关系对边进行预聚类。预聚类操作显著降低了特征处理开销,并确保了实时检测。
- 第三,我们使用Z3 SMT solver求解顶点覆盖问题来提取关键顶点,以最大程度地减少聚类的数量。
- 最后,根据每个临界顶点的连接边进行聚类,这些边位于预聚类产生的簇的中心,从而得到指示加密恶意流量的异常边。
此外,为了量化HyperVision基于图的流量记录相对于现有方法的优势,我们开发了一个流量记录熵模型,这是一个基于信息论的框架,从理论上分析恶意流量检测系统的现有数据源保留的信息量。这个框架表明NetFlow [19]和Zeek [86]无法保留高保真流量信息,而HyperVision中的图捕获了接近最优的流量信息,并且图中维护的信息量接近理想化数据源的理论上界。(这么屌啊?)此外,分析结果表明,HyperVision中的图形实现了比所有现有数据源更高的信息密度(即每单位存储的流量信息量),这是准确高效检测的基础。
过两天读R. Zamir, “A proof of the fisher information inequality via a data processing argument,” IEEE Trans. Inf. Theory, vol. 44, no. 3, pp. 12461250, 1998.
平台和数据集
我们使用英特尔的数据平面开发套件 (DPDK) [37] 对 HyperVision进行原型设计。为了广泛评估原型的性能,我们重放了92个攻击数据集,其中包括在我们的虚拟私有云 (VPC)中收集的80个新数据集,其中包含 1,500 多个实例。在 VPC 中,我们收集了 48 个典型的加密恶意流量,包括 (i) 加密泛洪流量,例如泛洪目标链路 [41];(ii) 网络攻击,例如利用网络漏洞 [64];(iii) 恶意软件活动,包括连接测试、依赖项更新和下载。
此外,HyperVision 的平均检测吞吐量超过 100 Gb/s,平均检测延迟为 0.83 秒。
省流
• 我们提出了 HyperVision,这是首个使用流交互图实现对未知模式的加密恶意流量进行实时无监督检测的方法。 • 我们开发了多种算法来构建内存中的图,使我们能够准确捕获不同流之间的交互模式。 • 我们设计了一种轻量级的无监督图形学习方法,通过图形特征来检测加密流量。 • 我们开发了一个由信息论建立的理论分析框架,以展示该图形捕获了接近最优的流量交互信息。 • 我们原型化了 HyperVision,并进行了广泛的实验,使用各种真实世界的加密恶意流量来验证其准确性和效率。
名词解释
连通分量:在图论中,连通分量是一个图中的一个子图,其中任意两个顶点都可以通过边相连的路径相互访问。
Z3 SMT solver:3(Z3 SMT solver)是由微软研究院开发的一个高性能的SMT(Satisfiability Modulo Theories)求解器。SMT 求解器是一种自动化工具,用于解决布尔公式、一阶逻辑公式和其他数学理论的判定问题。Z3 在各种计算机科学和工程领域都有广泛的应用,包括软件验证、形式化方法、人工智能、编译器优化和硬件验证等。
英特尔的数据平面开发套件 (DPDK):旨在优化数据包处理性能。它专注于高性能网络应用程序和数据平面开发,使开发人员能够在通用服务器硬件上实现高吞吐量和低延迟的数据包处理。它通过绕过操作系统内核,并在用户空间中实现网络协议栈,从而提供极低的延迟和高吞吐量。支持多核处理器,允许并行处理大量数据包。利用支持硬件加速的网络接口卡(NIC)来进一步提高性能。DPDK 是一个开源项目,开发人员可以根据其需求进行自定义和扩展。DPDK 通常用于构建高性能网络应用程序,如网络功能虚拟化(NFV)、防火墙、负载均衡、数据包过滤和路由等。它还用于云计算、边缘计算和网络设备。
HyperVision
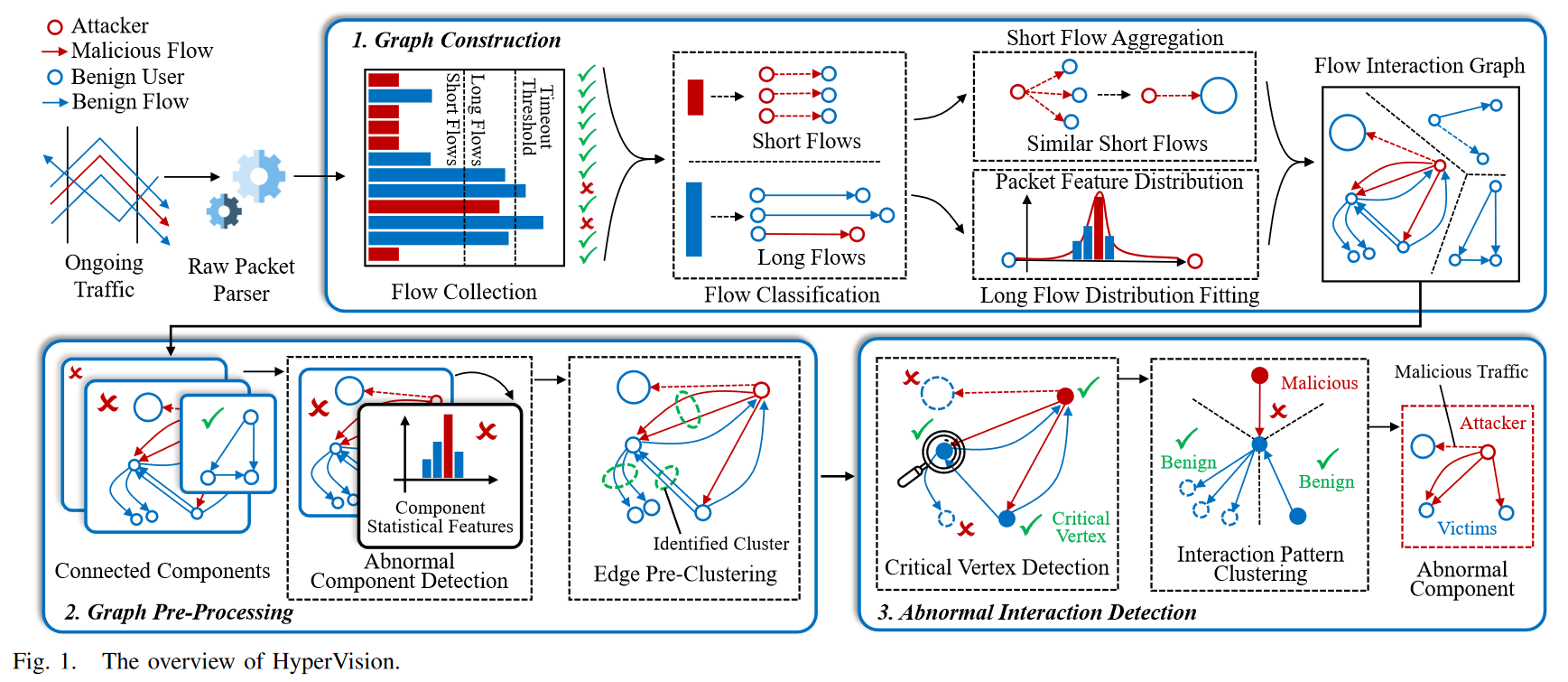
首先HyperVision以镜像来的路由器流量作为输入,确保不会干扰流量转发。在识别加密的恶意流量后,它可以与现有的中间恶意流量防御配合,以限制检测到的流量。重点检测使用加密流量构建的主动攻击。不考虑不会为受害者带来流量的被动攻击,例如流量窃听和被动流量分析
HyperVision的设计目标如下:首先,它应该能够实现通用检测,即检测使用加密或非加密流量构建的攻击,从而确保攻击无法逃避流量加密的检测。其次,它能够实现实时高速流量处理,这意味着它可以识别通过加密流量是否是恶意的,同时产生低检测延迟。第三,HyperVision 执行的检测是不受监督的,这意味着它不需要任何加密恶意流量的先验知识。
图构造
将流分为短流和长流,并分别记录它们的相互作用模式,以降低图的密度。
使用不同的地址作为顶点,分别连接与短流和长流关联的边。聚合大量相似的短流,为一组短流构建一条边,从而减少维护流交互模式的开销。拟合长流中数据包特征的分布,构建与长流相关的边缘,从而保证了高保真记录的流交互模式,同时解决了传统方法中粗粒度流特征的问题。
预处理图
通过提取连通分量来减少图的开销,并使用高级统计信息进行聚类。其中,聚类可以准确地检测出只有良性交互模式的组件,从而对这些良性组件进行过滤,减小图的规模。此外,我们进行了预聚类,并使用生成的聚类中心来表示图像中的识别的集群的边缘。(第五节详细讲)
基于图的恶意流量检测
通过分析图特征来实现无监督加密恶意流量检测。
图构造
流的分类
为了避免图构建过程中流之间的依赖爆炸,把流分成长流和短流,并且降低密度。下图显示了显示了2020年1月MAWI互联网流量数据集的流完成时间和流长度的分布,纵轴PDF是概率密度函数,可以看到不论是长流还是短流都在分布短时间、长长度更多。
 利用短流合并后,图的稠密度显著下降
利用短流合并后,图的稠密度显著下降
获取每个数据包的信息,并获取其源、目标地址、端口号和每个数据包的功能,包括协议、长度和到达间隔。我们开发了一种流量分类算法来对流量进行分类(附录A中的算法1)简单来说就是维护一个哈希表,键是hash(src,dest,src_post,dest_port),值是流的所有数据包特征的序列(协议、数据包长度、到达间隔),然后用一个定时器TIME_NOW,每隔JUDGE_INTERVAL检查一下,如果在这个interval里流发了多个数据包,就算他是长流,否则就说他是短流)【q,这个interval怎么设置?为什么后面说ssh暴力破解都是短流?这不是应该是短期发好多包吗?】
短流聚合
我们观察到,大多数短流具有几乎相同的每个数据包的特征序列。我们设计了一种聚合短流的算法(附录A中的算法2)。当满足以下所有要求时,可以聚合一组流
- 流具有相同的源和/或目标地址(为啥不是哈希表的键值一样)
- 流具有相同的协议类型
- 流的数量足够大,即当短流量的数量达到阈值AGG_LINE
我们为短流构建一条边,为所有流及其四个元组保留一个特征序列(即协议、数据包长度和到达间隔)
长流的特征分布拟合
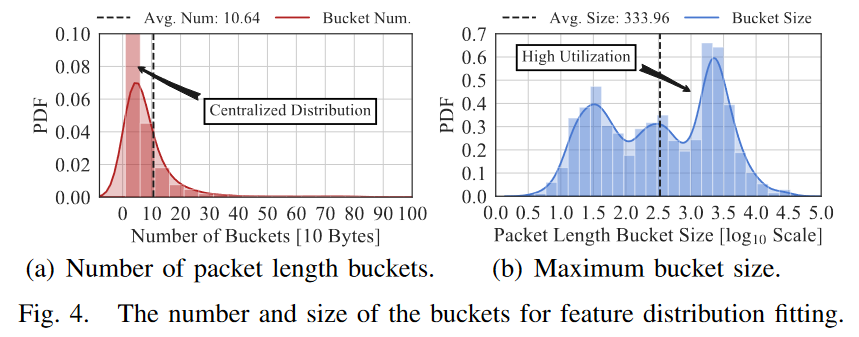
由于长流中的特征是集中分布的,我们使用直方图来表示长流中每个数据包特征的频率分布。直方图的每个条目表示一个数据包特征的频率,从而避免保留其长的每个数据包特征序列。具体来说,我们为每个长流中的每个数据包特征序列构建直方图,然后维护一个哈希表, 键为数据包特征序列,值为直方图。我们将数据包长度和到达间隔的桶宽度分别设置为 10 字节和 1 毫秒,以在拟合精度和开销之间进行权衡。
下图显示了数据集中的长流中已用桶的数量和最大桶的大小,可以看是集中分布的,即长流中的大多数数据包具有相似的包长度和到达间隔。长度拟合平均用11个桶,每个桶平均200个数据包;到达间隔拟合平均用121个桶,每个桶平均71个数据包。